
Os métodos de autocorreção tornaram-se um importante tópico de interesse entre a inteligência artificial, especialmente para modelos de linguagem em larga escala (LLMs). A higiene é tradicionalmente vista como uma característica humana única. No entanto, os investigadores começaram a investigar como pode ser usado em LLMs para melhorar as suas competências sem exigir contribuições externas. Esta área emergente explora formas de permitir que os LLMs avaliem e refinem as suas respostas, tornando-os mais independentes e eficientes na compreensão de tarefas complexas e na geração de respostas adequadas ao contexto.
Os investigadores pretendem abordar uma questão importante: a dependência dos LLMs de críticos externos e de supervisão pré-definida para melhorar a qualidade da resposta. Os modelos convencionais, embora poderosos, muitas vezes dependem de feedback humano ou de testadores externos para corrigir erros no conteúdo gerado. Esta dependência limita a sua capacidade de se desenvolverem e trabalharem de forma independente. Uma compreensão completa de como os LLMs podem corrigir automaticamente seus erros é fundamental para a construção de sistemas mais avançados que possam operar sem validação externa contínua. Obter essa compreensão pode revolucionar a forma como os modelos de IA aprendem e melhoram.
Muitos métodos neste campo incluem Aprendizado por Reforço com Feedback Humano (RLHF) ou Otimização de Preferência Direta (DPO). Esses métodos geralmente incluem críticos externos ou dados de preferência pessoal para orientar os LLMs no refinamento de suas respostas. Por exemplo, no RLHF, o modelo recebe feedback das pessoas sobre as respostas geradas e utiliza esse feedback para ajustar os resultados subsequentes. Embora estes métodos sejam bem sucedidos, eles não permitem que os modelos melhorem o seu comportamento automaticamente. Este aspecto apresenta um desafio no desenvolvimento de LLMs que possam identificar e corrigir seus erros de forma independente, exigindo assim novas formas de desenvolver habilidades de autocorreção.
Pesquisadores do MIT CSAIL, da Universidade de Pequim e da TU Munique apresentaram uma nova estrutura teórica baseada no alinhamento de análise de conteúdo (ICA). O estudo sugere um processo estruturado no qual os LLMs utilizam mecanismos internos para autocrítica e refinamento de respostas. Ao adotar uma abordagem de geração iterativa, o modelo começa com uma resposta inicial, avalia seu desempenho interno usando uma métrica de recompensa e então gera uma resposta melhorada. O processo se repete até que a saída atinja o nível máximo de alinhamento. Este método converte o contexto tradicional (pergunta, resposta) em um formato triplo complexo (pergunta, resposta, recompensa). A investigação argumenta que tal estrutura ajuda os modelos a testarem-se e a alinharem-se de forma eficaz, sem exigir orientação predefinida dirigida por humanos.
Os pesquisadores usaram uma arquitetura de transformador multicamadas para implementar o método de auto-retificação proposto. Cada camada consiste em módulos de rede com múltiplos cabeçotes e módulos de rede que permitem ao modelo distinguir entre respostas positivas e negativas. Especificamente, a arquitetura foi projetada para permitir que LLMs executem descida gradiente com aprendizagem no contexto, permitindo uma compreensão dinâmica e dinâmica das funções de alinhamento. Através de testes de dados sintéticos, os pesquisadores confirmaram que os transformadores podem realmente aprender com resultados ruidosos quando guiados por críticos precisos. As contribuições teóricas da pesquisa também esclareceram a importância de algumas partes da arquitetura, como a atenção softmax e as redes de encaminhamento, para permitir o alinhamento eficiente de conteúdo, estabelecendo um novo padrão para arquiteturas baseadas em transformadores.
Os testes de desempenho revelaram melhorias significativas em vários cenários de teste. O método de autocorreção reduziu significativamente as taxas de erro e melhorou o alinhamento nos LLMs, mesmo em casos envolvendo feedback ruidoso. Por exemplo, o método proposto mostrou uma redução significativa nas taxas de sucesso de ataques durante os testes de jailbreak, com a taxa de sucesso caindo de 95% para até 1% em alguns casos usando LLMs como Vicuna-7b e Llama2-7b-chat. Os resultados mostraram que os métodos de autocorreção podem proteger contra ataques complexos de jailbreak, como GCG-individual, GCG-transfer e AutoDAN. Este forte desempenho sugere que os LLMs de autocorreção têm o potencial de fornecer maior segurança e robustez em aplicações do mundo real.
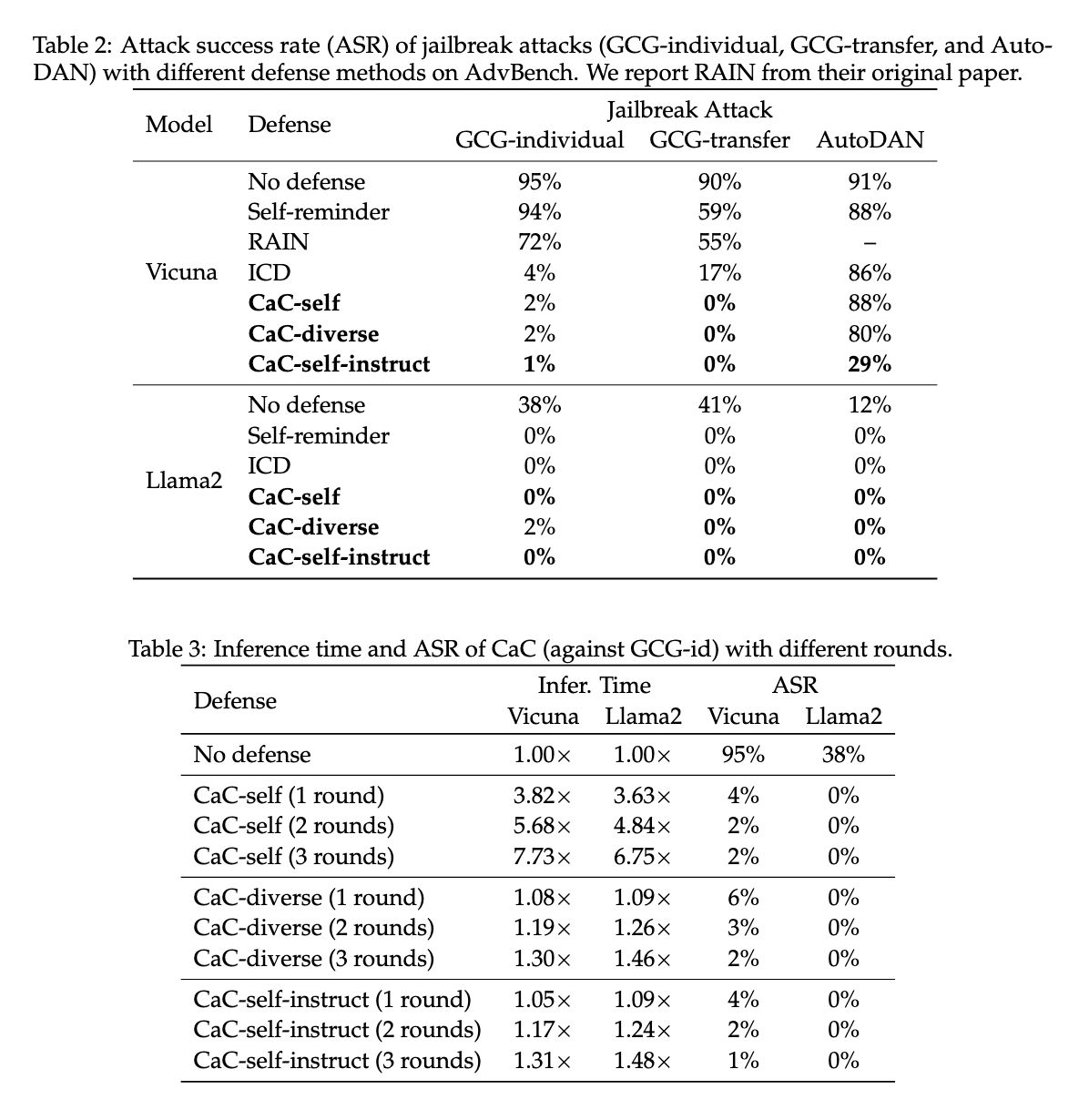
O método de autocorreção proposto também está muito avançado na avaliação de preconceitos sociais. Quando aplicado ao conjunto de dados Bias Benchmark for QA (BBQ), que avalia o preconceito em nove características sociais, o método obteve ganhos de desempenho em categorias como gênero, raça e status socioeconômico. O estudo mostrou uma taxa de sucesso de ataque de 0% em vários fatores de preconceito usando o Llama2-7b-chat, comprovando a eficácia do modelo em manter a compreensão mesmo em situações sociais complexas.
Concluindo, este estudo fornece um método básico de autocorreção para LLMs, enfatizando a capacidade dos modelos de refinar automaticamente seus resultados sem depender de feedback externo. O novo uso de alinhamento de conteúdo e arquiteturas transformadoras multicamadas mostra um caminho claro para o desenvolvimento de modelos de linguagem independentes e inteligentes. Ao permitir que os LLMs se auto-testem e melhorem, a investigação abre caminho para a criação de sistemas de IA robustos, seguros e sensíveis ao contexto que podem lidar com tarefas complexas com o mínimo de intervenção humana. Este progresso pode melhorar significativamente a concepção e utilização futuras de LLMs numa variedade de domínios, estabelecendo as bases para modelos que não só aprendem, mas também evoluem de forma independente.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit.
Convidamos startups, empresas e institutos de pesquisa que trabalham em modelos de microlinguagem para participar deste próximo projeto Revista/Relatório 'Modelos de Linguagem Pequena' Marketchpost.com. Esta revista/relatório será lançada no final de outubro/início de novembro de 2024. Clique aqui para agendar uma chamada!
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.


: uma família multilíngue de última geração para preencher a lacuna linguística na IA")