
Os modelos de linguagem visual (VLMs) desempenham um papel importante em tarefas multimodais, como recuperação de imagens, visualização e diagnóstico médico, por meio da manipulação de dados visuais e linguísticos. Contudo, compreender a negação nestes modelos ainda é um dos maiores desafios. A indiferença é importante em diferentes sistemas, como distinguir um “quarto sem janelas” de um “quarto com janelas”. Apesar dos seus avanços, os VLMs atuais não conseguem interpretar a negação de forma confiável, limitando enormemente o seu desempenho em domínios avançados, como monitoramento de segurança e saúde. Enfrentar este desafio é importante para estender a sua aplicabilidade a situações do mundo real.
Os VLMs atuais, como o CLIP, usam espaços de incorporação compartilhados para alinhar representações visuais e textuais. Embora esses modelos tenham um desempenho muito bom em tarefas como recuperação de caminho cruzado e legendagem de imagens, seu desempenho cai significativamente quando se trata de declarações negativas. Esta limitação surge devido ao viés de dados pré-treinamento porque os conjuntos de dados de treinamento contêm principalmente exemplos afirmativos, levando ao viés de confirmação, onde os modelos tratam afirmações negativas e afirmativas como equivalentes. Os benchmarks existentes, como CREPE e CC-Neg, baseiam-se em exemplos de modelos simples que representam a riqueza e a profundidade da negação na linguagem natural. Os VLMs tendem a quebrar a incorporação de legendas negativas e positivas, por isso é muito desafiador distinguir entre os conceitos. Isso cria um problema no uso de VLMs em aplicações de compreensão de linguagem de precisão, por exemplo, consultando bancos de dados de imagens médicas com critérios complexos de inclusão e exclusão.
Para resolver essas limitações, pesquisadores do MIT, do Google DeepMind e da Universidade de Oxford propuseram a estrutura NegBench para testar e melhorar a compreensão da negação com VLMs. A estrutura avalia duas tarefas básicas: Recuperação Negligível (Neg-Retrieval), que testa a capacidade do modelo de recuperar imagens de acordo com significados afirmativos e negativos, como “mar desolado”, e Perguntas Negligíveis de Múltipla Escolha (MCQ-Neg), que avalia a compreensão cognitiva exigindo que os modelos selecionem as legendas apropriadas com a menor variação. Ele usa grandes conjuntos de dados sintéticos, como CC12M-NegCap e CC12M-NegMCQ, aumentados com milhões de legendas contendo uma variedade de condições de negação. Isso exporá os VLMs a anomalias um tanto desafiadoras e rótulos publicados, melhorando o treinamento e os testes do modelo. Conjuntos de dados padrão, como COCO e MSR-VTT, também foram modificados, incluindo denominadores e expressões idiomáticas, para expandir ainda mais a diversidade linguística e testar a robustez. Ao combinar vários e complexos modelos de negação, o NegBench supera com sucesso as limitações existentes, melhorando significativamente o desempenho e a generalização do modelo.
O NegBench usa conjuntos de dados reais e sintéticos para testar a compreensão da negação. Conjuntos de dados como COCO, VOC2007 e CheXpert são modificados para incluir condições de isenção de responsabilidade, como “Esta imagem inclui árvores, mas não edifícios”. Nos MCQs, modelos como “Esta imagem inclui A, mas não B” são usados em conjunto com uma variável definida por palavras diferentes. O NegBench também é complementado com o conjunto de dados HardNeg-Syn, onde as imagens são combinadas para apresentar pares que diferem entre si com base na presença ou ausência de determinados objetos sozinhos, dificultando a negação do reconhecimento. A correção do modelo depende de dois objetivos de treinamento. Por outro lado, a perda de contraste facilita o alinhamento entre pares de legendas de imagens, o que melhora o desempenho na recuperação. Por outro lado, o uso da perda de múltipla escolha ajudou a fazer julgamentos de negação bem caracterizados, escolhendo as legendas corretas no contexto do MCQ.

Modelos ajustados mostraram melhorias significativas em tarefas de recuperação e compreensão usando conjuntos de dados aprimorados com definição. Para recuperação, o recall do modelo é aumentado em 10% para as consultas adversárias, onde o desempenho é quase igual ao das tarefas normais de recuperação. Nas tarefas de questões de múltipla escolha, foi relatada uma melhoria na precisão de até 40%, indicando uma melhor capacidade de distinguir entre legendas implícitas positivas e negativas. As melhorias foram consistentes em uma variedade de conjuntos de dados, incluindo COCO e MSR-VTT, bem como conjuntos de dados sintéticos, como HardNeg-Syn, onde os modelos lidaram adequadamente com negação e desenvolvimento de linguagem complexa. Isto sugere que representar situações com diferentes tipos de negação em treinamento e teste é eficaz na redução do viés de confirmação e da generalização.
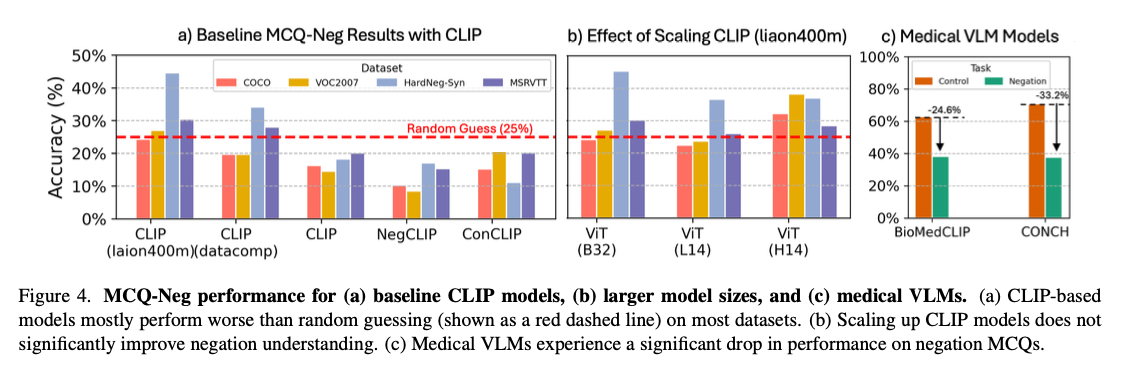
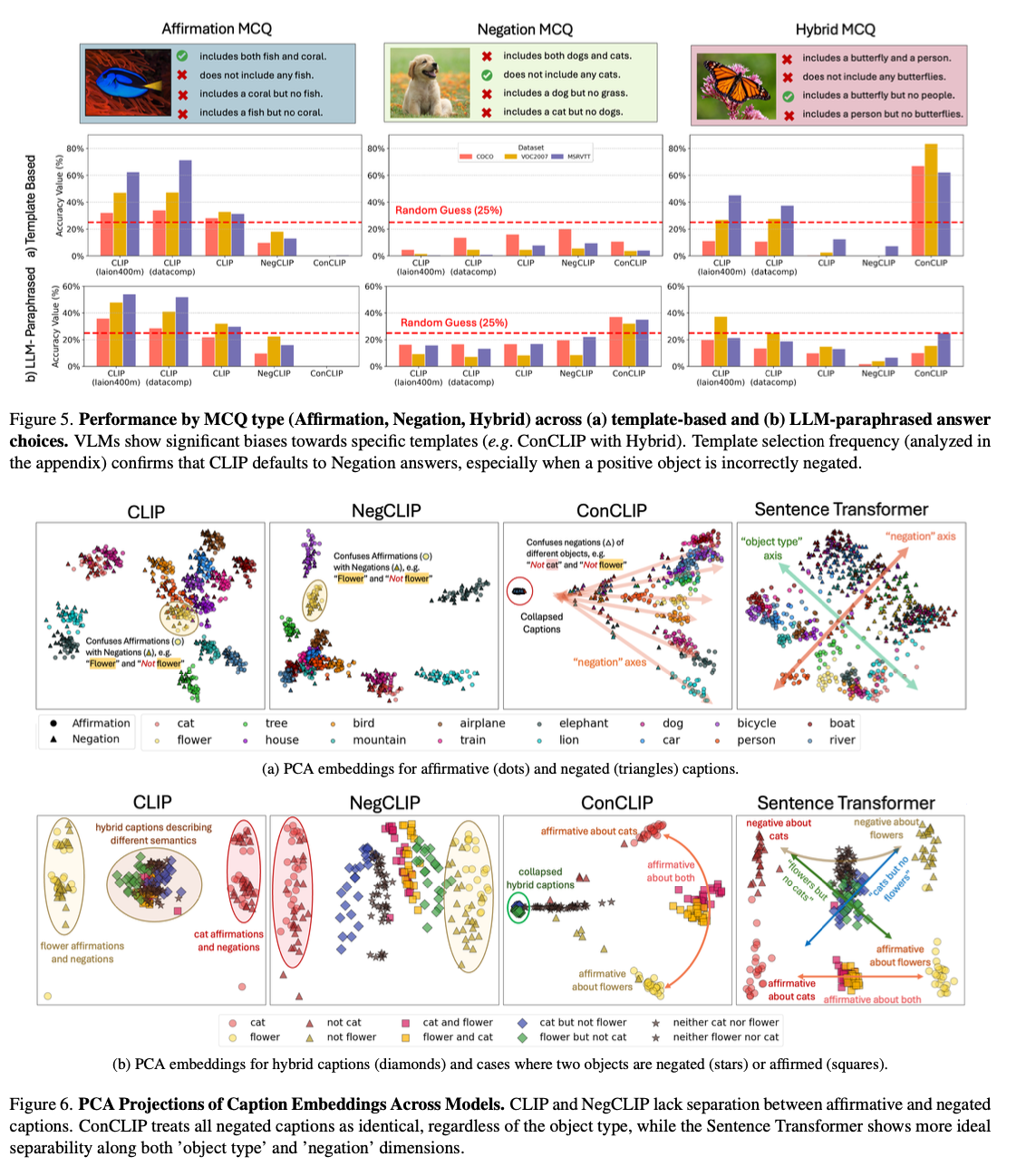
O NegBench aborda uma lacuna crítica nos VLMs ao ser o primeiro trabalho a abordar sua incapacidade de compreender a negação. Traz melhorias significativas nas tarefas de recuperação e compreensão, combinando diferentes exemplos de negação em treinamento e teste. Tais desenvolvimentos abrem caminho para sistemas de IA mais robustos, capazes de compreender diferentes línguas, com implicações importantes para domínios críticos como o diagnóstico médico e a recuperação semântica de conteúdos.
Confira Papel e Código. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 65k + ML.
🚨 [Recommended Read] Nebius AI Studio se estende com modelos de visão, novos modelos de linguagem, embeddings e LoRA (Promovido)
Aswin AK é consultor da MarkTechPost. Ele está cursando seu diploma duplo no Instituto Indiano de Tecnologia, Kharagpur. Ele é apaixonado por ciência de dados e aprendizado de máquina, o que traz consigo uma sólida formação acadêmica e experiência prática na solução de desafios de domínio da vida real.
📄 Conheça 'Height': a única ferramenta autônoma de gerenciamento de projetos (patrocinado)


 com decodificação inferencial")