
Hoje em dia, os modelos linguísticos de larga escala (LLMs) são integrados com sistemas multiagentes, onde muitos agentes inteligentes trabalham juntos para atingir um objetivo comum. As estruturas multiagentes são projetadas para melhorar a resolução de problemas, melhorar a tomada de decisões e aprimorar a capacidade dos sistemas de IA. para atender às diferentes necessidades dos usuários. Ao distribuir responsabilidades entre os agentes, esses sistemas garantem melhor desempenho e oferecem mais soluções. Eles são essenciais para aplicações como suporte ao cliente, onde respostas precisas e adaptabilidade são essenciais.
No entanto, para implementar estes sistemas multiagentes, é necessário criar conjuntos de dados realistas e escaláveis para testes e formação. A falta de dados específicos de domínio e as preocupações com a privacidade em torno das informações proprietárias limitam a capacidade de treinar sistemas de IA de forma eficaz. Além disso, os agentes de IA voltados para o cliente devem manter o pensamento lógico e a precisão ao navegar por sequências de ações ou trajetórias para alcançar soluções. Esse processo geralmente envolve chamadas para ferramentas externas, levando a erros se a sequência ou os parâmetros errados forem usados. Essa imprecisão leva à redução da confiança do usuário e da confiabilidade do sistema, o que cria uma necessidade crítica de métodos mais robustos para validar trajetórias de agentes e gerar conjuntos de dados de teste realistas.
Tradicionalmente, enfrentar estes desafios envolvia confiar em dados anónimos ou utilizar LLMs como juízes para validar métodos. Embora as soluções baseadas em LLM tenham se mostrado promissoras, elas enfrentam limitações significativas, incluindo sensibilidade às informações de entrada, resultados inconsistentes de modelos baseados em API e altos custos operacionais. Além disso, esses métodos são demorados e exigem escalonamento eficiente, especialmente quando aplicados a domínios complexos que exigem respostas precisas e conscientes do contexto. Como resultado, há uma necessidade urgente de uma solução determinística e econômica para validar o comportamento do agente de IA e garantir resultados confiáveis.
Pesquisadores da Splunk Inc. eles propuseram uma nova estrutura chamada MAG-V (Mfinalmente-UMEstrutura Gentil para Dados Sintéticos Gforça e Verificação), que visa superar essas limitações. MAG-V é um sistema multiagente projetado para gerar conjuntos de dados artificiais e validar trajetórias de agentes de IA. A estrutura introduz uma nova abordagem que combina técnicas de aprendizado de máquina de última geração com recursos avançados de LLM. Ao contrário dos programas tradicionais, o MAG-V não depende de LLMs como mecanismos de feedback. Em vez disso, utiliza métodos determinísticos e modelos de aprendizado de máquina para garantir exatidão e precisão na verificação de trajetória.
MAG-V usa três agentes especiais:
- Investigador: um investigador cria perguntas que imitam perguntas reais de clientes
- Assistente: o assistente responde com base em trajetórias predefinidas
- Engenharia reversa: uma engenharia reversa cria mais perguntas a partir das respostas do assistente
Este processo permite que a estrutura gere conjuntos de dados sintéticos que testam as capacidades do assistente. A equipe começou com um conjunto de dados inicial de 19 perguntas e expandiu para 190 perguntas sintéticas por meio de um processo iterativo. Após filtragem rigorosa, 45 questões de alta qualidade foram selecionadas para avaliação. Cada questão foi executada cinco vezes para identificar o padrão mais comum, garantindo a confiabilidade do conjunto de dados.
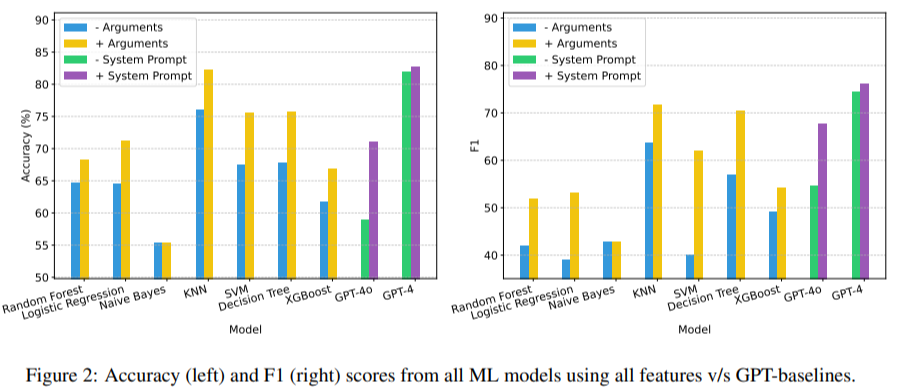
MAG-V usa similaridade semântica, planejamento gráfico de distância e sobreposição de argumentos para verificar trajetórias. Isso inclui modelos de aprendizado de máquina, como k-vizinhos mais próximos (k-NN), máquinas de vetores de suporte (SVM) e florestas aleatórias. A estrutura foi bem-sucedida em seus testes, superando as bases de juízes do GPT-4o com 11% de precisão e igualando o desempenho do GPT-4 em diversas métricas. Por exemplo, o modelo k-NN do MAG-V alcançou uma precisão de 82,33% e mostrou uma pontuação F1 de 71,73. Este método também demonstrou boa relação custo-benefício ao combinar modelos baratos, como o GPT-4o-mini, com amostras de aprendizagem no contexto, orientando-os a ter desempenho em níveis comparáveis aos LLMs mais caros.
A estrutura MAG-V fornece resultados ao abordar os principais desafios na validação de rotas. Sua natureza determinística garante resultados consistentes, eliminando a variabilidade associada aos métodos baseados em LLM. Ao gerar conjuntos de dados sintéticos, o MAG-V reduz a dependência de dados reais de clientes, abordando questões de privacidade e escassez de dados. A capacidade da estrutura de verificar trajetórias usando recursos e incorporações baseadas em matemática representa um progresso na confiabilidade do sistema de IA. Além disso, a dependência do MAG-V de outras consultas para validar a trajetória fornece uma maneira robusta de testar e validar os métodos de raciocínio dos agentes de IA.
Muitas das principais conclusões do estudo MAG-V são as seguintes:
- O MAG-V gerou 190 consultas sintéticas de 19 conjuntos de dados iniciais, filtrando-os em 45 consultas de alta qualidade. Este processo demonstrou o potencial da criação de dados quantificáveis para apoiar testes e formação em IA.
- O método de tomada de decisão da estrutura elimina a dependência de métodos LLM como juiz, fornecendo resultados consistentes e reprodutíveis.
- Os modelos de aprendizado de máquina treinados com recursos do MAG-V alcançaram uma melhoria de precisão de até 11% em relação à linha de base do GPT-4o, demonstrando a eficácia do método.
- Ao combinar a aprendizagem no conteúdo com LLMs de baixo custo como o GPT-4o-mini, o MAG-V forneceu uma alternativa econômica aos modelos de última geração sem comprometer o desempenho.
- A estrutura é adaptável a diferentes domínios e demonstra escalabilidade ao usar outras questões para validar métodos.

Em conclusão, o quadro MAG-V aborda eficazmente os principais desafios na geração de dados artificiais e na validação de trajetórias para sistemas de IA. A estrutura fornece uma solução escalável, econômica e determinística, combinando sistemas multiagentes com modelos clássicos de aprendizado de máquina, como k-NN, SVM e Random Forests. A capacidade do MAG-V de gerar conjuntos de dados artificiais de alta qualidade e validar trajetórias com precisão o torna ideal para alimentar aplicações de IA confiáveis.
Confira eu Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 60k + ML.
🚨 [Must Subscribe]: Assine nosso boletim informativo para tendências de pesquisa de IA e atualizações de desenvolvimento
Sana Hassan, estagiária de consultoria na Marktechpost e estudante de pós-graduação dupla no IIT Madras, é apaixonada pelo uso de tecnologia e IA para enfrentar desafios do mundo real. Com um profundo interesse em resolver problemas do mundo real, ele traz uma nova perspectiva para a intersecção entre IA e soluções da vida real.
🧵🧵 [Download] Avaliação do relatório do modelo de risco linguístico principal (ampliado)


