
Testar sistemas de IA conversacionais alimentados por modelos linguísticos em larga escala (LLMs) apresenta um desafio importante para a inteligência artificial. Estes sistemas devem lidar com interações dinâmicas, incorporar ferramentas específicas de domínio e acomodar restrições políticas complexas – forças que os métodos de avaliação tradicionais têm dificuldade em avaliar. Os benchmarks existentes baseiam-se em conjuntos de dados pequenos e escolhidos a dedo com métricas de ganhos, não conseguindo capturar as interações dinâmicas das políticas, as interações dos utilizadores e a variabilidade do mundo real. Esta lacuna limita a capacidade de identificar vulnerabilidades ou desenvolver agentes para utilização em áreas de alto perfil, como cuidados de saúde ou finanças, onde a fiabilidade é negociável.
Quadros de avaliação atuais, como banco τ ou ALMITAconcentre-se em domínios menores, como suporte ao cliente e no uso de conjuntos de dados estáticos e limitados. Por exemplo, o banco τ testa chatbots de companhias aéreas e de varejo, mas inclui apenas 50 a 115 amostras manuais por domínio. Esses benchmarks priorizam taxas de sucesso de ponta a ponta, ignorando detalhes granulares, como violações de políticas ou consistência de conversas. Algumas ferramentas, como aquelas que testam sistemas de geração aumentada de recuperação (RAG), não têm suporte para interação multicurvas. Depender do design humano limita a extensibilidade e a versatilidade, deixando a análise de IA conversacional incompleta e ineficaz para as necessidades do mundo real. Para lidar com essas limitações, Os pesquisadores da Plurai apresentaram o IntelAgent, uma estrutura aberta e multiagente projetada para automatizar a criação de diversos cenários orientados por políticas. Ao contrário dos métodos anteriores, o IntelliAgent combina modelagem de políticas baseada em gráficos, geração de eventos sintéticos e simulações dinâmicas para avaliar completamente os agentes.
Basicamente, o IntelliAgent usa um gráfico de política modelar os relacionamentos e a complexidade de regras específicas de domínio. Os nós neste gráfico representam políticas individuais (por exemplo, “as devoluções devem ser processadas dentro de 5 a 7 dias”), cada uma com uma pontuação de complexidade atribuída. As arestas entre os nós indicam a probabilidade de as políticas ocorrerem simultaneamente em uma conversa. Por exemplo, uma política sobre ajuste de reservas de voos pode estar vinculada a outra sobre períodos de reembolso. O gráfico é construído usando LLM, que extrai políticas do conhecimento do sistema, mede sua complexidade e estima a probabilidade de ocorrerem juntas. Essa propriedade permite que o IntelAgent gere eventos transacionais conforme mostrado na Figura 4 – solicitações de usuários emparelhadas com instâncias de banco de dados ativas – em um passeio aleatório ponderado. Começando pela primeira política com a mesma amostra, o sistema percorre o gráfico, acumulando políticas até que o valor da complexidade atinja um limite pré-definido. Este método de verificação garante que os eventos tenham uma distribuição uniforme de complexidade, mantendo ao mesmo tempo uma combinação realista de políticas.
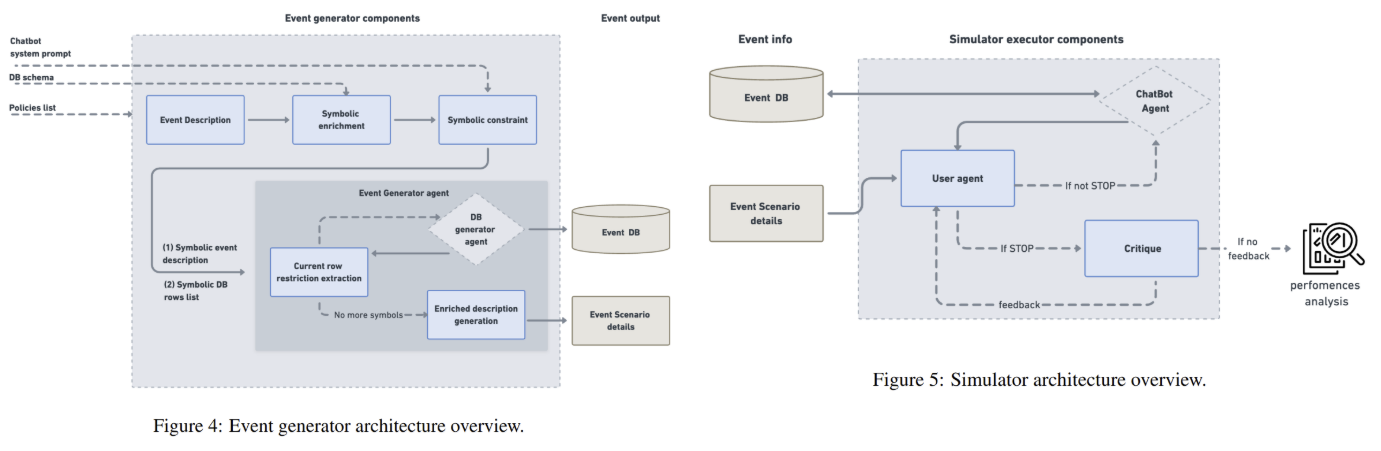
Depois que os eventos são gerados, o IntelliAgent simula conversas entre um agente do usuário e o chatbot sob teste, conforme mostrado na Figura 5. O agente do usuário inicia solicitações com base nas informações do evento e monitora a adesão do chatbot às políticas. Se o chatbot quebrar as regras ou concluir a tarefa, a conexão será encerrada. UM parte da crítica em seguida, analisa o diálogo, identificando quais políticas foram testadas e violadas. Por exemplo, no caso de uma companhia aérea, a crítica pode sinalizar uma falha na verificação da identidade de um utilizador antes de processar uma reserva. Esta etapa produz diagnósticos bem analisados, que revelam não apenas o desempenho geral, mas também pontos fracos específicos, como dificuldades com as políticas de consentimento do usuário – uma categoria negligenciada pelo τ-bench.
Para validar o IntelAgent, os pesquisadores compararam seus benchmarks de desempenho com os benchmarks τ usando LLMs de última geração, como GPT-4o, Claude-3.5 e Gemini-1.5. Apesar de depender inteiramente da geração automática de dados, o IntelAgent alcançou uma correlação de Pearson de 0,98 (companhia aérea) e 0,92 (comercial) com resultados de banco τ selecionados manualmente. Mais importante ainda, revelou dados falhos: todos os modelos falharam nas políticas de consentimento do utilizador e o desempenho diminuiu previsivelmente à medida que a complexidade aumentou, embora os padrões de degradação diferissem entre os modelos. Por exemplo, o Gemini-1.5-pro superou o GPT-4o-mini em níveis de dificuldade mais baixos, mas atingiu-o em níveis mais elevados. Essas descobertas destacam a capacidade do IntelliAgent de orientar a seleção de modelos com base em requisitos operacionais específicos. O design modular da estrutura permite a integração perfeita de novos domínios, políticas e ferramentas, com suporte de implementações de código aberto incorporadas à biblioteca LangGraph.
Concluindo, o IntelAgent aborda um gargalo crítico no desenvolvimento da IA conversacional, substituindo diagnósticos estáticos e limitados por diagnósticos dinâmicos e escaláveis. O seu gráfico de políticas e a geração automática de eventos permitem testes abrangentes numa variedade de cenários, enquanto críticas bem analisadas apontam para potenciais melhorias. Ao correlacionar-se estreitamente com os parâmetros de referência existentes e expor fraquezas anteriormente invisíveis, o quadro preenche a lacuna entre a investigação e a implantação no mundo real. Aprimoramentos futuros, como a incorporação da interação do usuário em tempo real para refinar gráficos de políticas, podem melhorar sua usabilidade, solidificando o IntelliAgent como uma ferramenta fundamental para o desenvolvimento de agentes de conversação confiáveis e conscientes das políticas.
Confira Página de papel e GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso Mais de 70k ML SubReddit.
🚨 [Recommended Read] Nebius AI Studio se estende com modelos de visão, novos modelos de linguagem, embeddings e LoRA (Promovido)
Vineet Kumar é estagiário de consultoria na MarktechPost. Atualmente, ele está cursando seu bacharelado no Instituto Indiano de Tecnologia (IIT), Kanpur. Ele é um entusiasta do aprendizado de máquina. Ele está interessado em pesquisas e desenvolvimentos recentes em Deep Learning, Visão Computacional e áreas afins.
📄 Conheça 'Height': ferramenta independente de gerenciamento de projetos (patrocinado)


