
A otimização dos modelos de aprendizagem profunda continua a ser um grande desafio, à medida que o custo de formação dos principais modelos linguísticos (LLMs) continua a aumentar. À medida que os modelos crescem, a carga computacional e o tempo de treinamento necessário aumentam significativamente, criando a necessidade de otimizações eficientes que podem reduzir o tempo e os recursos de treinamento. Este desafio é fundamental para reduzir a sobrecarga em sistemas de IA do mundo real e tornar possível o treinamento de modelos em grande escala.
Os métodos de otimização atuais incluem otimizadores de primeira ordem, como Adão e métodos de segunda ordem, como Xampu. Enquanto Adão amplamente utilizado em suas aplicações estatísticas, muitas vezes é menos convergente, especialmente em grandes configurações de cluster. Em contraste, Xampu fornece alto desempenho usando pré-condicionadores fatorados por Kronecker, mas sofre de alta complexidade computacional, pois requer autocomposição constante e introduz muitos hiperparâmetros adicionais. Isto limita a robustez e eficiência do Shampoo, especialmente para aplicações grandes e em tempo real.
Pesquisadores da Universidade de Harvard propõem SABÃO (Shampoo com Adam na base do Pré-condicionador) para superar as limitações do Shampoo. SOAP combina o poder do Adão de novo Xampu correndo Adão na base própria dos pré-condicionadores do Shampoo, reduzindo assim a sobrecarga computacional. Este método reduz a necessidade de operações de matriz constantes e reduz o número de hiperparâmetros, o SOAP introduz apenas um hiperparâmetro – a frequência de pré-condicionamento – em comparação com Adam. Esta nova abordagem melhora a eficiência e o desempenho do treinamento sem comprometer a precisão.
SOAP modifica o ativador Shampoo regular atualizando as primitivas diversas vezes e aplicando as atualizações de Adam ao ambiente estendido definido pelas primitivas Shampoo. Ele armazena dois pré-condicionadores para a matriz de peso de cada camada e os atualiza com base na frequência de pré-condicionamento configurada. Na configuração experimental, o SOAP foi testado em modelos com parâmetros 360M e 660M em tarefas de treinamento em lote. A frequência de pré-condicionamento e outros hiperparâmetros são otimizados para garantir que o SOAP maximize o desempenho e a eficiência, mantendo a alta precisão e reduzindo significativamente a sobrecarga computacional.

O SOAP apresentou melhorias significativas no desempenho e na eficiência, reduzindo as iterações de treinamento em 40% e o tempo de clock em 35% em comparação com o AdamW. Além disso, obteve desempenho 20% melhor que o Shampoo em ambas as métricas. Essa melhoria foi consistente nos diferentes modelos de tamanho, com o SOAP mantendo ou excedendo as pontuações dos testes de perda do AdamW e do Shampoo. Isso destaca a capacidade do SOAP de medir a eficiência do treinamento e o desempenho do modelo, tornando-o uma ferramenta poderosa para o desenvolvimento de aprendizagem profunda em escala.
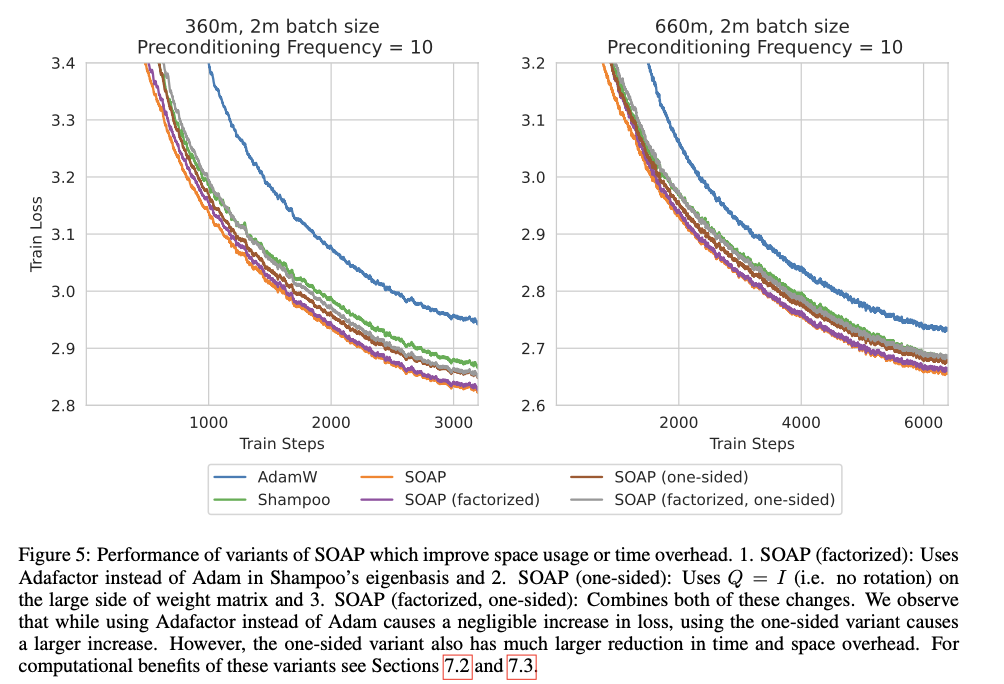
Para concluir, SABÃO apresenta avanços significativos na realização de aprendizagem profunda, integrando a eficiência computacional de Adão com benefícios de segunda ordem Xampu. Ao reduzir a sobrecarga computacional e a complexidade dos hiperparâmetros, o SOAP fornece uma solução mais escalável e eficiente para treinar modelos grandes. A capacidade do método de reduzir tanto a iteração de treinamento quanto o tempo do relógio sem sacrificar o desempenho sublinha seu potencial para ser um padrão eficaz para o desenvolvimento de modelos de IA em larga escala, contribuindo para um treinamento mais eficiente e para a possibilidade de aprendizagem profunda.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)
Aswin AK é consultor da MarkTechPost. Ele está cursando seu diploma duplo no Instituto Indiano de Tecnologia, Kharagpur. Ele é apaixonado por ciência de dados e aprendizado de máquina, o que traz consigo uma sólida formação acadêmica e experiência prática na solução de desafios de domínio da vida real.
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)
: uma estrutura de IA para modelagem de pensamento recursivo com modelos de linguagem em larga escala (LLMs) como construção de gráfico acíclico direcionado (DAG) dentro de um único modelo")

: um novo algoritmo para distribuição de dados dinâmicos em aprendizado de máquina, reduzindo a complexidade e melhorando a precisão do modelo")