")
Modelos Linguísticos de Grande Escala (LLMs) mostraram semelhanças notáveis com a capacidade dos processos cognitivos humanos de processar absurdos e de se adaptar a novas situações. Assim como as pessoas historicamente deram sentido a experiências complexas usando conceitos básicos como física e matemática, os transformadores autorregressivos agora demonstram habilidades comparáveis por meio da aprendizagem no contexto (ICL). Estudos recentes destacaram como esses modelos podem ser adaptados a tarefas ilusórias sem atualizações de parâmetros, sugerindo uma estrutura dedutiva interna semelhante aos modelos da mente humana. A pesquisa começou a examinar os aspectos mecanicistas de como os LLMs pré-treinados representam conceitos implícitos como vetores em suas representações. No entanto, permanecem questões sobre as razões subjacentes à existência destes protetores de emprego e ao seu desempenho diferente em diferentes empregos.
Os pesquisadores propuseram vários quadros teóricos para compreender os mecanismos por trás da aprendizagem no conteúdo em LLMs. Uma abordagem importante analisa a ICL através de uma estrutura Bayesiana, propondo um algoritmo de dois estágios que estima probabilidades e probabilidades posteriores. Em consonância com isso, a pesquisa identificou vetores específicos de tarefas em LLMs que podem provocar um comportamento desejável de ICL. Ao mesmo tempo, outros estudos revelaram como estes modelos incluem conceitos como realidade, tempo e espaço como representações linearmente separáveis. Usando técnicas de interpretação de máquina, como análise de mediação causal e correção aberta, os pesquisadores começaram a descobrir como esses conceitos aparecem nas representações LLM e influenciam o desempenho da tarefa ICL abaixo, mostrando que os transformadores usam algoritmos diferentes baseados em conceitos alvo.
Pesquisadores do Instituto de Tecnologia de Massachusetts e IA Improvável apresentam o Como codificar lógica, fornecendo uma explicação satisfatória de como os transformadores melhoram os internos. A pesquisa com um pequeno transformador treinado em pequenas tarefas de regressão linear revela que a codificação evolui à medida que o modelo aprende a mapear conceitos latentes em espaços representacionais discretos e separáveis. Este processo funciona em conjunto com o desenvolvimento de algoritmos ICL para um conceito específico usando mapeamento de conceito. Experimentos em diferentes famílias de modelos pré-treinados, incluindo Llama-3.1 e Gemma-2 em tamanhos diferentes, mostram que modelos de linguagem grandes exibem isso. comportamento de codificação-decodificação ao considerar as funções naturais da ICL. O estudo apresenta Decodificabilidade de conceito como uma medida geométrica da estrutura de abstração interna, indicando que as camadas anteriores incluem conceitos ocultos, enquanto as camadas posteriores impõem algoritmos a essas palavras abstratas, ambos os processos se desenvolvendo de forma interdependente.
A estrutura teórica para a compreensão da aprendizagem em contexto baseia-se fortemente na perspectiva Bayesiana, que sugere que os transformadores reduzem implicitamente as variáveis latentes das exibições antes de gerar respostas. Este processo funciona em duas etapas distintas: a interpretação do conceito subjacente e a aplicação selecionada do algoritmo. Evidências experimentais de tarefas sintéticas, particularmente usando regressão linear mínima, mostram como esse processo surge durante o treinamento do modelo. Quando treinados em múltiplas tarefas com diferentes bases subjacentes, os modelos desenvolvem espaços de representação únicos para diferentes conceitos, ao mesmo tempo que aprendem a usar algoritmos específicos de conceitos. A pesquisa mostra que conceitos que compartilham sobreposição ou relacionamento tendem a compartilhar pequenos espaços representacionais, sugerindo potenciais limitações de como os modelos distinguem entre tarefas relacionadas no processamento de linguagem natural.
O estudo fornece forte validação do conceito de codificação de máquina para grandes modelos de linguagem pré-treinados em famílias e diferentes escalas, incluindo Llama-3.1 e Gemma-2. Ao testar a marcação de classes gramaticais e operações aritméticas inteligentes, os pesquisadores mostraram que os modelos desenvolvem espaços representacionais muito diferentes para diferentes conceitos à medida que o número de exemplos dentro do conteúdo aumenta. O estudo introduziu a Decodabilidade de Conceito (CD) como uma métrica para medir quão bem conceitos abstratos podem ser deduzidos de representações, mostrando que pontuações mais altas de CD estão mais intimamente relacionadas a um melhor desempenho de tarefas. Notavelmente, conceitos frequentemente encontrados durante o pré-treinamento, como substantivos e operações matemáticas básicas, mostram diferenças claras no espaço representacional em comparação com conceitos mais complexos. A pesquisa também mostra, por meio de experimentos de otimização, que as camadas anteriores desempenham um papel importante na codificação conceitual, com alterações nessas camadas trazendo melhores melhorias de desempenho do que alterações nas camadas posteriores.
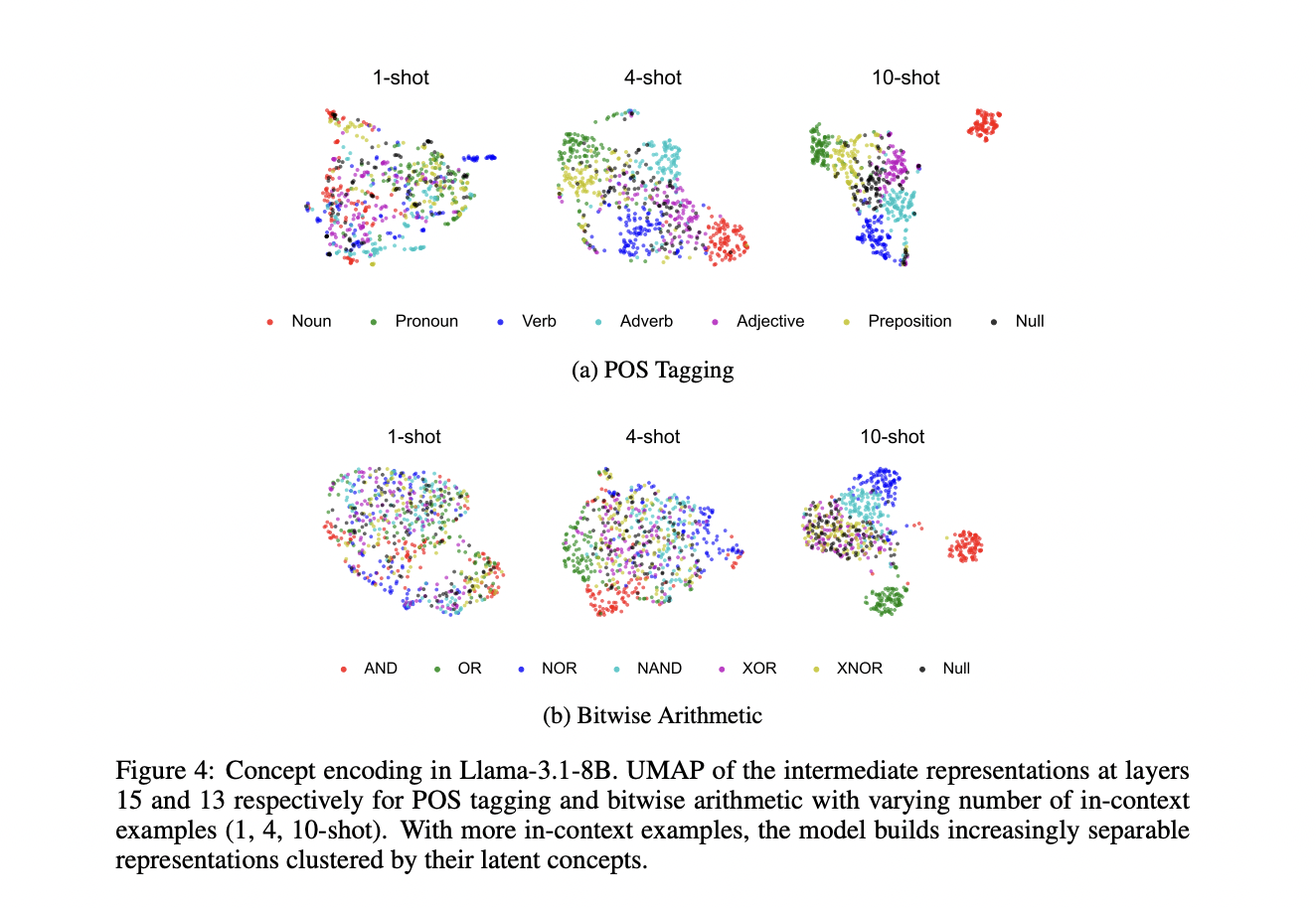

A abordagem do conceito de codificação fornece insights importantes sobre várias questões importantes sobre o comportamento e as capacidades dos grandes modelos de linguagem. O estudo trata das diferentes taxas de sucesso dos LLMs nas diferentes tarefas de aprendizagem no conteúdo, sugerindo que restrições de desempenho podem ocorrer tanto nos estágios conceituais quanto nos algorítmicos. Modelos que mostram desempenho e pontuações fortes são frequentemente encontrados durante o pré-treinamento, como operadores lógicos básicos, mas podem ter dificuldades mesmo com algoritmos bem conhecidos se a distinção conceitual permanecer obscura. A metodologia também explica por que a modelagem implícita de variáveis latentes não resulta em aprendizagem implícita em transformadores, uma vez que transformadores gerais melhoram capacidades de codificação eficientes. Além disso, esta estrutura fornece uma base teórica para a compreensão de intervenções baseadas em ativação em LLMs, sugerindo que tais abordagens funcionam influenciando diretamente as representações codificadas que orientam o processo de geração de modelos.
Confira eu Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 60k + ML.
🚨 Tendências: LG AI Research Release EXAONE 3.5: Modelos de três níveis de IA bilíngue de código aberto oferecem seguimento de comando incomparável e insights profundos de conteúdo Liderança global em excelência em IA generativa….
Asjad é consultor estagiário na Marktechpost. Ele está cursando B.Tech em engenharia mecânica no Instituto Indiano de Tecnologia, Kharagpur. Asjad é um entusiasta do aprendizado de máquina e do aprendizado profundo que pesquisa regularmente a aplicação do aprendizado de máquina na área da saúde.
🧵🧵 [Download] Avaliação do relatório do modelo de risco linguístico principal (ampliado)


