: um método não supervisionado para modelos de pré-treinamento de percepção-linguagem-ação (VLA) sem rótulos de ação de robô de verdade básica")
Os modelos de visão-linguagem-ação (VLA) para robôs são treinados combinando modelos de linguagem em grande escala com codificadores de visão e ajustando-os em conjuntos de dados de robôs; isso permite a adaptação a novas instruções, visões e mudanças de distribuição. No entanto, os conjuntos de dados de robôs do mundo real exigem muito controle humano, o que dificulta o dimensionamento. Por outro lado, os dados de vídeo da Internet fornecem muitos exemplos de comportamento humano e interações físicas em escala, apresentando uma maneira melhor de superar as limitações de pequenos conjuntos de dados robóticos especializados. Além disso, aprender com vídeos online é difícil por dois motivos: a maioria dos vídeos online não possui rótulos claros para suas ações correspondentes, e as situações mostradas nos vídeos da web são muito diferentes das situações em que os robôs trabalham.
Foi demonstrado que os Modelos de Visão-Linguagem (VLMs), treinados em um amplo conjunto de dados no nível da Internet, incluindo texto, imagem e vídeo, compreendem e geram dados de impressão textuais e multimodais. Recentemente, a incorporação de objetivos de apoio, como rastreamento visual, métodos de raciocínio de linguagem ou a construção de um conjunto de dados de comandos de estilo conversacional usando dados de trajetória do robô durante o treinamento de VLA melhorou o desempenho. No entanto, estes métodos ainda dependem fortemente de dados de ação rotulados, o que limita a escalabilidade do desenvolvimento de VLAs gerais, uma vez que estarão limitados pela quantidade de dados do robô disponibilizados pelo teletrabalho humano. As Políticas de Treinamento de Robôs dos vídeos contêm informações valiosas sobre dinâmica e comportamento, o que pode ser benéfico para o aprendizado de um robô. Alguns trabalhos recentes exploram os benefícios de modelos de geração de vídeo pré-treinados em vídeos de humanos e tarefas de robôs que atravessam rios. Outra linha de trabalho visa aprender informações úteis de vídeos humanos, aprendendo a partir de interações, dinâmicas ou pistas visuais extraídas de vídeos humanos. Outra linha de trabalho visa aprender políticas de manipulação de robôs inferindo movimentos humanos de robôs. Essas tarefas dependem de modelos disponíveis no mercado, como estimadores de postura de mão ou sistemas de captura de movimento, para redirecionar os movimentos humanos diretamente para os movimentos do robô. Os métodos de treinamento de robôs existentes são específicos para tarefas ou exigem dados de robôs totalmente integrados, o que limita sua generalização. Outros métodos rotulam grandes conjuntos de dados com uma pequena quantidade de dados rotulados como ações para treinar robôs, mas ainda apresentam problemas de escalabilidade sob demanda.
Pesquisadores de KAIST, Universidade de Washington, Microsoft Research, NVIDIA e Allen Institute de IA modelos propostos de pré-treinamento de ação latente para ação geral (LAPA), uma abordagem não supervisionada usando vídeos em escala de internet sem rótulos de ação de robô. Eles propuseram este método para aprender a partir de vídeos não rotulados de ação de robôs em escala de Internet. LAPA envolve o treinamento de um modelo de estimativa de ação baseado em objetivo baseado em VQ-VAE para aprender ações latentes entre quadros de imagem e, em seguida, pré-treinar um modelo VLA latente para prever essas ações latentes a partir de observações e descrições de tarefas e, finalmente, ajustar o VLA para . dados de manipulação de micro robôs para mapear ações sutis do robô. Os resultados experimentais mostram que o método proposto supera significativamente as técnicas existentes que treinam políticas de manipulação de robôs em vídeos grandes. Além disso, ele supera o modelo VLA de última geração treinado com rótulos de ação de robô em tarefas manipulativas do mundo real que exigem condicionamento linguístico, generalização de objetos visuais e integração semântica em comandos abstratos.
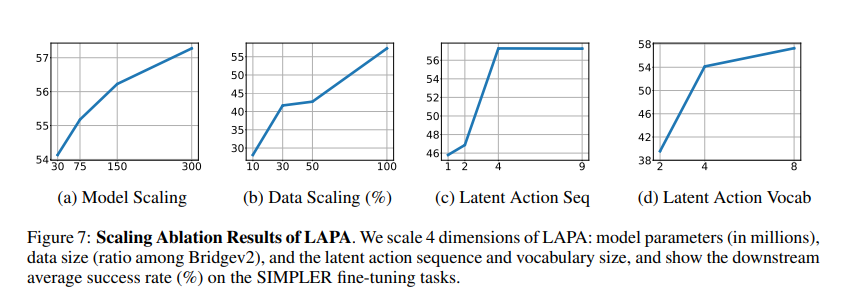
O LAPA consiste em duas fases de pré-treinamento seguidas de ajuste fino para conectar as ações latentes às ações reais do robô. Na primeira fase, é utilizada uma abordagem baseada em VQ-VAE para dividir as ações em componentes pequenos e básicos, sem exigir categorias fixas para essas ações. A segunda fase envolve integração comportamental, onde um modelo de linguagem visual prevê ações implícitas a partir da visualização de vídeos e descrições de tarefas. O modelo é então ajustado em um pequeno conjunto de dados de manipulação de robôs para aprender como mapear desde ações ocultas até ações robóticas. LAPA, que significa o modelo proposto de Visão-Linguagem-Ação (VLA), supera o melhor modelo anterior, OPENVLA, apesar de ser treinado apenas em vídeos de manipulação humana. Ele mostra melhor desempenho do que grandes conjuntos de dados de robôs como Bridgev2 e é 30-40 vezes melhor no pré-treinamento, usando apenas 272 horas H100 em comparação com 21.500 horas A100 para OPENVLA. O desempenho da LAPA traz benefícios para grandes modelos e conjuntos de dados, mas há retornos decrescentes em determinadas escalas. Além disso, combina muito bem com o movimento real, provando ser eficaz em tarefas que envolvem manipulação humana. Além disso, a simulação demonstra a capacidade do LAPA de programar ações robóticas baseadas em comandos simples, destacando seu potencial para uso em sistemas robóticos complexos. O LAPA melhora significativamente o desempenho do robô em tarefas, tanto em simulação quanto em situações do mundo real, em comparação com métodos anteriores que dependem de vídeo sem rótulos. Ele supera até mesmo o melhor modelo atual usando ações rotuladas em 6,22% e é 30 vezes melhor no pré-treinamento.
Concluindo, LAPA é um método de treinamento em pré-escala para construção de VLAs usando vídeos redundantes. Em todos os três benchmarks que incluem simulação e teste de robôs do mundo real, foi demonstrado que este método melhora significativamente a transferência de tarefas posteriores em comparação com os métodos existentes. Ele também apresenta um modelo VLA de última geração que supera os modelos atuais treinados em trajetórias marcadas com ação de 970 mil. Além disso, mostrou que a LAPA só pode ser aplicada a vídeos de manipulação humana, onde faltam informações claras sobre a ação e a lacuna de correspondência é grande.
Apesar destas características únicas, o LAPA é menos eficiente em comparação com o pré-treinamento de ação quando se trata de tarefas de produção de movimento bem analisadas, como a preensão. Expandir o espaço para gerar ação latente pode ajudar a resolver esse problema. Em segundo lugar, semelhante aos VLAs anteriores, a LAPA também enfrenta desafios de latência em tempo real. A adoção de uma arquitetura hierárquica, onde a cabeça pequena prevê ações com alta frequência, pode reduzir a latência e melhorar a produção de movimentos bem caracterizados. O LAPA mostra o movimento da câmera, mas ainda não foi testado além da manipulação de vídeo, como em carros autônomos ou navegação. Este trabalho pode ser estendido para construir modelos robóticos escaláveis e apoiar pesquisas futuras.
Confira Papel, cartão modelo no HuggingFace e página do projeto. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] Melhor plataforma para modelos ajustados: mecanismo de inferência Predibase (avançado)
Nazmi Syed é estagiária de consultoria na MarktechPost e está cursando bacharelado em ciências no Instituto Indiano de Tecnologia (IIT) Kharagpur. Ele tem uma profunda paixão pela Ciência de Dados e está explorando ativamente a ampla aplicação da inteligência artificial em vários setores. Fascinada pelos avanços tecnológicos, a Nazmi está comprometida em compreender e aplicar inovações de ponta em situações do mundo real.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️
")

