
Os Modelos Linguísticos de Grande Escala (LLMs) enfrentam limitações de escala significativas na melhoria das suas capacidades de inferência através de simulações baseadas em dados, uma vez que um melhor desempenho requer exemplos de formação de altíssima qualidade. Métodos baseados em experimentos, especialmente aprendizagem por reforço (RL), oferecem uma alternativa promissora para superar essas limitações. A transição de métodos baseados em dados para bases experimentais apresenta dois desafios importantes: desenvolver métodos eficientes para gerar sinais de recompensa precisos e projetar algoritmos RL eficientes que maximizem o uso desses sinais. Esta mudança representa um passo importante no desenvolvimento das habilidades de pensamento do LLM.
A equipe de pesquisa apresenta PRIME (Reforço Processual com Recompensas Implícitas), uma nova forma de melhorar o raciocínio de modelos de linguagem em RL online com recompensas procedimentais. O programa usa um modelo implícito de recompensa de processo (PRM), que opera sem exigir rótulos de processo e atua como um modelo de recompensa de resultado. Este método facilita o desenvolvimento do Eurus-2-7B-PRIME, um poderoso modelo computacional que mostra melhorias significativas tanto no treinamento RL online quanto na medição do tempo de decisão. A inovação do PRM fuzzy reside na sua dupla capacidade de melhorar o desempenho e facilitar o treinamento eficaz de RL.
A equipe de pesquisa escolheu Qwen2.5-Math-7B-Base como modelo básico e testou o desempenho usando equações e programas matemáticos avançados. A primeira etapa envolve o ajuste fino supervisionado (SFT) usando uma estrutura conceitual de cadeia de ação onde os modelos escolhem entre sete ações predefinidas. A equipe construiu um conjunto de dados de 230 mil com uma variedade de materiais de código aberto, excluindo intencionalmente conjuntos de dados de alta qualidade com respostas pouco verdadeiras para manter para RL. Apesar desses esforços, o desempenho do modelo SFT diminuiu em Qwen2.5-Math-7B-Yala em todos os benchmarks matemáticos.
O estudo usa uma abordagem abrangente para a análise do conjunto de dados RL, que inclui 457 mil problemas matemáticos do NuminaMath-CoT e 27 mil problemas de código de várias fontes, incluindo APPS, CodeContest, TACO e Codeforces. A equipe usa uma estratégia de triagem rápida online que seleciona informações de forma dinâmica com base nos níveis de dificuldade. Ao amostrar múltiplas trajetórias e manter comandos com pontuações de precisão entre 0,2 e 0,8, eles estimam com sucesso a distribuição dos dados de treinamento, eliminando problemas muito simples e excessivamente desafiadores. Aqui está o fluxo do algoritmo do método PRIME proposto:
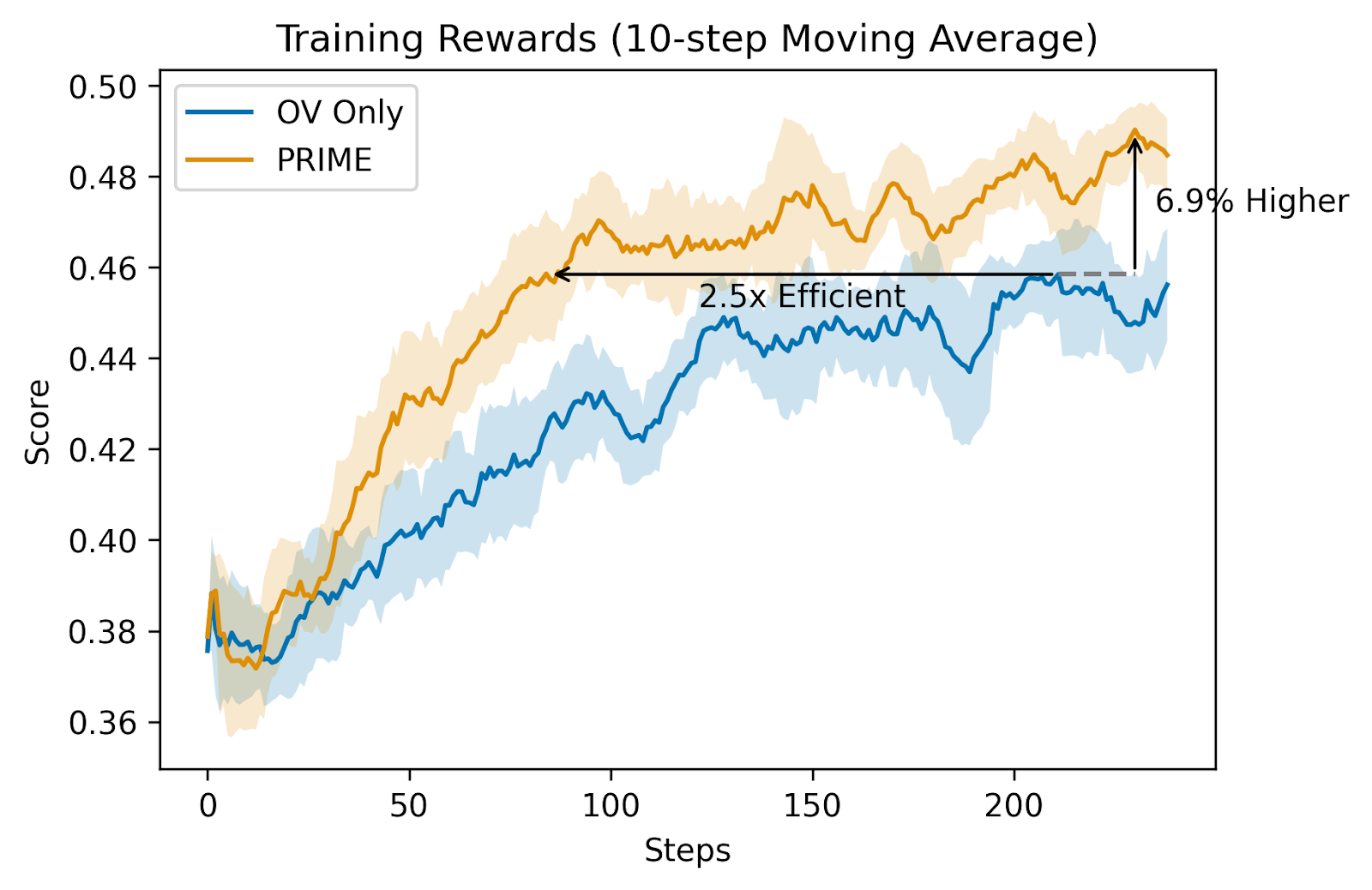
A implementação do PRIME segue um processo sistemático onde o modelo político e o PRM são implementados a partir do modelo SFT. O algoritmo funciona por meio de etapas sequenciais para gerar resultados, pontuá-los e atualizar ambos os modelos usando a saída combinada e as recompensas do processo. Com PRIME, a partir de Qwen2.5-Math-7B-Base, o modelo treinado Eurus-2-7B-PRIME atinge 26,7% pass@1, superando GPT-4o e Qwen2.5-Math -7B-Instruct. Isto é conseguido usando apenas 1/10 dos dados do Qwen Math (230K SFT + 150K RL). Além disso, o PRIME alcança uma melhoria significativa em métodos de pequenas recompensas usando certos hiperparâmetros e os resultados mostram um treinamento 2,5 vezes mais rápido, recompensas finais 6,9% maiores e, em particular, Eurus-2-7B-PRIME mostrou uma melhoria moderada de 16,7% em todos os benchmarks, mais de uma melhoria de 20% nos benchmarks AMC e AIME.
Finalmente, o processo de validação PRIME utiliza modelos de pensamento avançado (QwQ-32B-Preview e Qwen2.5-Math-72B-Instruct) para avaliar a resolução de problemas e a precisão da solução. Utilizando informações da análise de problemas de amostra e de casos sintéticos não resolvidos, a equipe desenvolveu recomendações especiais para melhorar a precisão da verificação. Cada problema é abordado em cinco tentativas completas de revisão, contendo soluções LaTeX passo a passo, testes de insolubilidade, sequências lógicas, formatação padrão de respostas e documentação de restrições de solução. Este rigoroso quadro de validação garante a qualidade e fiabilidade das respostas a ambas as perguntas.
Confira Página de rosto do abraço, Detalhes técnicosde novo GitHub Página. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 60k + ML.
🚨 PRÓXIMO WEBINAR GRATUITO DE IA (15 DE JANEIRO DE 2025): Aumente a precisão do LLM com dados artificiais e inteligência experimental–Participe deste webinar para obter insights práticos sobre como melhorar o desempenho e a precisão do modelo LLM e, ao mesmo tempo, proteger a privacidade dos dados.

Sajjad Ansari se formou no último ano do IIT Kharagpur. Como entusiasta da tecnologia, ele examina as aplicações da IA com foco na compreensão do impacto das tecnologias de IA e suas implicações no mundo real. Seu objetivo é transmitir conceitos complexos de IA de maneira clara e acessível.
🧵🧵 Siga-nos no X (Twitter) para pesquisas gerais sobre IA e atualizações de desenvolvimento aqui…


