
Um grande desafio no campo dos Modelos de Linguagem de Fala (SLMs) é a falta de métricas de avaliação abrangentes que vão além da modelagem básica do conteúdo textual. Embora os SLMs tenham mostrado um progresso significativo na produção de fala coerente e gramaticalmente correta, sua capacidade de modelar características acústicas como emoção, ruído de fundo e identidade do falante permanece pouco explorada. Avaliar esta dimensão é importante, pois a comunicação humana é fortemente influenciada por tais sinais acústicos. Por exemplo, a mesma frase falada em vozes diferentes ou em ambientes acústicos diferentes pode ter significados completamente diferentes. A ausência de benchmarks robustos para avaliar esses recursos limita o uso prático de SLMs em tarefas do mundo real, como detecção de emoções em assistentes virtuais ou em ambientes com vários alto-falantes em aplicações de transmissão ao vivo. Superar esses desafios é fundamental para avançar no campo e permitir um processamento de fala mais preciso e consciência do contexto.
Os métodos atuais de avaliação para SLMs concentram-se principalmente na precisão semântica e sintática, usando métricas baseadas em texto, como previsão de palavras e coerência de frases. Esses métodos incluem benchmarks como ProsAudit, que avalia recursos prosódicos, como configuração natural, e SD-eval, que avalia a capacidade dos modelos de gerar respostas de texto apropriadas para um determinado contexto de áudio. No entanto, esses métodos têm limitações importantes. Eles se concentram em um único aspecto da acústica (como a prosódia) ou dependem de métricas baseadas em geração que são computacionalmente intensivas, tornando-os inadequados para aplicações em tempo real. Além disso, as avaliações baseadas em texto não levam em conta a riqueza de informações não linguísticas presentes na fala, como a identidade do falante ou os sons da sala, o que pode alterar significativamente a percepção do conteúdo falado. Como resultado, os métodos existentes são insuficientes para avaliar o desempenho global dos SLMs em áreas onde a coerência semântica e acústica são importantes.
Pesquisadores da Universidade Hebraica de Jerusalém apresentam o SALMON, um sistema de teste abrangente projetado para testar a coerência acústica e as capacidades de alinhamento acústico-semântico dos SLMs. O SALMON apresenta duas funções de teste principais: (i) alinhamento acústico e (ii) alinhamento acústico-semântico, que testa quão bem o modelo pode preservar as características acústicas e alinhar-se com o texto falado. Por exemplo, o SALMON testa se o modelo pode detectar flutuações não naturais na identidade do locutor, ruído de fundo ou emoção em um clipe de áudio. Ele usa uma abordagem baseada em modelagem que atribui maior probabilidade a amostras que são totalmente consistentes em comparação com aquelas com características alteradas ou desalinhadas. Essa abordagem permite testes rápidos e escaláveis de modelos grandes, tornando-a adequada para aplicações do mundo real. Ao focar em uma variedade de fatores acústicos, como sensibilidade, identidade do locutor, ruído de fundo e acústica da sala, o SALMON representa uma inovação significativa na forma como os SLMs são testados, ampliando os limites dos testes de modelos de fala.
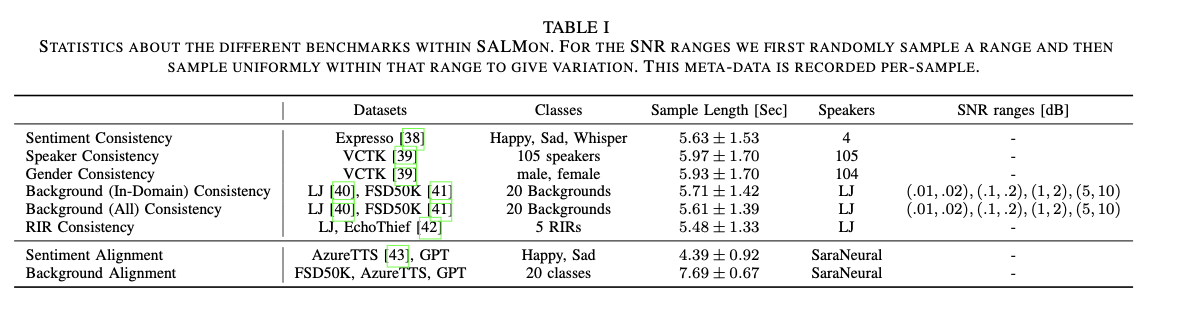
O SALMON utiliza vários benchmarks acústicos para testar vários aspectos da consistência da fala. Esses benchmarks usam conjuntos de dados especialmente selecionados para testar modelos em dimensões como consistência do alto-falante (usando o conjunto de dados VCTK), consistência emocional (usando o conjunto de dados Expresso) e consistência de ruído de fundo (usando LJ Speech e FSD50K). A função de consistência acústica testa se o modelo pode manter recursos como a identidade do locutor nas gravações ou detectar alterações na acústica da sala. Por exemplo, em uma tarefa de correspondência de resposta ao impulso de sala (RIR), uma amostra de fala é gravada com acústica de sala diferente para cada parte do clipe, e o modelo deve identificar essa alteração corretamente.
Na tarefa de correspondência acústico-semântica, a suíte desafia os modelos a combinar a localização de fundo ou emoção da fala com as pistas acústicas relevantes. Por exemplo, se a expressão se referir a uma “praia calma”, o modelo deverá dar maior probabilidade a uma gravação com ruído de praia do que a uma gravação com ruído de construção. Estes alinhamentos são testados utilizando dados compilados a partir de aplicações Azure Text-to-Speech e controlados através de filtragem manual para garantir exemplos claros e concisos. Os benchmarks são computacionalmente eficientes, pois não requerem intervenção humana ou modelos adicionais durante o tempo de execução, tornando o SALMON uma solução versátil para testar SLMs em uma variedade de ambientes acústicos.
A avaliação de múltiplos modelos de linguagem de fala (SLMs) usando SALMON revelou que, embora os modelos atuais possam lidar com tarefas acústicas básicas, eles apresentam desempenho significativamente pior do que os humanos em tarefas acústico-semânticas complexas. Os testadores humanos pontuaram consistentemente mais de 90% em tarefas como alinhamento de sentimento e detecção de ruído de fundo, enquanto modelos como TWIST 7B e pGSLM alcançaram taxas de precisão muito mais baixas, muitas vezes com desempenho um pouco melhor do que o acaso. Para tarefas simples, como consistência de gênero, modelos como o pGSLM tiveram melhor desempenho, atingindo 88,5% de precisão. No entanto, em tarefas mais desafiadoras que exigem compreensão acústica mista, como encontrar respostas à pressão da sala ou manter a harmonia acústica em diferentes ambientes, mesmo os melhores modelos ficam muito aquém das capacidades humanas. Estes resultados indicam uma clara necessidade de melhorar a capacidade dos SLMs de modelar conjuntamente características semânticas e acústicas, enfatizando a importância do desenvolvimento de modelos com reconhecimento acústico para aplicações futuras.
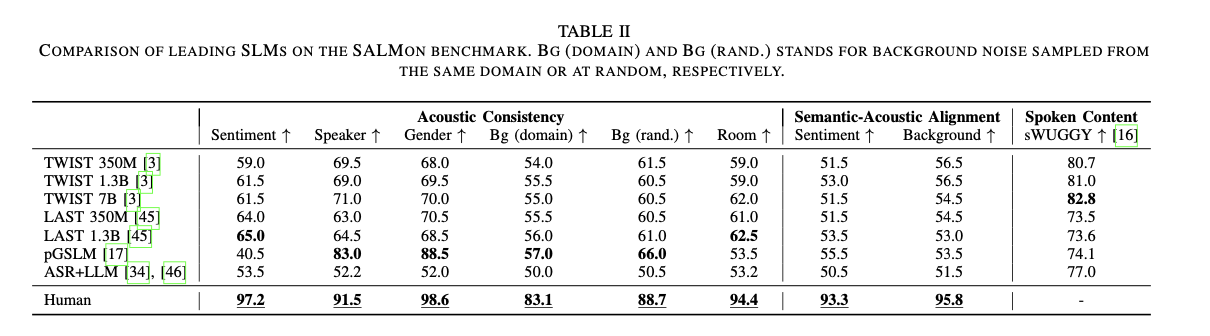
Concluindo, o SALMON fornece uma estrutura abrangente para testar a modelagem acústica em modelos de fala e linguagem, abordando a lacuna deixada pelos métodos de teste convencionais que se concentram principalmente na coerência do texto. Ao introduzir benchmarks que avaliam a consistência acústica e o alinhamento semântico-acústico, o SALMON permite aos investigadores identificar os pontos fortes e fracos dos modelos em várias dimensões acústicas. Os resultados mostram que embora os modelos atuais possam lidar com determinadas tarefas, eles ficam muito aquém do desempenho humano em situações mais complexas. Como resultado, espera-se que o SALMON direcione pesquisas futuras e desenvolvimento de modelos para modelos mais conscientes acusticamente e contextualmente aprimorados, ampliando os limites do que os SLMs podem alcançar em aplicações do mundo real.
Confira Página de papel e GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)
Aswin AK é consultor da MarkTechPost. Ele está cursando seu diploma duplo no Instituto Indiano de Tecnologia, Kharagpur. Ele é apaixonado por ciência de dados e aprendizado de máquina, o que traz consigo uma sólida formação acadêmica e experiência prática na solução de desafios de domínio da vida real.
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)


