
Os Modelos de Linguagem em Grande Escala (LLMs) revolucionaram a IA generativa, mostrando capacidades notáveis na geração de respostas semelhantes às humanas. No entanto, estes modelos enfrentam um desafio importante conhecido como alucinação, a tendência de produzir informações incorretas ou irrelevantes. Este problema representa um risco significativo para aplicações de ponta, como avaliação médica, processamento de reclamações de seguros e sistemas automatizados de tomada de decisão, onde a precisão é crítica. O problema das alucinações visuais vai além dos modelos baseados em texto, chegando aos modelos de linguagem visual (VLMs) que processam imagens e consultas de texto. Apesar de desenvolverem VLMs robustos, como LLaVA, InstructBLIP e VILA, esses programas lutam para gerar respostas precisas com base na entrada de imagens e nas consultas do usuário.
No presente estudo apresentamos vários métodos para lidar com objetos faltantes em modelos de linguagem. Para sistemas baseados em texto, o FactScore melhorou a precisão ao dividir declarações longas em unidades atômicas para melhor verificação. Lockback Lens desenvolveu um método de análise de pontos de atenção para detectar manipulação contextual, enquanto MARS usou um sistema ponderado que se concentrava em partes importantes da declaração. Especificamente nos programas RAG, o RAGAS e o LlamaIndex surgiram como ferramentas de avaliação, o RAGAS se concentra na precisão e consistência das respostas usando avaliadores humanos, enquanto o LlamaIndex usa o GPT-4 para avaliar a confiabilidade. No entanto, não existem trabalhos existentes que forneçam pontos de visualização diretamente para sistemas RAG multimodais, onde o conteúdo inclui múltiplos dados multimodais.
Pesquisadores da Universidade de Maryland, College Park, MD, e NEC Laboratories America, Princeton, NJ propuseram o RAG-check, um método abrangente para testar sistemas RAG com múltiplas condições. Consiste em três componentes principais projetados para avaliar a consistência e a precisão. A primeira parte envolve uma rede neural que avalia a relevância de cada dado retornado da consulta do usuário. A segunda parte usa um algoritmo de segmentação e separa a saída RAG em espaços em branco (objeto) e espaços em branco (assunto). A terceira parte usa outra rede neural para testar a precisão do intervalo alvo em relação ao conteúdo bruto, que pode incluir texto e imagens convertidas em um formato baseado em texto por VLMs.
A arquitetura de verificação do RAG utiliza duas métricas de avaliação principais: o Suitability Score (RS) e o Suitability Score (CS) para avaliar diferentes aspectos do desempenho do sistema RAG. Para testar os métodos de seleção, o sistema analisa as pontuações de relevância das 5 principais imagens recuperadas de um conjunto de teste de 1.000 consultas, fornecendo insights sobre o desempenho de diferentes métodos de recuperação. Em termos de geração de contexto, a arquitetura permite a integração flexível de combinações de diferentes modelos, seja VLMs separados (como LLaVA ou GPT4) e LLMs (como LLAMA ou GPT-3.5), ou MLLMs combinados, como -GPT-4. Esta flexibilidade permite uma avaliação abrangente das propriedades dos diferentes modelos e do seu impacto na qualidade da resposta.
Os resultados dos testes mostram diferenças significativas de desempenho entre os tipos de sistema RAG. Ao utilizar modelos CLIP como codificadores de percepção com similaridade de cosseno na seleção de imagens, a pontuação média varia de 30% a 41%. No entanto, usar o modelo RS para avaliar o par de imagens melhora significativamente a pontuação de compatibilidade para entre 71% e 89,5%, embora ao custo de um aumento de 35 vezes nos requisitos de computação ao usar a GPU A100. GPT-4o surge como a melhor configuração para produção de conteúdo e taxas de erro, superando outras configurações em 20%. As demais configurações RAG apresentam desempenho semelhante, com taxa de precisão entre 60% e 68%.
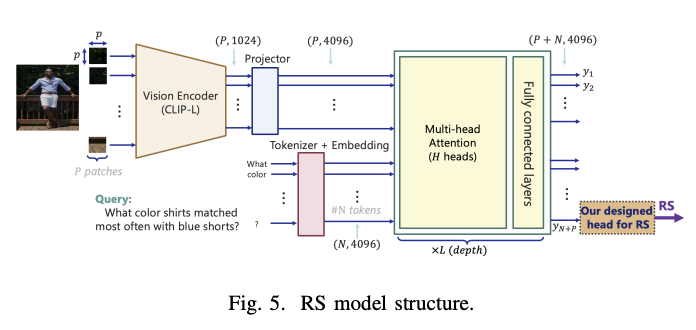
Concluindo, os pesquisadores RAG-check, uma nova estrutura de avaliação para muitos sistemas RAG para enfrentar o importante desafio de detecção de anomalias em múltiplas imagens e entrada de texto. A estrutura de três partes da estrutura, incluindo pontuações de relevância, segmentação de tempo e testes de precisão, mostra uma melhoria significativa na avaliação de desempenho. Os resultados revelam que embora o modelo RS melhore significativamente a pontuação relativa de 41% para 89,5%, ele acarreta um aumento no custo computacional. Entre as diversas configurações testadas, o GPT-4o emergiu como o modelo de contextualização mais eficaz, destacando o poder dos modelos multilíngues integrados na melhoria da precisão e confiabilidade do sistema RAG.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 65k + ML.
🚨 PRÓXIMO WEBINAR GRATUITO DE IA (15 DE JANEIRO DE 2025): Aumente a precisão do LLM com dados artificiais e inteligência experimental–Participe deste webinar para obter insights práticos sobre como melhorar o desempenho e a precisão do modelo LLM e, ao mesmo tempo, proteger a privacidade dos dados.

Sajjad Ansari se formou no último ano do IIT Kharagpur. Como entusiasta da tecnologia, ele examina as aplicações da IA com foco na compreensão do impacto das tecnologias de IA e suas implicações no mundo real. Seu objetivo é transmitir conceitos complexos de IA de maneira clara e acessível.
✅ [Recommended Read] Nebius AI Studio se expande com modelos de visão, novos modelos de linguagem, incorporados e LoRA (Aprimorado)

")
