
Os modelos linguísticos de grande escala (LLMs) têm recebido atenção significativa no aprendizado de máquina, mudando o foco da melhoria da generalização em pequenos conjuntos de dados para a redução do erro de estimativa em grandes dados textuais. Esta mudança de paradigma apresenta aos investigadores novos desafios no desenvolvimento de modelos e métodos de formação. O principal objetivo é evitar o overfitting usando técnicas de normalização para dimensionar modelos de maneira eficaz para usar grandes quantidades de dados. Os investigadores enfrentam agora o desafio de medir as restrições do computador e a necessidade de melhorar o desempenho nas tarefas seguintes. Esta evolução exige uma revisão dos métodos tradicionais e o desenvolvimento de estratégias robustas para aproveitar o poder da formação linguística em larga escala, tendo simultaneamente em conta as limitações impostas pelos recursos informáticos disponíveis.
A mudança de um paradigma centrado no geral para um paradigma centrado no escalonamento no aprendizado de máquina exigiu uma revisão das abordagens padrão. Os pesquisadores do Google DeepMind identificaram uma diferença fundamental entre esses paradigmas, que se concentram na redução do erro de medição em vez do erro de generalização em geral. Esta mudança desafia a sabedoria convencional, uma vez que as práticas que funcionaram bem num paradigma centrado na generalização podem não produzir bons resultados numa abordagem centrada na medição. O fenómeno da “lei da proporcionalidade cruzada” complica ainda mais a situação, uma vez que as estratégias que melhoram o desempenho em pequenas escalas podem não se traduzir eficazmente em escalas maiores. Para mitigar estes desafios, os investigadores propõem desenvolver novos princípios e métodos para orientar os esforços de escala e comparar com sucesso modelos em escalas sem precedentes, onde a realização de múltiplas experiências muitas vezes não é possível.
O aprendizado de máquina visa desenvolver funções que possam fazer previsões precisas sobre dados abstratos, compreendendo a estrutura subjacente dos dados. Esta técnica envolve minimizar a perda de teste em dados não observados enquanto se aprende com o conjunto de treinamento. O erro experimental pode ser dividido em desvio padrão e erro de medição (erro de treinamento).
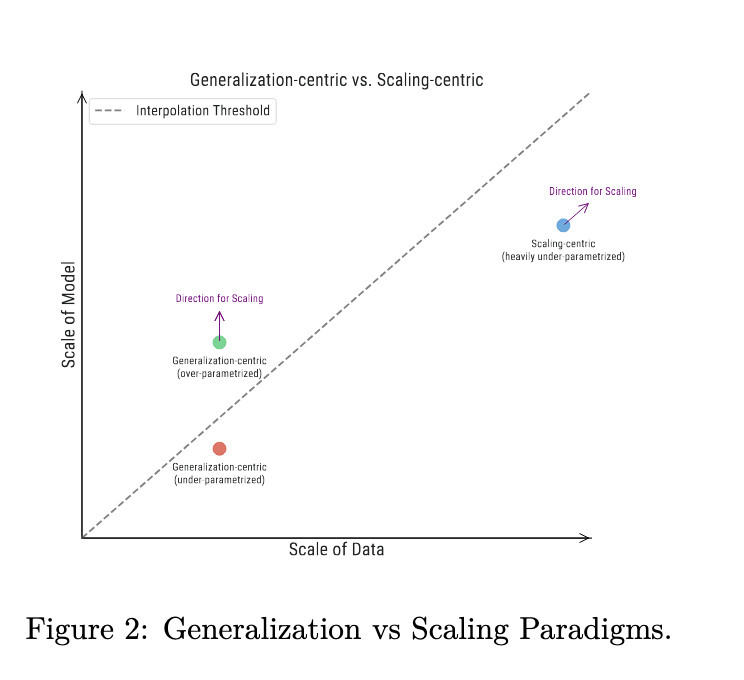
Dois paradigmas diferentes surgiram no aprendizado de máquina, diferenciados pela escala relativa e absoluta de dados e modelos:
1. O paradigma centrado na generalização, que funciona em escalas de dados menores, é ainda dividido em dois subparadigmas:
a) O esquema clássico de compensação entre viés e variância, onde a capacidade dos modelos é intencionalmente restrita.
b) Um sistema moderno sobreparametrizado, onde a escala do modelo excede em muito a escala dos dados.
2. Um paradigma centrado na escalabilidade, caracterizado por big data e escalas de modelos, e escalas de dados que excedem as escalas de modelos.
Estes paradigmas apresentam diferentes desafios e requerem diferentes abordagens para melhorar o desempenho dos modelos e alcançar os resultados desejados.
O método proposto usa uma arquitetura de transformador somente decodificador treinado no conjunto de dados C4, usando a base de código NanoDO. Os principais recursos arquitetônicos incluem incorporação posicional rotativa, cálculo de atenção QK-Norm e cabeça não vinculada e pesos de incorporação. O modelo utiliza ativação Gelu com F = 4D, onde D é a dimensão do modelo e F é a dimensão oculta do MLP. As cabeças de atenção são configuradas com um tamanho de cabeça de 64 e o comprimento da sequência é definido como 512.
O tamanho da palavra do modelo é 32.101, e o número total de parâmetros é de aproximadamente 12D²L, onde L é o número de camadas do transformador. A maioria dos modelos foi treinada para eficiência da Chinchilla, usando tokens 20 × (12D²L + DV). Os requisitos computacionais são estimados usando a fórmula F = 6ND, onde F representa o número de operações de ponto flutuante.
Para otimização, o método usa AdamW com β1 = 0,9, β2 = 0,95, ϵ = 1e-20 e decaimento de peso integrado λ = 0,1. Esta combinação de escolhas arquitetônicas e técnicas de otimização visa melhorar o desempenho do modelo em um paradigma centrado no escalonamento.
No paradigma centrado no escalonamento, as estratégias de práticas comuns são revisadas em busca de eficiência. Três métodos de generalização populares frequentemente usados no paradigma centrado na generalização são a generalização L2 implícita e os efeitos de generalização implícitos para grandes taxas de aprendizagem e pequenos tamanhos de coorte. Essas técnicas contribuíram para reduzir o overfitting e diminuir a lacuna entre o treinamento e a perda de teste em modelos com dimensões pequenas.
No entanto, no contexto de modelos de linguagem de grande escala e do paradigma centrado na escala, a necessidade destas adaptações é questionável. Uma vez que os modelos operam num regime onde o overfitting não é uma preocupação devido à grande quantidade de dados de treino, os benefícios habituais da normalização podem já não se aplicar. Esta mudança incentiva os pesquisadores a reconsiderar o papel da normalização no treinamento de modelos e a explorar alternativas que possam ser mais apropriadas ao paradigma centrado no escalonamento.
O paradigma centrado no escalonamento apresenta desafios únicos na comparação de modelos, uma vez que os métodos convencionais de validação não funcionam em grandes escalas. A ocorrência de cruzamento de leis de escala complica ainda mais as coisas, uma vez que os níveis de desempenho observados em pequenas escalas podem não ser verdadeiros para modelos maiores. Isto levanta a importante questão de como comparar modelos de forma eficaz quando a formação só pode ocorrer uma vez em escala.
Em contraste, o paradigma centrado na generalização depende fortemente da familiaridade como princípio orientador. Essa abordagem levou a insights sobre a seleção de hiperparâmetros, os efeitos da decomposição de peso e os benefícios da hiperparametrização. Também descreve a eficácia de técnicas como compartilhamento de peso em CNNs, localidade e classificação em arquiteturas de redes neurais.
No entanto, um paradigma centrado no dimensionamento pode exigir novos princípios orientadores. Embora a normalização tenha sido importante na compreensão e desenvolvimento da normalização em modelos de pequena escala, o seu papel e eficácia em modelos de linguagem de grande escala estão a ser reexaminados. Os investigadores são agora desafiados a desenvolver métodos e princípios rigorosos que possam orientar o desenvolvimento e comparação de modelos neste novo paradigma, onde os métodos tradicionais podem já não ser aplicáveis.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso SubReddit de 52k + ML.
Convidamos startups, empresas e institutos de pesquisa que trabalham em modelos de microlinguagem para participar deste próximo projeto Revista/Relatório 'Modelos de Linguagem Pequena' Marketchpost.com. Esta revista/relatório será lançada no final de outubro/início de novembro de 2024. Clique aqui para agendar uma chamada!
Asjad é consultor estagiário na Marktechpost. Ele está cursando B.Tech em engenharia mecânica no Instituto Indiano de Tecnologia, Kharagpur. Asjad é um entusiasta do aprendizado de máquina e do aprendizado profundo que pesquisa regularmente a aplicação do aprendizado de máquina na área da saúde.


