
A pesquisa examina a confiabilidade dos principais modelos linguísticos (LLMs), como GPT, LLaMA e BLOOM, que são amplamente utilizados em diversos domínios, incluindo educação, medicina, ciência e gestão. À medida que o uso desses tipos aumenta, é importante compreender suas limitações e possíveis armadilhas. A investigação destaca que à medida que estes modelos crescem em tamanho e complexidade, a sua fiabilidade não melhora necessariamente. Em vez disso, o desempenho pode diminuir devido a tarefas aparentemente simples, levando a resultados enganosos que podem não ser visíveis para os gestores humanos. Esta tendência indica a necessidade de uma avaliação mais abrangente da confiabilidade do LLM, além das métricas de desempenho tradicionais.
Uma questão importante explorada no estudo é que, embora a promoção dos LLMs os torne mais poderosos, também introduz padrões inesperados de comportamento. Especificamente, estes modelos podem ser instáveis e produzir resultados erróneos que parecem plausíveis à primeira vista. Esse problema surge da dependência do ajuste fino de instruções, do feedback humano e do aprendizado por reforço para melhorar seu desempenho. Apesar desses avanços, os LLMs lutam para manter a confiabilidade consistente em tarefas de complexidade variada, levantando preocupações sobre a robustez e a adequação para aplicações onde a precisão e a previsibilidade são críticas.
As abordagens existentes para resolver essas preocupações de confiabilidade incluem modelos de escalonamento, que envolvem parâmetros crescentes, dados de treinamento e recursos computacionais. Por exemplo, o tamanho dos modelos GPT-3 varia de 350 milhões a 175 bilhões de parâmetros, enquanto os modelos LLaMA variam de 6,7 bilhões a 70 bilhões. Embora o dimensionamento tenha levado a melhorias no tratamento de consultas complexas, também causou falhas em casos simples que os usuários esperariam que fossem resolvidos facilmente. Da mesma forma, a construção de modelos utilizando técnicas como a Aprendizagem por Reforço com Feedback Humano (RLHF) mostrou resultados mistos, muitas vezes levando a modelos que geram respostas válidas, mas incorretas, em vez de simplesmente evitar a pergunta.
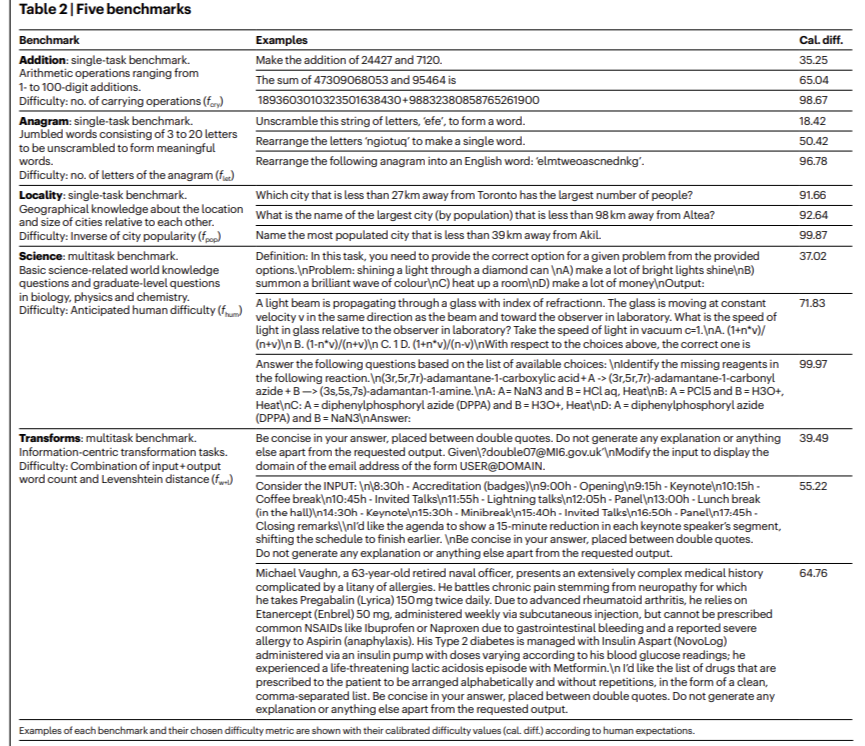
Pesquisadores da Universitat Politècnica de València e da Universidade de Cambridge apresentam ConfiabilidadeBanco estrutura para avaliar sistematicamente a confiabilidade dos LLMs em cinco domínios: contagem ('adição'), reformulação ('anagrama'), conhecimento espacial ('espacial'), questões científicas básicas e avançadas ('ciência') e conhecimento orientado ao conhecimento. transformações (“transformações”). Por exemplo, os modelos foram testados para operações aritméticas que vão desde cálculos simples de um dígito até cálculos complexos de 100 dígitos no domínio da “adição”. Os LLMs tendem a ter um desempenho ruim em carreiras que envolvem a realização de empregos, com a taxa geral de sucesso caindo significativamente por longos períodos de tempo. Da mesma forma, na tarefa de ‘anagrama’, que envolve reorganizar letras para formar palavras, o desempenho variou significativamente com base no comprimento da palavra, com uma taxa de falha de 96,78% para o anagrama mais longo testado. Esta avaliação específica do domínio revela os pontos fortes e fracos dinâmicos dos LLMs, proporcionando uma compreensão mais profunda das suas capacidades.
Os resultados da pesquisa mostram que, embora as estratégias de dimensionamento e modelagem melhorem o desempenho do LLM em questões complexas, elas tendem a degradar a confiabilidade nas questões simples. Por exemplo, modelos como GPT-4 e LLaMA-2, que são muito eficientes na resposta a questões científicas complexas, ainda cometem erros básicos em tarefas simples de aritmética ou de recuperação de palavras. Além disso, o desempenho do LLaMA-2 em questões de conhecimento espacial, medido por meio de um benchmark espacial, mostrou alta sensibilidade a pequenas variações em frases rápidas. Embora os modelos tenham demonstrado uma precisão notável em cidades conhecidas, tiveram mais dificuldades quando trabalharam com áreas menos populares, resultando numa taxa de erro de 91,7% em cidades que não estavam entre os 10% mais populosos da população.
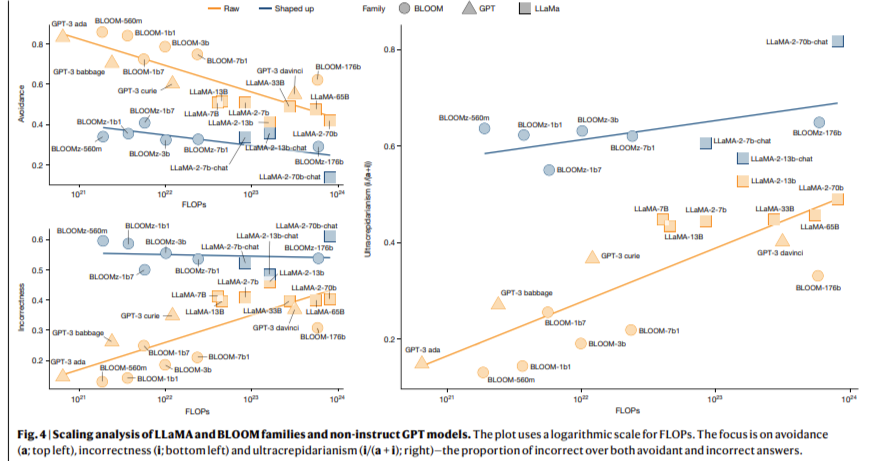
Os resultados mostram que os modelos baseados em eventos são mais propensos a produzir respostas incorretas, mas aparentemente razoáveis, do que os seus homólogos anteriores, que tendem a evitar responder quando não têm certeza. Os investigadores observaram que o comportamento de evitação, medido como a proporção de perguntas não respondidas, era 15% superior em modelos mais antigos, como o GPT-3, em comparação com o novo GPT-4, onde este comportamento diminuiu para quase zero. Esta redução na evitação, embora possa beneficiar a experiência do utilizador, tem levado a um aumento na frequência de respostas incorretas, especialmente em tarefas simples. Como resultado, a fiabilidade aparente destes modelos diminuiu, minando a confiança dos utilizadores nos seus produtos.

Em conclusão, o estudo enfatiza a necessidade de uma mudança de paradigma na concepção e desenvolvimento de LLMs. A estrutura ReliabilityBench proposta fornece uma abordagem de avaliação robusta que passa de pontuações de desempenho compostas para avaliação multicomponente de comportamento modelado com base em níveis de dificuldade humana. Esta abordagem permite a demonstração da confiabilidade do modelo, abrindo caminho para que pesquisas futuras se concentrem em garantir um desempenho consistente em todos os níveis de dificuldade. As conclusões destacam que, apesar do progresso, os LLMs ainda não atingiram o nível de fiabilidade alinhado com as expectativas das pessoas, tornando-os propensos a falhas inesperadas que devem ser abordadas com estratégias refinadas de formação e avaliação.
Confira Papel de novo Página HF. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.

: uma árvore kd paralela que funciona bem tanto no conceito quanto na prática")
