
Modelos linguísticos de grande escala (LLMs) têm recebido atenção significativa no campo da inteligência artificial, principalmente devido à sua capacidade de simular o conhecimento humano usando extensos conjuntos de dados. Os métodos atuais para treinar esses modelos dependem fortemente de simulação, especificamente a previsão do próximo token usando a razão de máxima verossimilhança (MLE) durante as fases de treinamento e fases supervisionadas de ajuste fino. No entanto, esta abordagem enfrenta vários desafios, incluindo erros automáticos de integração do modelo, viés de exposição e mudanças distributivas durante a implementação do modelo iterativo. Estas questões tornam-se mais proeminentes na sucessão a longo prazo, o que pode levar a um desempenho prejudicado e ao desalinhamento do propósito de alguém. À medida que o campo evolui, há uma necessidade crescente de enfrentar estes desafios e desenvolver formas eficazes de treinar e alinhar os LLMs com as preferências e objetivos das pessoas.
Os esforços existentes para enfrentar os desafios no treinamento de modelos de linguagem concentram-se em duas abordagens principais: clonagem comportamental (BC) e aprendizagem por reforço inverso (IRL). BC, assim como a configuração bem supervisionada com MLE, simula diretamente exibições de especialistas, mas sofre de erros de agrupamento e requer extensa entrada de dados. A IRL, por outro lado, integra conjuntamente o trabalho político e de premiação, superando potencialmente as limitações do BC por meio de uma colaboração mais local. Os métodos IRL recentes incluíram métodos de teoria dos jogos, regularização de entropia e várias técnicas de otimização para melhorar a estabilidade e robustez. No contexto da modelagem de linguagem, alguns pesquisadores exploraram métodos alternativos de treinamento, como o SeqGAN, como alternativas ao MLE. No entanto, estes métodos têm mostrado sucesso limitado, sendo eficazes apenas em determinados regimes de temperatura. Apesar destes esforços, a área continua a procurar soluções mais robustas e confiáveis para treinar e alinhar modelos linguísticos de grande escala.
Os pesquisadores da DeepMind propõem uma investigação intensiva da implementação completa de modelos baseados em RL, especialmente focados na teoria de distribuição uniforme de IRL, para a otimização de grandes modelos de linguagem. Esta abordagem visa fornecer uma alternativa viável ao MLE padrão. A pesquisa inclui métodos adversários e não adversários, bem como técnicas offline e online. Uma inovação fundamental é a expansão do leitura suave do Q oposto estabelecer comunicação sistemática através da clonagem de comportamento clássico ou MLE. O estudo examina modelos que variam de parâmetros de 250M a 3B, incluindo arquiteturas codificador-decodificador T5 e PaLM2 somente decodificador. Ao examinar o desempenho de tarefas e a diversidade intergeracional, o estudo procura demonstrar os benefícios da IRL sobre a integração comportamental na simulação de aprendizagem de modelos de linguagem. Além disso, o estudo examina o potencial das funções de recompensa derivadas da IRL para preencher a lacuna com os estágios posteriores da RLHF.
A metodologia proposta apresenta uma maneira única de ajustar o modelo de linguagem, reprogramando o soft learning inverso Q como a diferença de tempo da expansão MLE padrão. Esta abordagem preenche a lacuna entre o MLE e os algoritmos que aproveitam a natureza sequencial da geração da linguagem.
Uma abordagem para modelar a produção de linguagem como um problema de sequência de tomada de decisão, onde a produção do próximo token é determinada pela sequência gerada anteriormente. Os investigadores centram-se na redução da divergência entre a distribuição da acção estatal descontada γ da política e a da política especializada, combinada com um termo de entropia causal ponderado.
A formulação usa divergência χ2 e minimiza a função de valor, o que leva ao objetivo IQLearn:
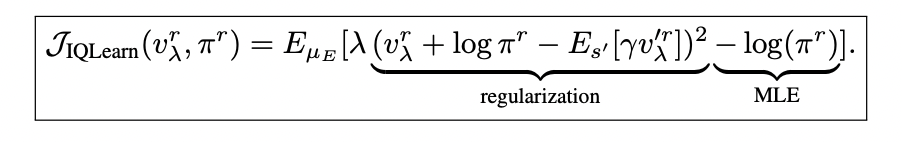
Este objetivo consiste em duas partes principais:
1. Um termo de parametrização que combina a política aprendida a partir da função de valor, selecionando políticas onde as probabilidades logarítmicas das ações são iguais à diferença dos valores de estado.
2. O termo MLE que mantém o modelo de comunicação e treinamento do idioma nativo.
É importante ressaltar que esta formulação permite a minimização do termo de normalização, proporcionando flexibilidade na aproximação entre o MLE padrão (λ = 0) e a otimização robusta. Este método permite o treinamento offline usando apenas amostras de especialistas, o que pode melhorar a eficiência do computador no ajuste fino do modelo de linguagem.
Os pesquisadores conduziram extensos experimentos para testar a eficácia dos métodos IRL em comparação com o MLE para o ajuste fino de grandes modelos de linguagem. Seus resultados mostram várias descobertas importantes:
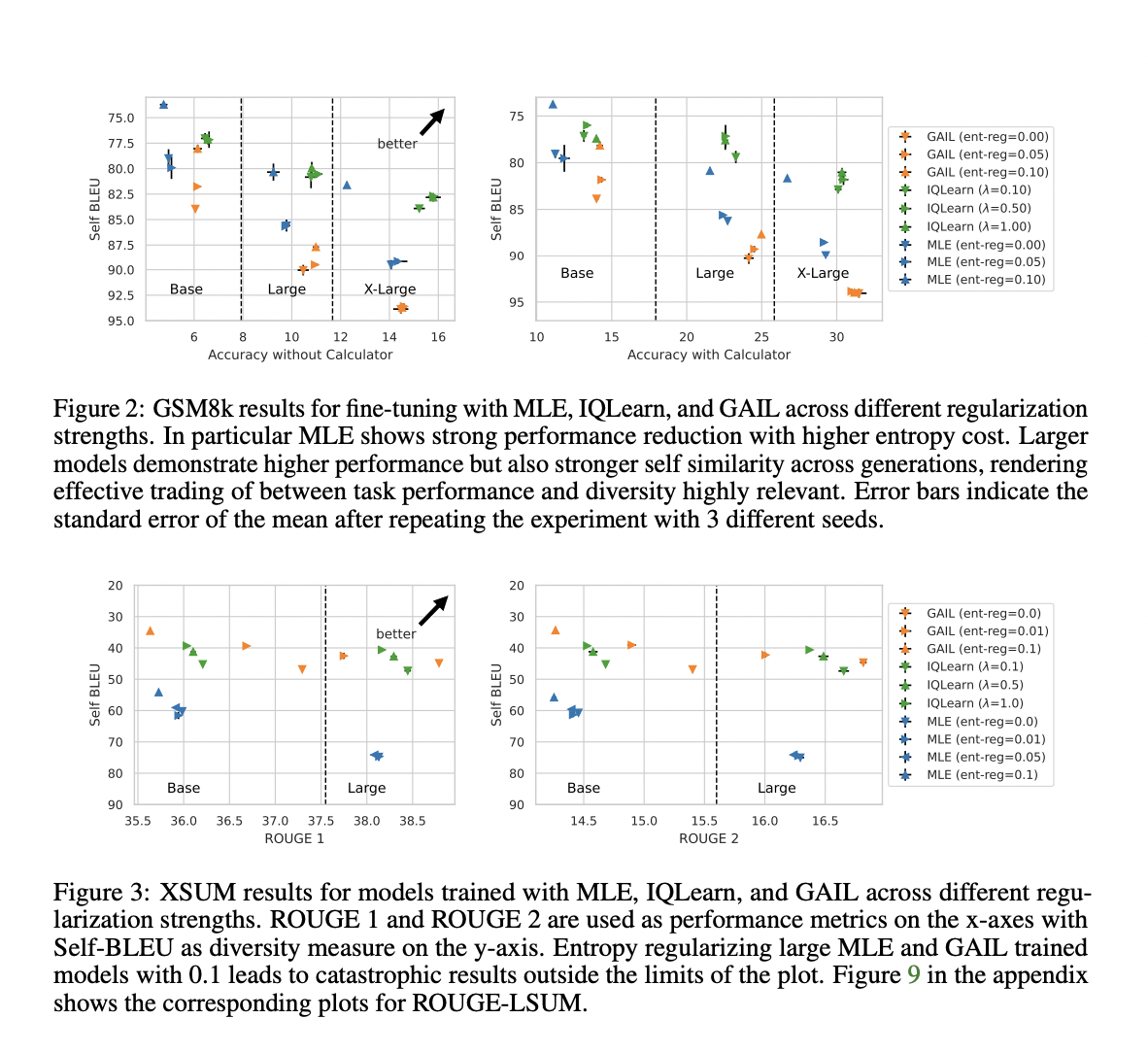
1. Melhoria de desempenho: os métodos IRL, especialmente IQLearn, mostraram ganhos pequenos, mas significativos, no desempenho de tarefas em vários benchmarks, incluindo XSUM, GSM8k, TLDR e WMT22. Esta melhoria foi particularmente destacada nas tarefas matemáticas e de raciocínio.
2. Melhoria da diversidade: o IQLearn produziu consistentemente gerações de modelos mais diversificadas em comparação com o MLE, conforme medido pelas pontuações mais baixas do Self-BLEU. Isto indica um melhor equilíbrio entre o desempenho do trabalho e a diversidade de resultados.
3. Avaliação do modelo: As vantagens dos métodos IRL foram observadas em todos os modelos de diferentes modelos e estruturas, incluindo modelos T5 (base, grande e xl) e PaLM2.
4. Sensibilidade à temperatura: Para os modelos PaLM2, o IQLearn alcançou alto desempenho em configurações de amostragem de baixa temperatura para todas as funções testadas, sugerindo maior estabilidade na qualidade da produção.
5. Dependência de busca de feixe: IQLearn demonstrou a capacidade de reduzir a dependência de busca de feixe durante a previsão, mantendo o desempenho, proporcionando potencialmente ganhos de eficiência computacional.
6. Desempenho do GAIL: Embora estável para os modelos T5, o GAIL provou ser um desafio para a implementação bem-sucedida dos modelos PaLM2, destacando a robustez do método IQLearn.
Esses resultados sugerem que os métodos IRL, especialmente o IQLearn, fornecem uma alternativa escalável e eficiente ao MLE para o ajuste fino de grandes modelos de linguagem, proporcionando melhorias no desempenho de tarefas e na diversidade intergeracional em uma variedade de tarefas e estruturas de modelos.
Este artigo investiga o potencial dos algoritmos IRL para o ajuste fino de modelos de linguagem, com foco em desempenho, diversidade e eficiência computacional. Os pesquisadores apresentam um algoritmo IQLearn redesenhado, que permite uma abordagem equilibrada entre o ajuste supervisionado tradicional e métodos IRL avançados. As experiências revelam melhorias significativas no equilíbrio entre o desempenho no trabalho e a variabilidade da produtividade utilizando a IRL. Estudos mostram de forma esmagadora que a computação IRL off-line eficiente alcança ganhos significativos de desempenho com otimização baseada em MLE sem exigir amostragem on-line. Além disso, a análise das correlações entre as recompensas emitidas pela IRL e as métricas de desempenho sugere o potencial para desenvolver funções de recompensa mais precisas para modelagem de linguagem, abrindo caminho para um melhor treinamento e alinhamento do modelo de linguagem.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)
Asjad é consultor estagiário na Marktechpost. Ele está cursando B.Tech em engenharia mecânica no Instituto Indiano de Tecnologia, Kharagpur. Asjad é um entusiasta do aprendizado de máquina e do aprendizado profundo que pesquisa regularmente a aplicação do aprendizado de máquina na área da saúde.
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)


