
Os modelos de linguagem em larga escala (LLMs) revolucionaram o processamento de linguagem natural, permitindo que os sistemas de IA executem uma variedade de tarefas com experiência incrível. No entanto, os investigadores enfrentam desafios significativos na melhoria do desempenho do LLM, especialmente na interação humana com o LLM. Uma observação importante revela que a qualidade das respostas do LLM tende a melhorar com solicitações repetidas e feedback do usuário. Os métodos atuais baseiam-se frequentemente em conhecimentos ingênuos, levando a erros de medição e subestimações. Isto apresenta um problema importante: desenvolver técnicas de validação mais avançadas que possam melhorar significativamente a precisão e confiabilidade dos resultados do LLM, aumentando assim o seu potencial em diversas aplicações.
Os pesquisadores têm tentado superar os desafios na melhoria do desempenho do LLM por meio de diversas estratégias de informação. O método Input-Output (IO) representa o método mais básico, usando um método de saída direta sem lógica intermediária. Esta abordagem, no entanto, muitas vezes falha em tarefas complexas que requerem entendimentos diferentes. A teoria da cadeia de pensamento (CoT) surgiu como um desenvolvimento, apresentando uma forma única e direta de pensar. Esta abordagem incentiva os LLMs a expressar etapas intermediárias de pensamento, levando a um melhor desempenho em tarefas complexas. Com base nisso, os métodos Tree-of-Thought (ToT) ampliam o conceito examinando múltiplas formas de pensar em paralelo, criando estruturas ramificadas para melhorar os resultados. Este método mostrou alguma eficiência em tarefas experimentais, como resolução de quebra-cabeças. Além disso, outras estruturas, como o auto-refinamento e a auto-validação, permitem que os LLMs analisem e refinem os seus resultados de forma iterativa. No entanto, estes métodos ainda dependem de informações estáticas ou semi-estáticas, o que limita a sua flexibilidade em situações dinâmicas. Apesar destes avanços, os métodos atuais lutam para utilizar plenamente a base de conhecimento interna do LLM e adaptar-se de forma flexível ao contexto de cada pergunta e resposta única.
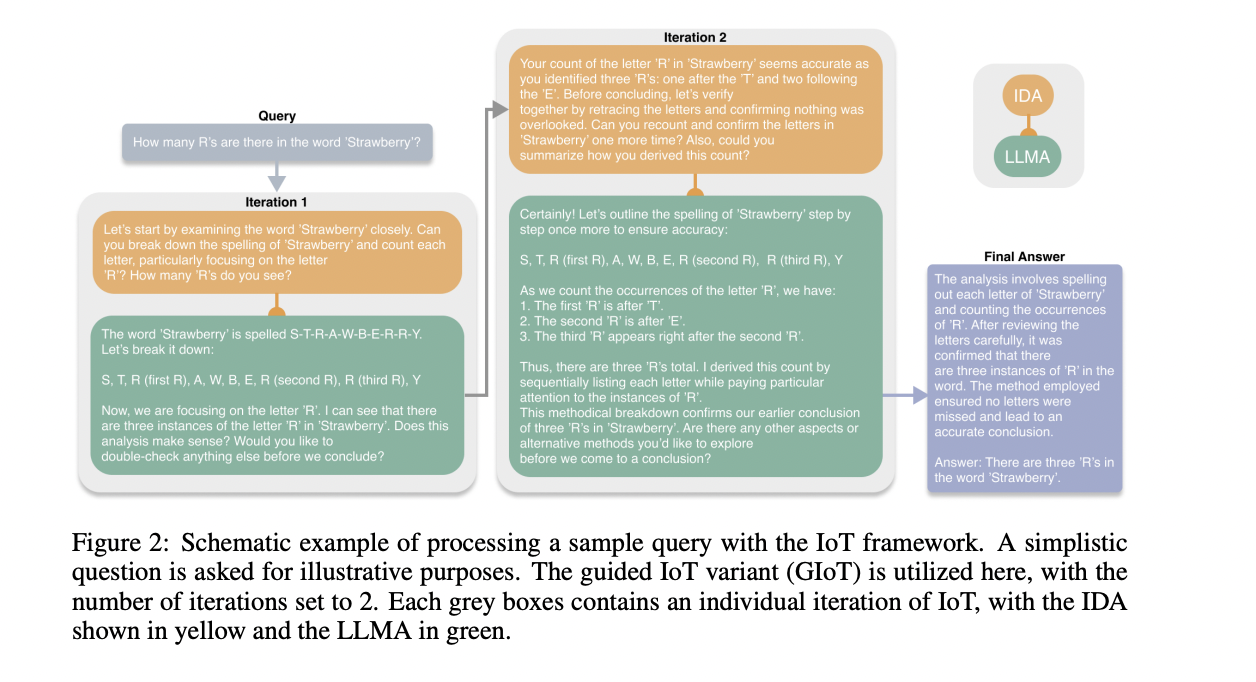
Pesquisadores da Agnostiq Inc. e a Universidade de Toronto apresentaram Iteração de Pensamento (IoT) estrutura, uma abordagem independente, iterativa e flexível para o pensamento LLM sem feedback humano. Ao contrário das estruturas estáticas e semi-estáticas, a IoT utiliza um Agente de Diálogo Interno (IDA) para modificar e refinar seu pensamento durante cada iteração. Isso permite testes flexíveis em árvores de raciocínio, o que incentiva um processo de resposta flexível e consciente do contexto. Além disso, a estrutura principal da IoT consiste em três componentes principais: IDA, LLM Agent e Iterative Prompting Loop. O IDA atua como um guia, gerando dinamicamente informações sensíveis ao contexto com base em perguntas reais do usuário e feedback anterior do LLM. LLMA combina os recursos lógicos básicos do LLM, processando comandos gerados pelo poder do IDA. O Iterative Prompting Loop facilita a interação entre IDA e LLMA, melhorando continuamente a qualidade das respostas sem contribuição externa.
A estrutura IoT é usada em duas variantes: Iteração Autônoma de Pensamento (AIoT) e Iteração Guiada de Pensamento (GIoT). A AIoT permite que o Agente LLM decida de forma autônoma quando gerou uma resposta satisfatória, potencialmente levando a testes mais rápidos, mas com o risco de parar prematuramente em questões complexas. O GIoT exige um número fixo de iterações, visando uma avaliação completa dos métodos de raciocínio ao custo de recursos computacionais adicionais. Ambas as variantes usam os principais componentes de IoT: Inner Dialogue Agent, LLM Agent e Iterative Prompting Loop. Implementada como uma biblioteca Python com Pydantic para esquemas de derivação, a IoT permite testes dinâmicos em árvores lógicas. A escolha entre AIoT e GIOT permite medir a profundidade da inspeção e a eficiência computacional com base nos requisitos da tarefa.
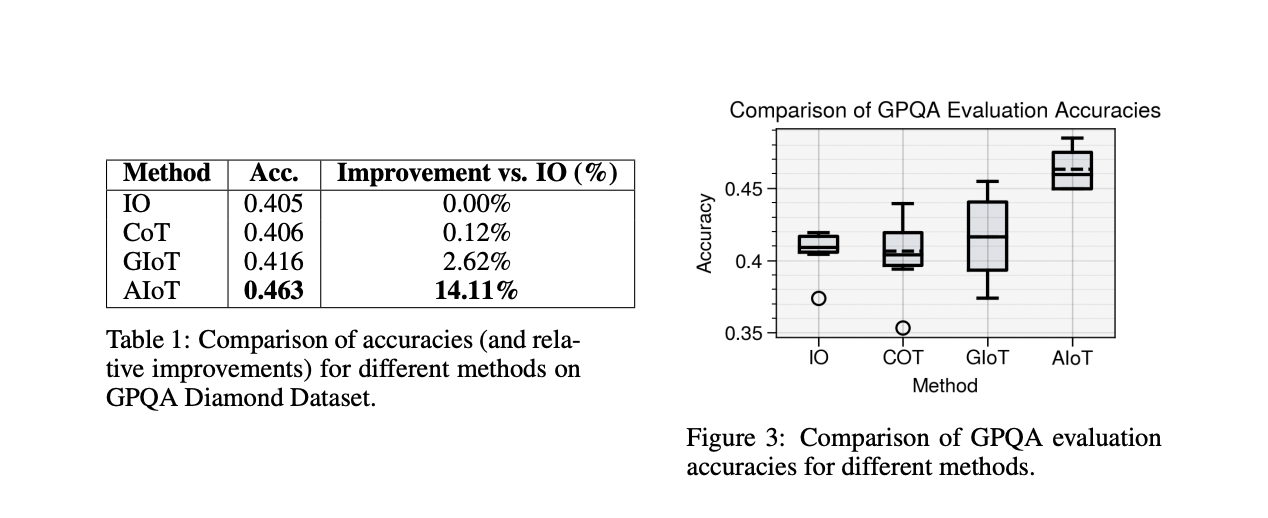
A estrutura da IoT mostra uma melhoria significativa em todas as diversas funções do pensamento. No conjunto de dados GPQA Diamond, AIoT alcançou uma precisão de melhoria de 14,11% em relação ao método básico de entrada-saída, o CoT e GIoT de melhor desempenho. Em tarefas experimentais de resolução de problemas como Jogo de 24 e Mini Palavras Cruzadas, o GIoT apresentou desempenho superior, com 266,4% e 90,6% de melhoria respectivamente em relação ao CoT. Em tarefas de raciocínio multicenário usando o conjunto de dados HotpotQA-Hard, o AIoT superou o CoT e até superou a estrutura AgentLite, alcançando um alto F1 de 0,699 e pontuações de True Similarity de 0,53. Estes resultados destacam a eficiência da IoT na adaptação a diferentes situações de raciocínio, desde tarefas de conhecimento profundo até a resposta a consultas multi-hop, mostrando o seu potencial como uma poderosa estrutura de raciocínio adaptativo para modelos linguísticos de grande escala.
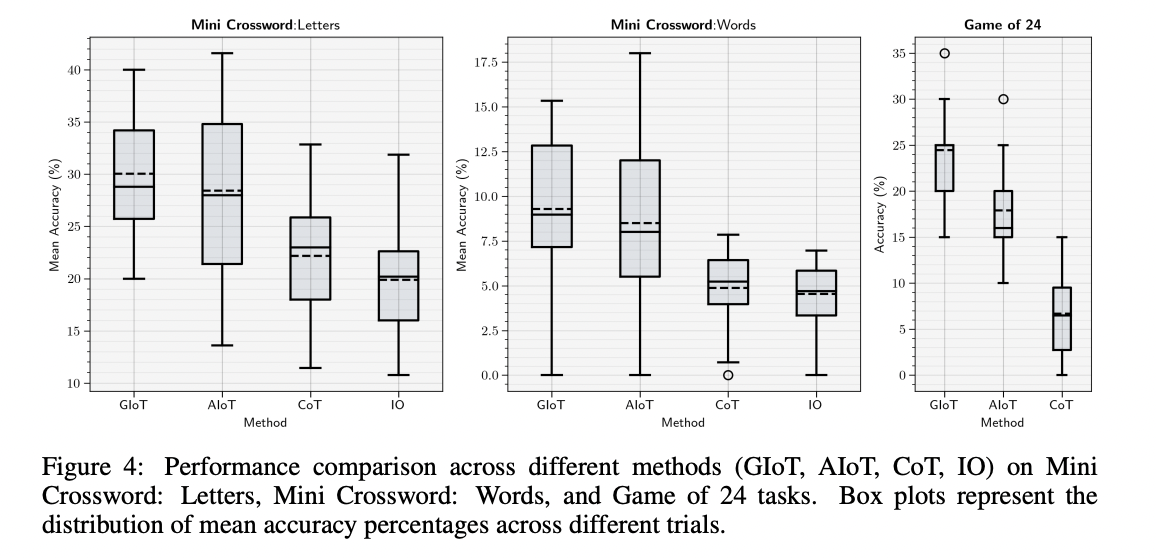
A estrutura IoT apresenta uma abordagem única para tarefas complexas de raciocínio usando modelos linguísticos de grande escala. A IoT mostra melhorias significativas em todas as diversas tarefas desafiadoras usando IIDA, que interage repetidamente com o LLM Agent. Dois tipos de frameworks, AIoT e GIoT, foram testados em vários problemas, incluindo quebra-cabeças (Jogo de 24, Mini Palavras Cruzadas) e questionários complexos (GPQA, HotpotQA). O GIoT, que realiza um número fixo de iterações, tem mais sucesso no Jogo dos 24, enquanto o AIoT, com sua conclusão autodeterminada, tem apresentado maior desempenho no GPQA. Ambas as variantes superaram a estrutura CoT em todas as tarefas comparadas. Em particular, na tarefa HotpotQA multithread, a IoT superou a estrutura hierárquica do AgentLite, alcançando uma melhoria de cerca de 35% na pontuação F1 e uma melhoria de 44% na pontuação de correspondência exata. Estes resultados sublinham a capacidade da IoT de introduzir flexibilidade produtiva em estruturas de agentes menos complexas, marcando um grande avanço nas capacidades de raciocínio do LLM.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
⏩ ⏩ WEBINAR GRATUITO DE IA: 'Vídeo SAM 2: Como sintonizar seus dados' (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)
Asjad é consultor estagiário na Marktechpost. Ele está cursando B.Tech em engenharia mecânica no Instituto Indiano de Tecnologia, Kharagpur. Asjad é um entusiasta do aprendizado de máquina e do aprendizado profundo que pesquisa regularmente a aplicação do aprendizado de máquina na área da saúde.
⏩ ⏩ WEBINAR GRATUITO DE IA: 'Vídeo SAM 2: Como sintonizar seus dados' (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)


