
Os Modelos de Linguagem em Grande Escala (LLMs) fizeram avanços significativos no processamento de grandes contextos, com alguns modelos capazes de lidar com até 10 milhões de tokens. No entanto, este desenvolvimento traz desafios à eficiência do raciocínio devido à complexidade quadrática da computação atencional. Embora o cache KV seja amplamente aceito para evitar cálculos redundantes, ele introduz maiores requisitos de memória de GPU e mais latência para instâncias longas. O modelo Llama-2-7B, por exemplo, requer cerca de 500 GB por milhão de tokens no formato FP16. Estas questões destacam a necessidade crítica de reduzir os custos de acesso e armazenamento de tokens, a fim de melhorar a eficiência da computação. A solução para esses desafios está no uso da luz dinâmica que existe no método de atenção, onde cada vetor de consulta interage estreitamente com um subconjunto limitado de vetores de chave e valor.
Os esforços existentes para acelerar a previsão LLM de contexto longo concentram-se na compactação do tamanho do cache KV usando menos atenção. No entanto, estes métodos muitas vezes levam a uma diminuição significativa na precisão devido à natureza variável do pequeno período de atenção. Outros métodos, como FlexGen e Lamina, extraem o cache KV da memória da CPU, mas enfrentam os desafios da computação lenta e exigem atenção total. Outros métodos, como Quest e InfLLM, dividem o cache KV em blocos e selecionam vetores-chave representativos, mas seu desempenho é altamente dependente da precisão desses representantes. SparQ, InfiniGen e LoKi tentam estimar as teclas top-k mais adequadas reduzindo o tamanho da cabeça.
Pesquisadores da Microsoft Research, da Shanghai Jiao Tong University e da Fudan University apresentam RecuperaçãoAtençãouma abordagem inovadora projetada para acelerar a implementação do LLM de conteúdo de longo prazo. Ele usa menos atenção dinâmica durante a geração de tokens, permitindo que os tokens mais valiosos surjam de dados de contexto mais amplos. Para enfrentar o desafio da saída distribuída (OOD), RetrievalAttention introduz um índice vetorial especialmente projetado para o método de atenção, que se concentra na distribuição da consulta em vez da similaridade central. Este método facilita o corte de apenas 1% a 3% dos vetores-chave, identificando efetivamente os tokens mais relevantes para pontos de atenção precisos e resultados de direcionamento. RetrievalAttention também otimiza o uso da memória da GPU armazenando um pequeno número de vetores KV na memória da GPU seguindo padrões estáticos, enquanto carrega a maioria na memória da CPU para construção de índice. Durante a geração de tokens, ele encontra tokens-chave usando ponteiros vetoriais para a CPU e combina resultados de atenção parcial da CPU e da GPU. Essa estratégia permite que RetrievalAttention execute o cálculo de atenção com latência reduzida e menos memória de GPU.
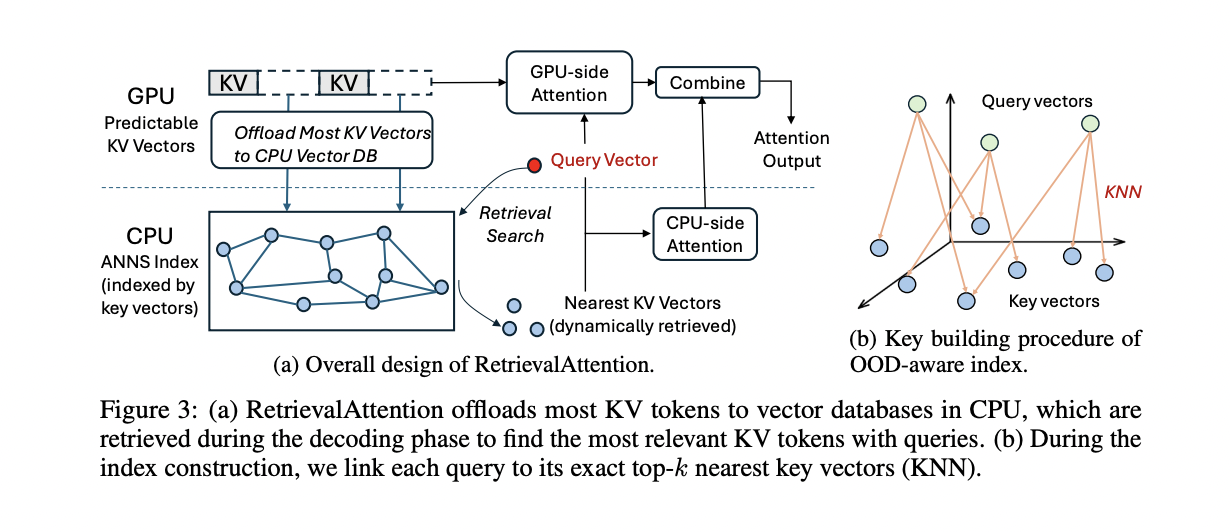
RetrievalAttention usa uma estratégia de cootimização CPU-GPU para acelerar o cálculo de atenção do LLM para conteúdo longo. O método decompõe o cálculo da atenção em dois conjuntos separados de vetores de cache KV: aqueles previstos na GPU e aqueles variáveis na CPU. Ele usa os padrões observados na fase de pré-preenchimento para prever vetores KV que são executados consistentemente durante a geração do token, persistindo-os no cache da GPU. A implementação atual usa tokens de início fixos e uma última janela de contexto deslizante como um padrão estático, semelhante ao StreamLLM. Para computação do lado da CPU, RetrievalAttention constrói um índice de pesquisa vetorial com reconhecimento de atenção para recuperar com êxito vetores KV relevantes. Este índice é construído usando correspondências KNN de vetores de consulta para vetores-chave, que são então mapeados para vetores-chave para simplificar o processo de pesquisa. Este método permite a varredura de apenas 1-3% dos vetores-chave para obter alta recuperação, reduzindo significativamente a latência de pesquisa do índice. Para reduzir a transferência de dados na interface PCIe, o RetrievalAttention calcula independentemente os resultados de atenção dos componentes da CPU e GPU antes de combiná-los, inspirado no FastAttention.
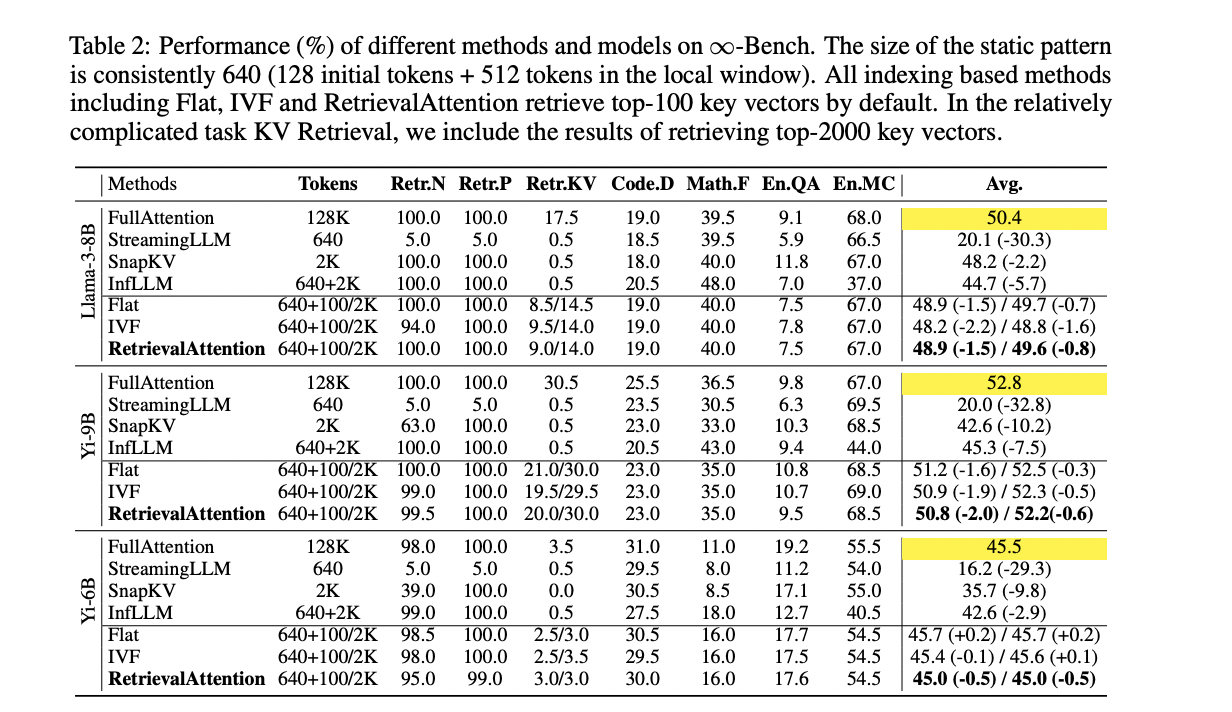
RetrievalAttention mostra desempenho superior em precisão e eficiência em comparação aos métodos existentes. Ele atinge precisão comparável e cobertura total, ao mesmo tempo que reduz significativamente o custo computacional. Para tarefas complexas como recuperação KV, RetrievalAttention supera métodos estáticos como StreamLLM e SnapKV, que não têm a capacidade de detectar tokens dinâmicos. Ele também supera o InfLLM, que tem dificuldades com a precisão devido aos vetores de representação de baixa qualidade. A capacidade do RetrievalAttention de identificar com precisão os principais vetores permite manter a precisão do alto desempenho em uma ampla variedade de comprimentos de contexto, de tokens de 4K a 128K. Em uma tarefa que precisa de um palheiro, ele se concentra efetivamente em informações críticas, independentemente da posição dentro da janela de contexto. Em termos de latência, RetrievalAttention mostra uma melhoria significativa em relação à atenção total e outros métodos. Ele atinge uma redução de latência de 4,9× e 1,98× em comparação com os índices Flat e IVF, respectivamente, no núcleo de 128K, enquanto verifica apenas 1-3% dos vetores. Essa combinação de alta precisão e baixa latência demonstra a eficiência do RetrievalAttention no tratamento de tarefas complexas e dinâmicas com contexto longo.
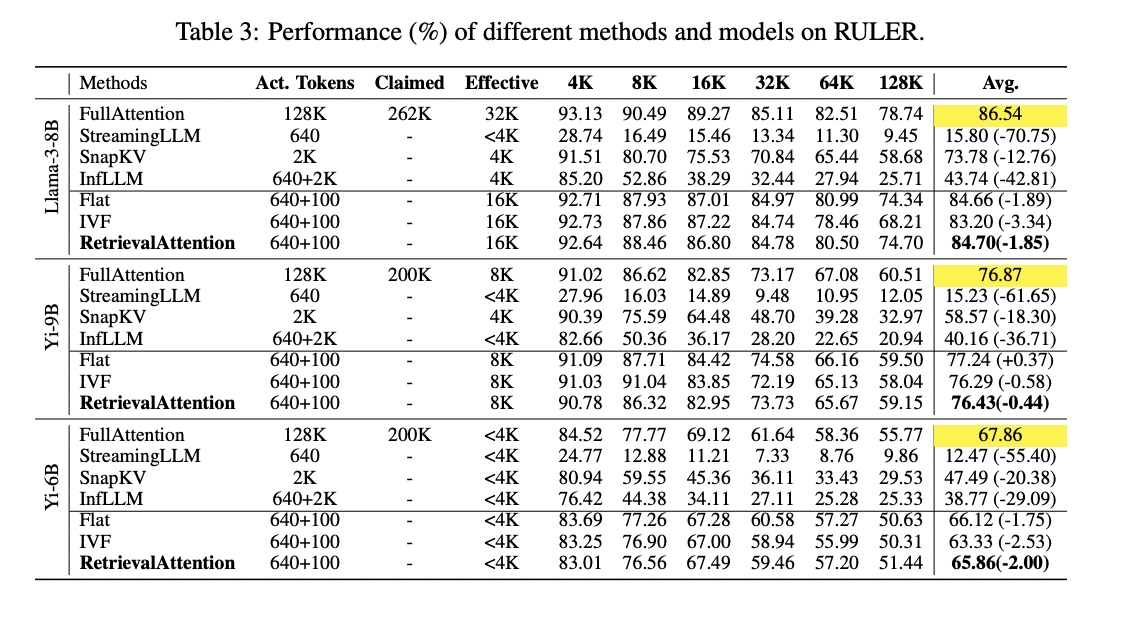
Esta pesquisa está chegando RecuperaçãoAtençãouma nova solução para acelerar a previsão LLM para conteúdo longo, extraindo vários vetores KV da memória da CPU e usando menos atenção dinâmica para pesquisa de vetores. O método lida com as diferenças de distribuição entre os vetores de consulta e chave, usando um método heurístico para identificar corretamente os tokens-chave para modelagem. Os resultados experimentais mostram a eficiência do RetrievalAttention, alcançando velocidades de gravação de 4,9× e 1,98× em comparação aos métodos KNN direto e ANNS tradicional, respectivamente, em uma única GPU RTX4090 com um núcleo de 128K tokens. RetrievalAttention é o primeiro sistema a oferecer suporte ao uso de LLMs de nível 8B e tokens de 128K em uma única GPU 4090 (24GB), mantendo latência aceitável e precisão do modelo. Esta inovação melhora muito a eficiência e a acessibilidade de grandes modelos de linguagem para processar uma ampla variedade de conteúdos.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
⏩ ⏩ WEBINAR GRATUITO DE IA: 'Vídeo SAM 2: Como sintonizar seus dados' (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)
Asjad é consultor estagiário na Marktechpost. Ele está cursando B.Tech em engenharia mecânica no Instituto Indiano de Tecnologia, Kharagpur. Asjad é um entusiasta do aprendizado de máquina e do aprendizado profundo que pesquisa regularmente a aplicação do aprendizado de máquina na área da saúde.
⏩ ⏩ WEBINAR GRATUITO DE IA: 'Vídeo SAM 2: Como sintonizar seus dados' (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)

.")
