
A decomposição de peso e o escalonamento ℓ2 são importantes para o aprendizado de máquina, especialmente para reduzir a capacidade da rede e reduzir componentes de peso não essenciais. Estas estratégias são consistentes com as leis da navalha de Occam e são importantes nas discussões sobre os limites da generalização. No entanto, pesquisas recentes questionaram a relação entre medidas baseadas em normalização e generalização em redes profundas. Embora a decomposição de peso seja amplamente utilizada em redes profundas de alto nível, como GPT-3, CLIP e PALM, seu efeito ainda não é totalmente compreendido. O surgimento de novas arquiteturas, como transformadores e o modelo de linguagem quase monotônico, tornou ainda mais difícil a aplicação de resultados clássicos a ambientes modernos de aprendizagem profunda.
Os esforços para compreender e utilizar a decomposição do peso avançaram significativamente ao longo do tempo. Estudos recentes destacaram os diferentes efeitos do decaimento de massa e da normalização ℓ2, especialmente para melhorias semelhantes às de Adam. Também destaca o impacto da decomposição de peso na dinâmica de otimização, incluindo o seu impacto nas taxas efetivas de aprendizagem em redes invariantes à escala. Outros métodos incluem seu papel na normalização do Jacobiano de entrada e na criação de alguns efeitos de amortecimento em outros otimizadores. Além disso, investigações recentes contêm uma relação entre perda de peso, duração do treino e desempenho geral. Embora tenha sido demonstrado que a decomposição ponderada melhora a precisão do teste, a melhoria é muitas vezes modesta, sugerindo que a adaptação implícita desempenha um papel importante na aprendizagem profunda.
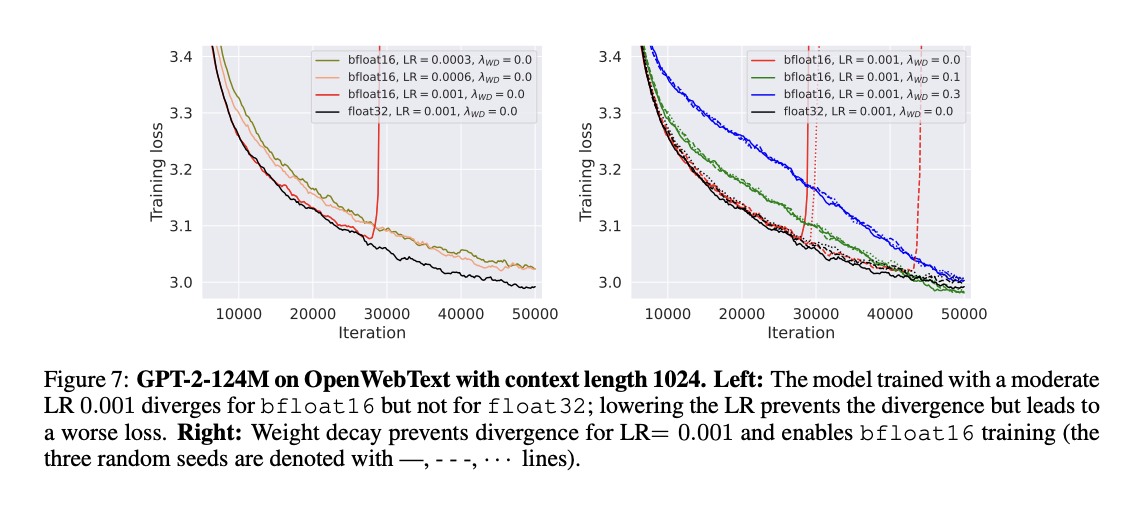
Pesquisadores do Laboratório de Teoria do Aprendizado de Máquina da EPFL propuseram uma nova perspectiva sobre o papel da decomposição de peso no aprendizado profundo moderno. O seu trabalho desafia a visão tradicional da perda de peso como forma de adaptação, tal como estudada na teoria clássica da aprendizagem. Eles mostraram que a decomposição de peso altera significativamente o potencial de otimização em redes parametrizadas e subparametrizadas. Além disso, a queda de peso evita a perda repentina de separação no treinamento de precisão mista do bfloat16, uma característica importante do treinamento LLM. Aplica-se a todos os tipos de estruturas, desde ResNets a LLMs, mostrando que a principal vantagem da decomposição de peso reside na sua capacidade de influenciar a dinâmica do treino, em vez de agir como um sistema claro.
Os experimentos são realizados treinando modelos GPT-2 em OpenWebText usando o repositório NanoGPT. É usado um modelo de parâmetros de 124M (GPT-2-Small) que é treinado com 50.000 iterações e ajustado para garantir o desempenho dentro das restrições acadêmicas. Verifica-se que a perda de treinamento e validação permanece intimamente relacionada em diferentes taxas de perda de peso. Os pesquisadores propõem dois métodos principais de decomposição de peso em LLMs:
- Melhor desempenho, conforme observado em estudos anteriores.
- Evitando perda de divisão ao usar a precisão bfloat16.
Estas descobertas contrastam com situações de dados limitados onde a generalização é o foco, destacando a importância da velocidade de desenvolvimento e estabilidade da formação na formação LLM.
Os resultados experimentais revelam um efeito significativo da decomposição de peso que permite o treinamento de precisão mista do bfloat16 para LLMs. O treinamento Bfloat16 acelera o processo e reduz o uso de memória da GPU, permitindo o treinamento de modelos grandes e lotes grandes. Porém, mesmo um bfloat16 estável pode apresentar picos de treinamento tardios que prejudicam o desempenho do modelo. Verificou-se também que a perda de peso evita essa diferença. Embora se saiba que o treinamento float16 encontra problemas com valores moderadamente grandes superiores a 65.519, ele representa um desafio diferente e sua precisão limitada pode levar a problemas ao adicionar componentes de rede com dimensões diferentes. A perda de peso resolve efetivamente esses problemas relacionados à precisão, evitando o ganho excessivo de peso.
Neste artigo, os pesquisadores apresentaram uma nova perspectiva sobre o papel da perda de peso na aprendizagem profunda moderna. Eles concluíram que a redução de peso mostra três efeitos diferentes no aprendizado profundo:
- Renderização geral quando combinada com ruído estocástico.
- Melhorando a eficiência das perdas de treinamento
- Garantindo estabilidade em treinamentos de baixa precisão.
Os investigadores desafiam a visão tradicional de que a perda de peso funciona como uma norma clara. Em vez disso, argumentam que a sua utilização generalizada na aprendizagem profunda moderna se deve à sua capacidade de criar mudanças benéficas na dinâmica de otimização. Esta teoria fornece uma explicação unificada para o sucesso da perda de peso em diferentes estruturas e ambientes de treinamento, desde tarefas visionárias com ResNets até LLMs. As abordagens futuras incluem treinamento de modelo e ajuste de hiperparâmetros na área de aprendizado profundo.
Confira Papel de novo GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit.
Convidamos startups, empresas e institutos de pesquisa que trabalham em modelos de microlinguagem para participar deste próximo projeto Revista/Relatório 'Modelos de Linguagem Pequena' Marketchpost.com. Esta revista/relatório será lançada no final de outubro/início de novembro de 2024. Clique aqui para agendar uma chamada!

Sajjad Ansari se formou no último ano do IIT Kharagpur. Como entusiasta da tecnologia, ele examina as aplicações da IA com foco na compreensão do impacto das tecnologias de IA e suas implicações no mundo real. Seu objetivo é transmitir conceitos complexos de IA de maneira clara e acessível.

: uma série 1B, 3B e 40B de modelos de IA generativos")
