
Redes neurais regulares (RNNs) têm sido fundamentais no aprendizado de máquina para resolver problemas baseados em sequências, incluindo previsão de séries temporais e processamento de linguagem natural. As RNNs são projetadas para lidar com sequências de comprimentos variados, mantendo um estado interno que captura informações a cada passo de tempo. No entanto, esses modelos muitas vezes enfrentam problemas de desaparecimento e explosão de gradientes, que limitam seu desempenho para sequências longas. Para resolver esta limitação, vários desenvolvimentos arquitetônicos foram desenvolvidos ao longo dos anos, melhorando a capacidade das RNNs de capturar dependências de longo prazo e executar tarefas complexas baseadas em sequências.
Um grande desafio na modelagem de sequências são as ineficiências computacionais dos modelos existentes, especialmente para sequências longas. Os transformadores surgiram como uma estrutura de destaque, alcançando resultados modernos em diversas aplicações, como modelagem e tradução de idiomas. No entanto, a sua complexidade quadrática em relação ao comprimento da sequência torna-os demasiado poderosos e impraticáveis para muitas aplicações com sequências longas ou recursos computacionais limitados. Isto levou a um interesse renovado em modelos que possam equilibrar desempenho e eficiência, garantindo escalabilidade sem comprometer a precisão.
Várias abordagens atuais foram propostas para lidar com este problema, como modelos de espaço de estados como o Mamba, que usam transformações dependentes de entrada para ajustar a sequência. Outros métodos, como modelos de atenção direta, melhoram o treinamento ao reduzir a computação necessária para sequências longas. Apesar de atingirem desempenho comparável ao dos transformadores, esses métodos geralmente envolvem algoritmos complexos e requerem técnicas especiais para implementação bem-sucedida. Além disso, métodos baseados em atenção, como Aaren e S4, introduziram novas técnicas para lidar com ineficiências, mas ainda enfrentam limitações, como aumento do consumo de memória e complexidade de implementação.
Pesquisadores da Borealis AI e Mila — Université de Montréal reexaminaram as arquiteturas RNN tradicionais, particularmente o modelo Long Short-Term Memory (LSTM) e a Gated Recurrent Unit (GRU). Eles introduziram versões simplificadas e menores desses modelos, denominadas minLSTM e minGRU, para resolver os problemas de escalabilidade enfrentados por seus equivalentes tradicionais. Ao remover as dependências de estado ocultas, as subversões não requerem mais retropropagação no tempo (BPTT) e podem ser treinadas em paralelo, melhorando significativamente a eficiência. Essa eficiência permite que esses pequenos RNNs lidem com sequências longas com custo computacional reduzido, tornando-os competitivos com modelos sequenciais recentes.
Os submodelos LSTM e GRU propostos eliminam métodos de entrada separados, computacionalmente caros e desnecessários, para muitas operações de sequenciamento. Ao simplificar o projeto e garantir que os resultados sejam independentes de escala, os pesquisadores conseguiram criar modelos que usam até 33% menos parâmetros do que os RNNs tradicionais. Além disso, a arquitetura modificada permite o treinamento paralelo, tornando esses submodelos 175 vezes mais rápidos que os LSTMs e GRUs convencionais ao lidar com sequências de comprimento 512. Essa melhoria na velocidade de treinamento é essencial para ampliar modelos para aplicações exigentes do mundo real. gerenciamento de sequências longas, como geração de texto e modelagem de linguagem.
Em termos de desempenho e resultados, as pequenas RNNs têm apresentado ganhos significativos em tempo de treinamento e eficiência. Por exemplo, na GPU T4, o modelo minGRU alcançou uma aceleração de 175x no tempo de treinamento em comparação com o GRU padrão para um comprimento de sequência de 512, enquanto o minLSTM mostrou uma melhoria de 235x. Para sequências ainda mais longas de comprimento 4096, a aceleração foi ainda mais pronunciada, com minGRU e minLSTM alcançando uma aceleração de 1324x e 1361x, respectivamente. Essa melhoria torna os pequenos RNNs mais adequados para aplicações que exigem treinamento rápido e eficiente. Os modelos também tiveram desempenho competitivo com arquiteturas de última geração, como Mamba, em testes empíricos, mostrando que RNNs simplificados podem alcançar resultados semelhantes ou superiores com sobrecarga computacional muito menor.
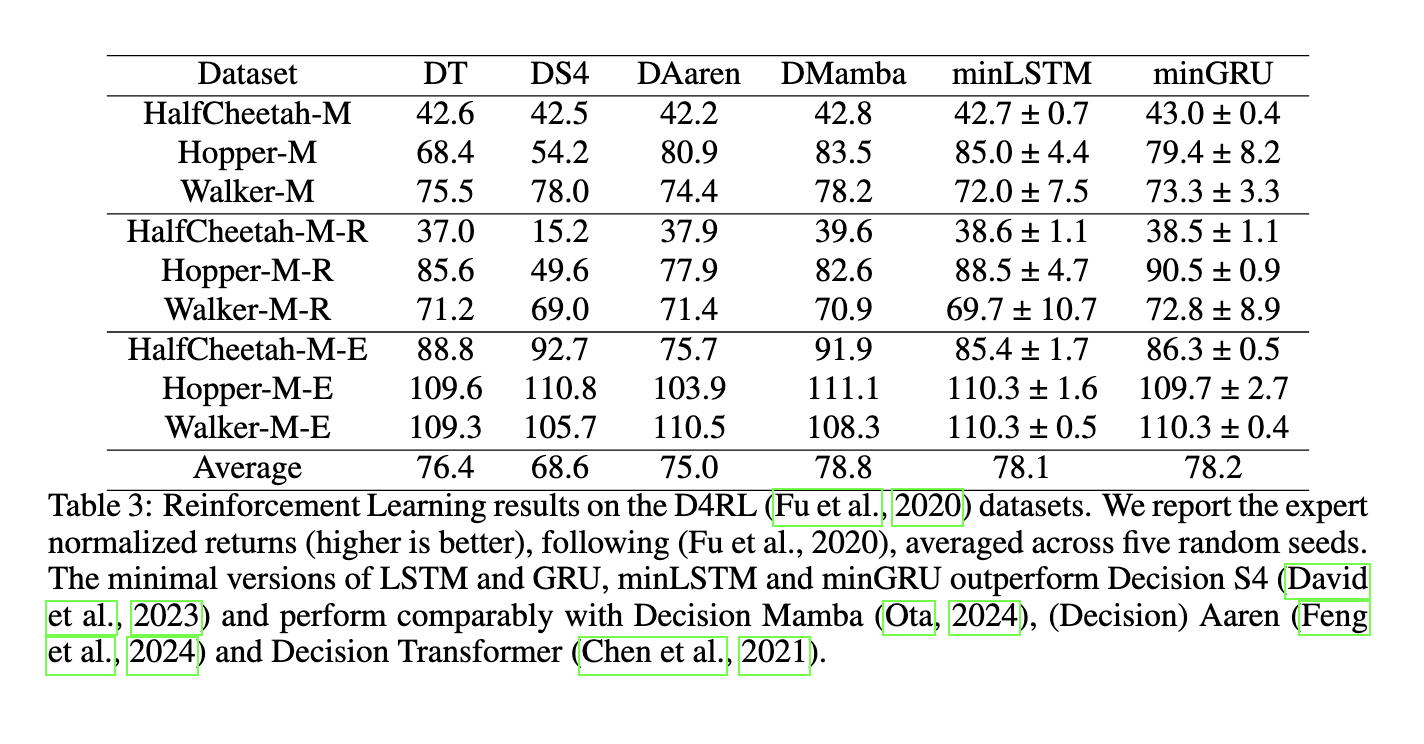
Os pesquisadores também testaram pequenos modelos em atividades de aprendizagem por reforço e modelagem de linguagem. Nos testes de aprendizagem por reforço, os modelos esparsos superaram os métodos existentes, como o Decision S4, e tiveram desempenho comparável ao Mamba e ao Decision Transformer. Por exemplo, no conjunto de dados Hopper-Medium, o modelo minLSTM obteve uma pontuação de desempenho de 85,0, enquanto o minGRU obteve 79,4, mostrando resultados sólidos em vários níveis de qualidade de dados. Da mesma forma, para tarefas de modelagem de linguagem, minGRU e minLSTM alcançaram perda de entropia cruzada comparável aos modelos baseados em transformadores, com minGRU atingindo uma perda de 1,548 e minLSTM alcançando uma perda de 1,555 no conjunto de dados de Shakespeare. Estes resultados destacam a eficiência e robustez de pequenos modelos em sistemas baseados em múltiplas sequências.
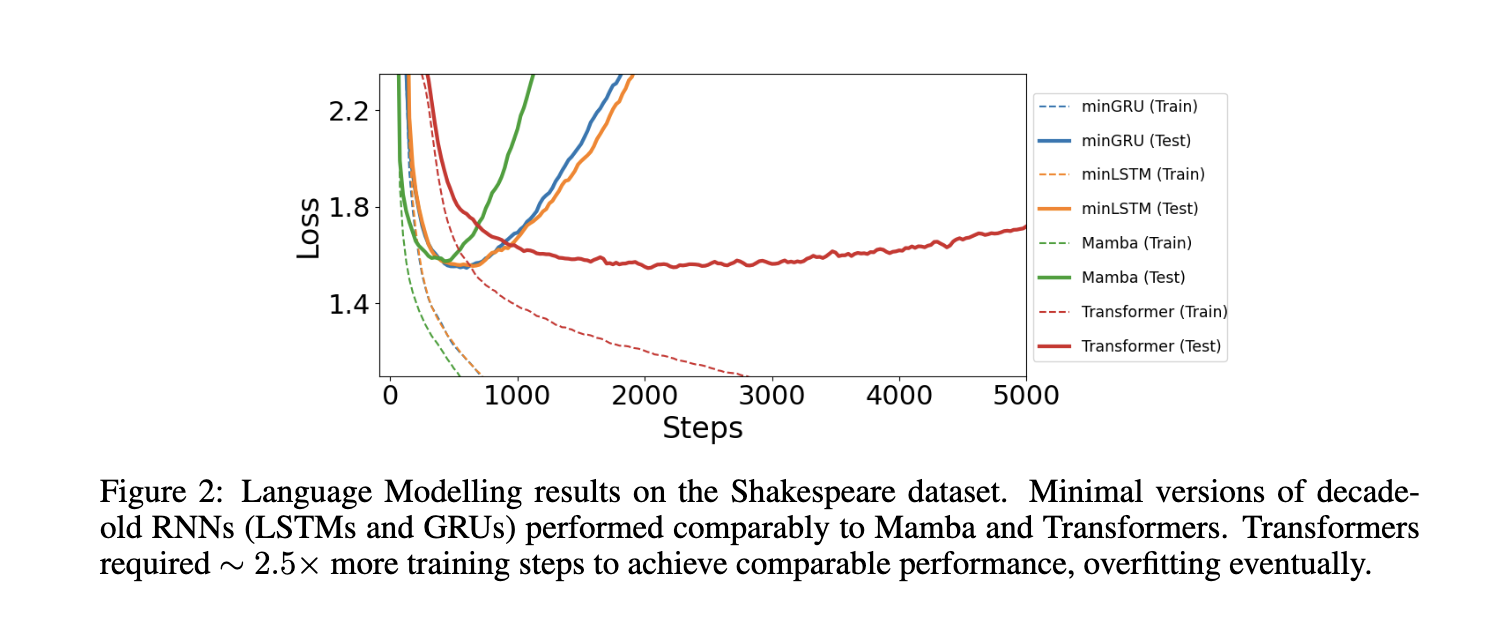
Concluindo, a introdução de pequenos LSTMs e GRUs pela equipe de pesquisa aborda as ineficiências computacionais dos RNNs tradicionais, mantendo um forte desempenho teórico. Ao simplificar os modelos e utilizar treinamento paralelo, as versões em miniatura oferecem uma alternativa viável às estruturas modernas complexas. Os resultados sugerem que, com algumas modificações, os RNNs tradicionais ainda podem ser eficazes em tarefas de modelagem sequencial, tornando esses pequenos modelos uma solução promissora para futuras pesquisas e aplicações neste campo.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit
Interessado em promover sua empresa, produto, serviço ou evento para mais de 1 milhão de desenvolvedores e pesquisadores de IA? Vamos trabalhar juntos!
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.


