
Grandes modelos de linguagem são bons para muitas tarefas, mas não para raciocínios complexos, especialmente quando se trata de problemas matemáticos. Os métodos atuais de Aprendizagem em Contexto (ICL) dependem fortemente de exemplos cuidadosamente selecionados e de assistência humana, dificultando a abordagem de novos problemas. Os métodos tradicionais também utilizam métodos de pensamento linear que limitam a sua capacidade de olhar para diferentes soluções, tornando-os lentos e ineficazes em diversas situações. Também é importante enfrentar estes desafios, a fim de desenvolver o pensamento automático, a adaptabilidade e o uso adequado dos LLMs.
As técnicas tradicionais de ICL, como o pensamento em cadeia de pensamento (CoT) e zero/poucos prompts, demonstraram confiabilidade na melhoria do desempenho cognitivo. O CoT faz com que os modelos pensem nos problemas passo a passo, o que é ótimo para a resolução sistemática de problemas. No entanto, estes métodos apresentam sérios problemas. Sua eficácia depende da qualidade das amostras e de como estão organizadas, o que requer muita habilidade para prepará-las. Os modelos não conseguem se adaptar a problemas que se desviam de seus exemplos de treinamento, reduzindo a utilidade em diversas tarefas. Além disso, os métodos atuais baseiam-se no raciocínio sequencial, o que impede a avaliação de outras estratégias de resolução de problemas. Estas limitações mostraram a necessidade de novas estruturas que reduzam a dependência humana, melhorem a generalização e melhorem a eficiência cognitiva.
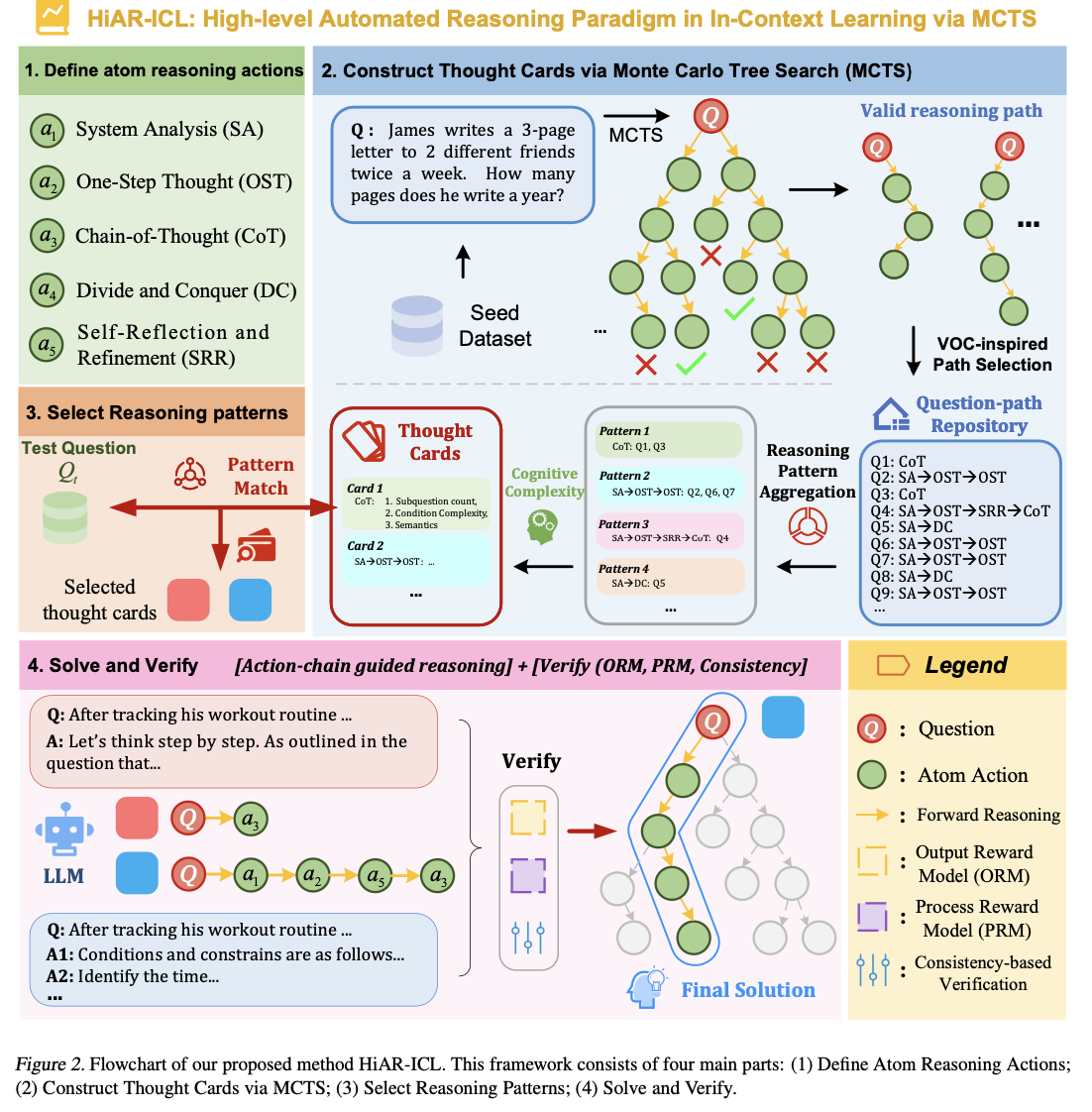
O HiAR-ICL (raciocínio automático de alto nível na aprendizagem em contexto) aborda esses desafios repensando o “contexto” como envolvendo padrões de pensamento de nível superior, em vez de focar na aprendizagem baseada em exemplos. Este paradigma incentiva a flexibilidade e a resiliência na resolução de problemas, cultivando habilidades de pensamento transferíveis. Inclui cinco processos de pensamento principais: Análise de Sistemas (SA), Pensamento em Uma Etapa (OST), Cadeia de Raciocínio (CoT), Divisão-Conquista (DC) e Auto-Reflexão e Refinamento (SRR), servindo como solução humana processos. Estas são a base sobre a qual os “cartões de pensamento”, modelos de pensamento reutilizáveis, são construídos usando o método Monte Carlo Tree Search (MCTS). O MCTS identifica os melhores padrões de pensamento a partir do conjunto de dados iniciais, que são então decompostos em padrões abstratos. Uma estrutura cognitiva complexa examina problemas em dimensões que incluem a enumeração de subquestões, complexidade situacional e semelhança semântica, o que informa fortemente a seleção de cartões de pensamento apropriados e precisos. Este processo de pensamento dinâmico é ainda melhorado por técnicas de validação em múltiplas camadas, incluindo estabilidade e testes baseados em recompensas, para garantir precisão e confiabilidade.
O HiAR-ICL mostra melhorias significativas na precisão e eficiência da imagem em vários benchmarks. Seu desempenho é superior em conjuntos de dados como MATH, GSM8K e StrategyQA. A precisão aumenta cerca de 27% em comparação com os métodos ICL tradicionais. A eficiência é incrível e o tempo de computação é reduzido em até 27 vezes para tarefas simples e até 10 vezes para problemas difíceis. Funciona bem com diversas aplicações e até modelos pequenos; assim, a precisão melhora na maioria dos testes em mais de 10%. A sua capacidade de ir além dos métodos tradicionais e ao mesmo tempo cobrir uma série de problemas difíceis promete revolucionar o campo.
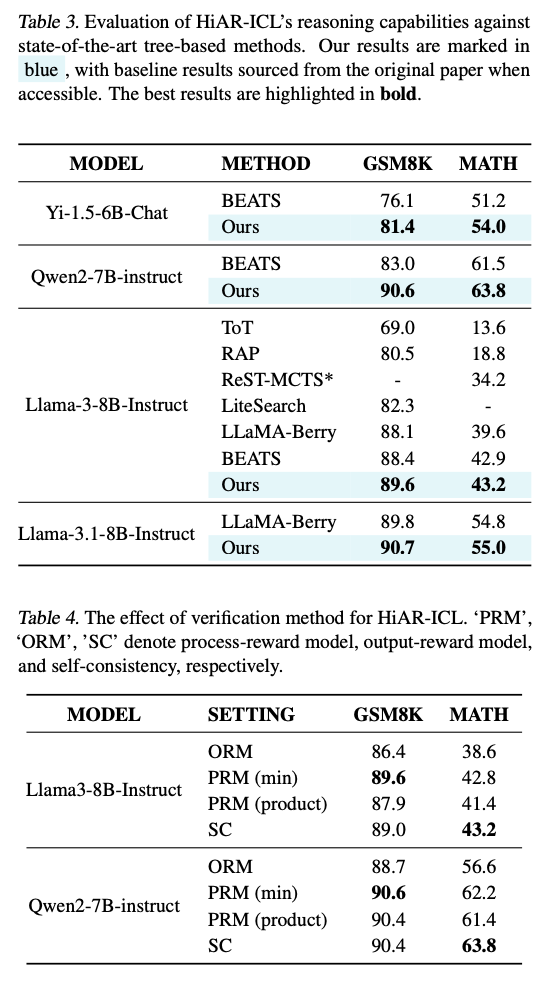
HiAR-ICL redefine a capacidade de pensamento em LLMs, mudando de paradigmas centrados em exemplos para estruturas cognitivas de nível superior. O Monte Carlo Tree Search e o uso de placas lógicas na resolução de problemas tornam-no uma ferramenta poderosa para trabalhar de forma dinâmica com muito pouca necessidade de assistência humana. Conseguiu chegar ao topo quando o seu desempenho foi testado através de testes rigorosos, demonstrando a sua capacidade de moldar o futuro do pensamento automatizado, especialmente para a gestão eficiente de tarefas complexas.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 60k + ML.
🚨 [Must Attend Webinar]: 'Transforme provas de conceito em aplicativos e agentes de IA prontos para produção' (Promovido)
Aswin AK é consultor da MarkTechPost. Ele está cursando seu diploma duplo no Instituto Indiano de Tecnologia, Kharagpur. Ele é apaixonado por ciência de dados e aprendizado de máquina, o que traz consigo uma sólida formação acadêmica e experiência prática na solução de desafios de domínio da vida real.
🚨🚨 WEBINAR DE IA GRATUITO: 'Acelere suas aplicações LLM com deepset e Haystack' (promovido)
 para melhorar a qualidade da amostragem de modelos de distribuição produtiva")

