
Grandes modelos multimodais generativos (LMMs), como LLaVA e Qwen-VL, se destacam em tarefas de linguagem visual (VL), como legendagem de imagens e resposta visual a perguntas (VQA). No entanto, esses modelos enfrentam desafios quando aplicados a tarefas discriminativas básicas de VL, como segmentação de imagens ou VQA de múltipla escolha, que requerem estimativa de vários rótulos. O principal obstáculo é a dificuldade de extrair características úteis de modelos generativos de funções discriminantes.
Os métodos atuais para otimizar LMMs para funções discriminativas geralmente dependem de engenharia rápida, otimização ou arquitetura especializada. Apesar de serem promissores, esses métodos são limitados pela dependência de dados de treinamento em grande escala, características específicas do processo ou falta de flexibilidade. Para resolver esse problema, uma equipe de pesquisadores da Carnegie Mellon University, da University of California, Berkeley, da IBM Research e do MIT-IBM Watson AI Lab propôs uma nova solução: Vetores de atenção esparsa (SAVs). SAVs são um mecanismo não corrigido que permite a ativação de uma pequena cabeça atencional em LMMs como características de tarefas discriminativas de VL. Inspirado no conceito da neurociência de especificidade funcional (como diferentes partes do cérebro são específicas para diferentes tarefas) e no trabalho recente sobre tradução de transdutores, este método usa menos de 1% da capacidade de atenção para extrair com eficácia características discriminativas. Os SAVs alcançam desempenho de última geração em apenas alguns exemplos e demonstram robustez em uma ampla gama de tarefas.
Para aprofundar o funcionamento do método, foram seguidos os seguintes passos para identificar e utilizar os Vetores de Atenção Fuzzy conforme mostrado na Figura 2:
- Produzindo vetores de atenção: Para um LMM congelado e um conjunto de dados com poucos disparos (por exemplo, 20 exemplos por rótulo), os vetores de atenção são extraídos de cada cabeça de atenção em cada camada. Especificamente, para o último token de cada sequência de entrada, o vetor de atenção é calculado como a saída do método de atenção do produto escalar.
- Identificando vetores-chave: O poder discriminativo de cada vetor de atenção é avaliado usando a classe centróide mais próxima. Para cada classe, o vetor médio de atenção (centróide) é calculado para todos os exemplos de várias tomadas. A similaridade de cosseno é calculada entre cada vetor de atenção e os centróides de classe, e os núcleos de atenção são classificados com base em sua precisão de classificação. As cabeças com melhor desempenho (por exemplo, as 20 primeiras) são selecionadas como o conjunto de vetores de atenção esparsa (HSAV).
- Programação usando SAVs: Dada a entrada de uma consulta, as previsões são feitas usando algumas cabeças de atenção selecionadas. Para cada cabeçalho no HSAV, a similaridade da consulta com os centróides da classe é calculada, e o rótulo final da classe é determinado pela maioria dos votos de todos os cabeçalhos. Este método permite a utilização de menos de 1% do total de cabeças de atenção, tornando o método simples e eficaz.
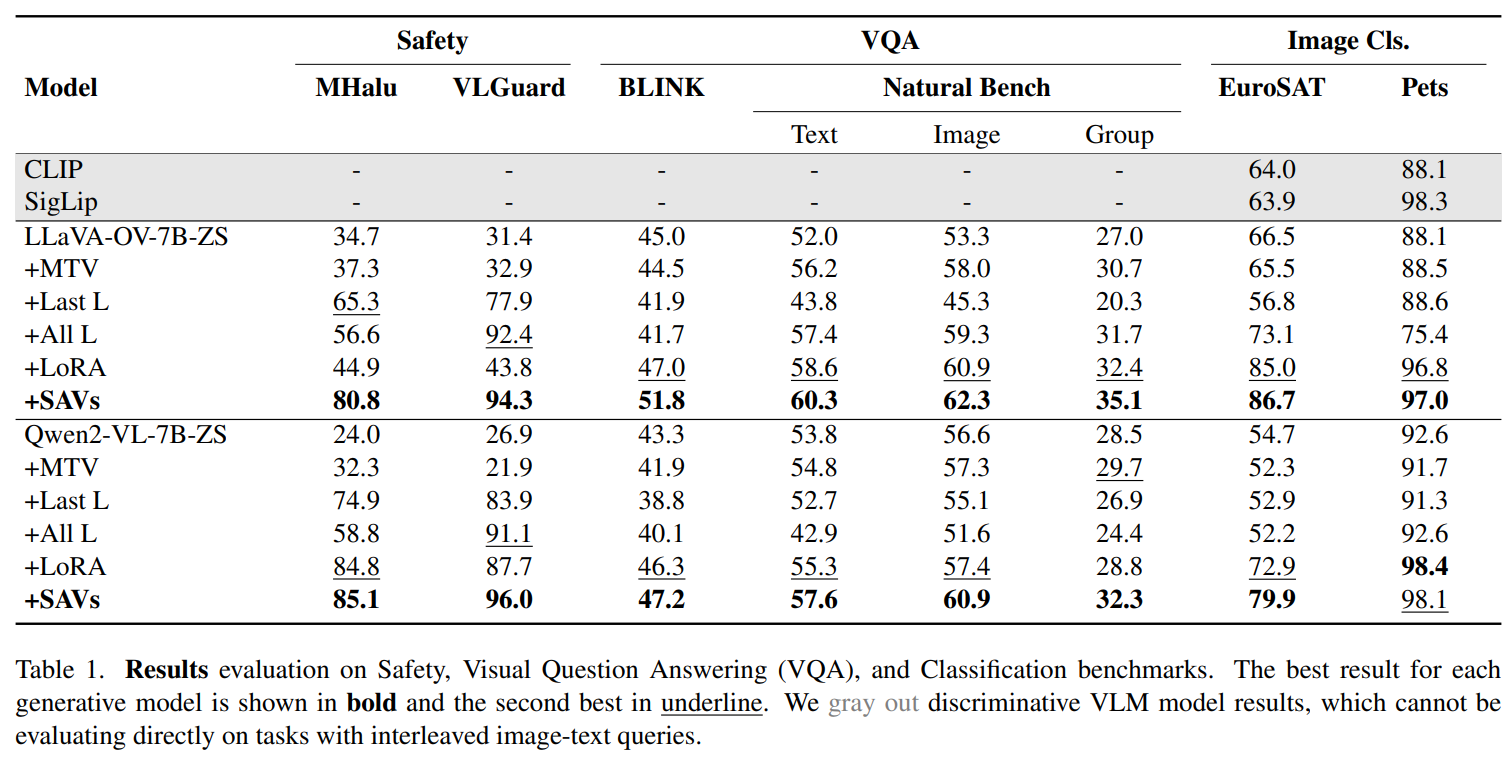
Para avaliação, os SAVs foram testados em dois LMMs de última geração – LLaVA-OneVision e Qwen2-VL – e comparados com múltiplas bases, incluindo métodos zero-shot (ZS), vários métodos e métodos de reforço, como LoRA. . O teste passou em uma série de funções discriminantes de VL. Os SAVs tiveram um desempenho melhor do que as linhas de base na detecção de falsos positivos (por exemplo, distinguir “alucinações visuais” de “não alucinações”) e conteúdo malicioso em conjuntos de dados como LMM-Alucinação de novo VLGuard. SAVs mostraram desempenho superior em conjuntos de dados desafiadores, como PISCAR de novo Banco Naturalque requerem pensamento visual e integrativo. SAVs também foram mais eficazes em conjuntos de dados semelhantes EuroSAT (segmentação de imagens de satélite) e Oxford-IIIT-Animais de estimação (boa classificação de animais domésticos). Os resultados mostraram que os SAVs são consistentemente mais eficazes do que as linhas de base de zero e poucos disparos, fechando a lacuna com modelos de linguagem visual discriminativos (VLMs), como CLIP e SigLIP. Por exemplo, os SAVs alcançaram alta precisão em tarefas de segurança e mostraram forte desempenho em todos os benchmarks de VQA e classificação de imagens.
Além disso, os SAVs requerem apenas alguns exemplos rotulados por classe, o que os torna úteis para tarefas com dados de treinamento limitados. O método identifica focos de atenção específicos que contribuem para a classificação, fornecendo informações sobre o funcionamento interno do modelo. SAVs são adaptáveis a uma variedade de tarefas discriminativas, incluindo aquelas que envolvem entrada de texto-imagem com caracteres. Ao usar um pequeno conjunto de cabeças de atenção, o método é computacionalmente simples e escalável.
Embora os SAVs proporcionem melhorias significativas, eles dependem do acesso à estrutura interna do LMM. Esta dependência limita a sua utilização em modelos de código aberto e coloca desafios para a sua utilização generalizada. Além disso, tarefas como recuperação de texto de imagem podem se beneficiar de mais métricas de confiança analítica do que o atual sistema de votação por maioria. Pesquisas futuras poderiam explorar SAVs, melhorando funções como recuperação multimodal, compactação de dados e recursos de incorporação de aplicativos downstream.
Confira Página de papel e GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 65k + ML.
🚨 Recomende uma plataforma de código aberto: Parlant é uma estrutura que muda a forma como os agentes de IA tomam decisões em situações voltadas para o cliente. (Promovido)
Vineet Kumar é estagiário de consultoria na MarktechPost. Atualmente, ele está cursando seu bacharelado no Instituto Indiano de Tecnologia (IIT), Kanpur. Ele é um entusiasta do aprendizado de máquina. Ele está interessado em pesquisas e desenvolvimentos recentes em Deep Learning, Visão Computacional e áreas afins.
📄 Conheça 'Height': ferramenta independente de gerenciamento de projetos (patrocinado)

: arquitetura, funcionalidade e inovação de soluções escaláveis de IA")
