
O Princípio da Energia Livre (FEP) e sua extensão, Inferência Ativa (AIF), apresentam uma abordagem única para a compreensão da auto-organização dos sistemas naturais. Essas estruturas sugerem que os agentes utilizem modelos internos de produção para prever observações de processos externos desconhecidos, atualizando continuamente seu raciocínio e condições de controle para minimizar erros de previsão. Embora este sistema integrativo forneça insights profundos sobre as interações agente-ambiente, aplicá-lo a situações práticas apresenta desafios significativos. Os pesquisadores precisam de controle refinado sobre os protocolos de comunicação agente-ambiente, especialmente ao simular feedback proprietário ou sistemas multiagentes. As soluções atuais de aprendizagem e controle por reforço, como o Gymnasium, exigem mais flexibilidade nessas simulações complexas. O estilo de planeamento crítico utilizado nos programas existentes limita a comunicação entre os agentes e o ambiente a áreas pré-definidas, limitando a exploração de vários cenários de interação importantes para o desenvolvimento da investigação FEP e AIF.
Os esforços existentes para enfrentar os desafios na modelagem de interações agente-ambiente concentraram-se principalmente em estruturas de aprendizagem por reforço. Gymnasium já é o padrão para criação e compartilhamento de cenários de controle, fornecendo uma função step para definir funções de transformação e lidar com simulações de ambiente. Alternativas semelhantes incluem Deepmind Control Suite do Python e ReinforcementLearning.jl de Julia. Esses pacotes proporcionam interação de alto nível nas áreas, facilitando a cronometragem para os usuários. Embora tenha sido projetado para aprendizagem reforçada, foi adaptado para pesquisas de Inferência Ativa. Outros pacotes, como o PyMDP e a caixa de ferramentas SPM-DEM, incluem realizações ambientais, mas priorizam a criação de agentes. No entanto, a falta de uma forma padronizada para definir áreas de Inferência Ativa levou a uma utilização inconsistente, com alguns investigadores a utilizarem o Gymnasium e outros a escolherem caixas de ferramentas especializadas. A Programação Reativa, como o Modelo de Ator, oferece uma alternativa promissora ao permitir a computação de dados em conjuntos de dados estáticos e observações síncronas de sensores em tempo real, alinhadas mais estreitamente com os princípios da Inferência Ativa.
Pesquisadores da Universidade de Tecnologia de Eindhoven e da GN Audição estão presentes RxEnvironments.jlPacote Julia, que apresenta Ambientes Reativos como uma forma robusta de modelar interações agente-ambiente. Esta implementação utiliza os princípios da Programação Reativa para criar simulações eficientes e flexíveis. O pacote aborda as limitações das estruturas existentes, fornecendo uma plataforma flexível para projetar ambientes complexos e multiagentes. Ao adotar um estilo de programação funcional, RxEnvironments.jl permite aos pesquisadores modelar sistemas complexos e agentes interagentes de forma mais eficaz. O design do pacote ajuda a explorar uma variedade de cenários, desde simples simulações de agente único até complexos sistemas biológicos multiagentes. Através do estudo de diversos exemplos, RxEnvironments.jl demonstra sua capacidade de lidar com ambientes ambientais diversos e complexos, demonstrando seu potencial como uma ferramenta poderosa para o desenvolvimento de pesquisas em Inferência Ativa e áreas afins.
RxEnvironments.jl adota uma abordagem de programação ativa para design ambiental, abordando as limitações das principais estruturas. Esta abordagem permite a interação multisensor e multimodal entre os agentes e o ambiente, sem limites de comunicação estritos. O pacote fornece controle visual detalhado, permitindo que diferentes canais de sensores sejam ativados em frequências ou gatilhos com base em ações específicas. Essa flexibilidade permite a implementação de cenários complexos do mundo real com controle refinado sobre as visões do agente. RxEnvironments.jl oferece suporte nativo a vários ambientes de agente, permitindo a existência de várias instâncias do mesmo tipo de agente sem codificação adicional. O estilo de programação ativo garante cálculos suaves, com um ambiente que gera recursos visuais quando comandado e fica ocioso quando não é necessário. Além disso, o pacote vai além de estruturas simples de ambiente de agente, suportando ambientes multiempresas complexos para simulações complexas.
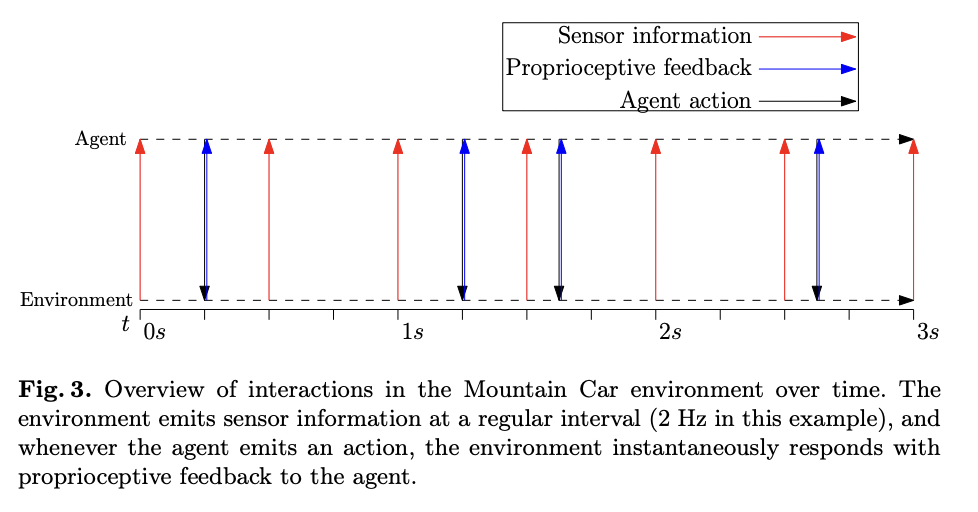
O ambiente Mountain Car, um ambiente clássico de aprendizagem por reforço, é usado em RxEnvironments.jl com um toque único. Esta implementação demonstra a capacidade do pacote de lidar com interações complexas do agente com o ambiente. Quando um agente executa uma ação, como definir a aceleração de um motor, o ambiente responde com observações contendo a potência real do motor utilizada. Esta abordagem é consistente com as ideias atuais sobre feedback ideal em sistemas biológicos. O ambiente foi projetado para acionar diferentes implementações da função what_to_send com base no gatilho de entrada. Para ações de aceleração, ele retorna a ação de aceleração aplicada, enquanto as medições de posição e velocidade são emitidas em uma frequência padrão de 2 Hz, simulando o comportamento do sensor. Esta configuração demonstra a capacidade do RxEnvironments.jl de lidar com diferentes tipos de observações – feedback sensorial e proprioceptivo – cada uma com seu próprio sentido de detecção e transmissão.
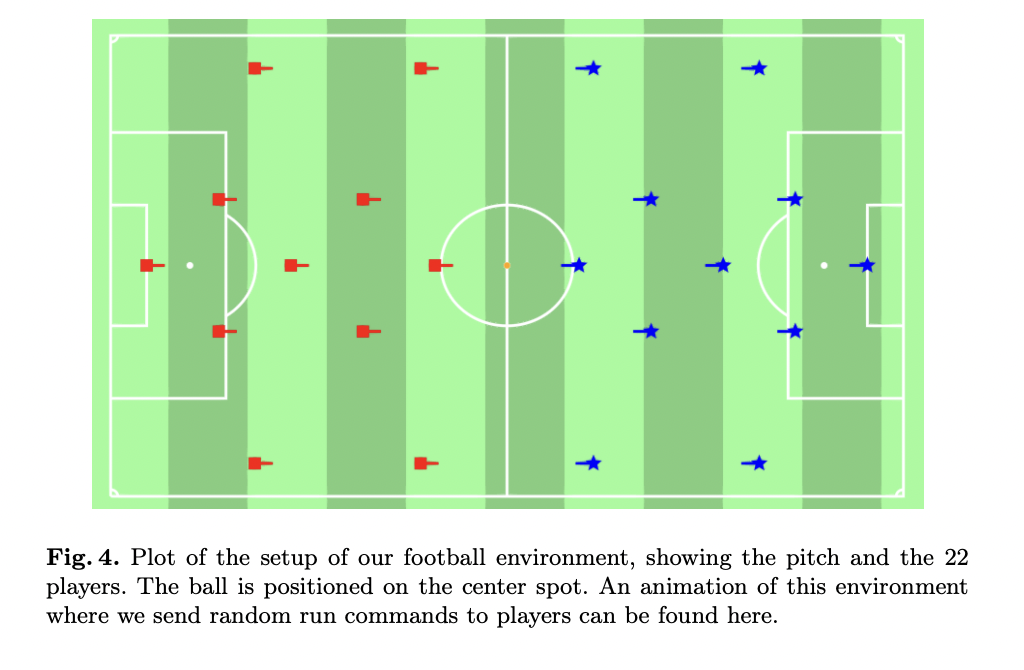
RxEnvironments.jl demonstra sua versatilidade usando uma simulação complexa de um jogo de futebol. Este ambiente multiagente envolve 22 jogadores, demonstrando a capacidade do pacote de lidar com cenários complexos do mundo real. A simulação é construída com uma entidade representando o país do mundo, que contém a bola e os indicadores de todos os corpos dos 22 jogadores, e 22 entidades diferentes para cada jogador. Este design permite a detecção de colisões e ações realistas no futebol. Os jogadores assinam o Global Business, mas não uns aos outros, formando um bom gráfico de assinaturas. A comunicação entre agentes é facilitada pela Associação Global, que transmite sinais entre os jogadores. O ambiente se divide entre regiões globais e locais, com a Empresa global controlando as interações físicas e grupos de jogadores mantendo suas regiões locais e recebendo recursos visuais da comunidade global. Esta configuração permite a execução assíncrona de comandos para jogadores individuais, conforme mostrado no vídeo complementar. Embora a simulação se concentre no funcionamento e nas ações do futebol, e não nas regras completas do futebol, ela demonstra bem o poder do RxEnvironments.jl para modelar sistemas complexos e multiagentes com visualizações e interações individuais.
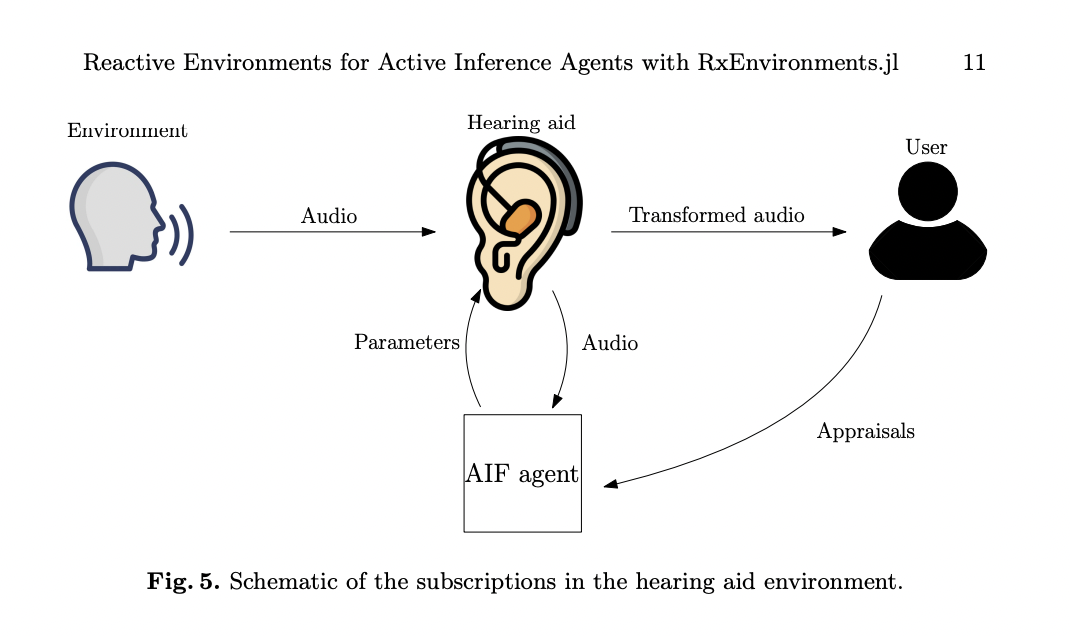
RxEnvironments.jl também demonstra sua flexibilidade ao modelar um sistema de aparelho auditivo complexo que incorpora agentes ativos baseados em lógica para reduzir o ruído. Esta situação complexa envolve muitas partes interagindo: o próprio aparelho auditivo, o ambiente acústico externo, o usuário (paciente) e o agente inteligente no telefone do usuário. O pacote lida bem com os desafios únicos deste sistema multiempresarial, onde o aparelho auditivo deve comunicar constantemente com três fontes diferentes. Ele processa sinais acústicos do mundo exterior, recebe feedback do usuário sobre o desempenho percebido e se comunica com um agente inteligente por telefone para análises avançadas. Esta implementação demonstra a capacidade do RxEnvironments.jl de modelar sistemas do mundo real com processamento distribuído e múltiplos canais de comunicação, abordando as restrições de poder de computação limitado e energia da bateria em aparelhos auditivos. A abordagem de programação do pacote facilita o gerenciamento dessas interações complexas e assíncronas, tornando-o uma ferramenta ideal para simulação e desenvolvimento de tecnologia assistiva.
Este estudo apresenta cenários funcionais e sua implementação em RxEnvironments.jl que fornecem uma estrutura flexível para modelar interações complexas entre agente e ambiente. Esta abordagem combina cenários tradicionais de aprendizagem por reforço, ao mesmo tempo que permite simulações complexas, particularmente Inferência Ativa. O estudo de caso demonstra o poder da estrutura, que permite uma variedade de configurações ambientais, desde problemas de controle clássicos até sistemas multiagentes e simulações de aparelhos auditivos avançados. A flexibilidade do RxEnvironments.jl no tratamento de protocolos de comunicação complexos entre agentes e seus ambientes o torna uma ferramenta valiosa para pesquisadores. Trabalhos futuros poderão explorar classes de agentes que implementam com sucesso este processo de comunicação, desenvolvendo ainda mais o campo da simulação agente-ambiente.
Confira Papel de novo GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
Asjad é consultor estagiário na Marktechpost. Ele está cursando B.Tech em engenharia mecânica no Instituto Indiano de Tecnologia, Kharagpur. Asjad é um entusiasta do aprendizado de máquina e do aprendizado profundo que pesquisa regularmente a aplicação do aprendizado de máquina na área da saúde.


