
Os modelos linguísticos de grande escala (LLMs) revolucionaram a forma como as máquinas processam e reproduzem a linguagem humana, mas a sua capacidade de raciocinar eficazmente numa vasta gama de tarefas continua a ser um grande desafio. Os pesquisadores em IA estão trabalhando para permitir que esses modelos não apenas compreendam a linguagem, mas também executem tarefas cognitivas complexas, como resolver problemas de matemática, lógica e conhecimentos gerais. O foco está na criação de sistemas que possam executar tarefas baseadas em lógica de forma automática e precisa em vários domínios.
Uma das questões críticas enfrentadas pelos pesquisadores de IA é que muitas abordagens atuais para o desenvolvimento de habilidades de pensamento LLM dependem fortemente da intervenção humana. Esses métodos geralmente exigem modelos conceituais cuidadosamente projetados por humanos ou o uso de modelos avançados, ambos caros e demorados. Além disso, quando os LLMs são testados em tarefas fora do seu domínio de formação, perdem precisão, indicando que os sistemas atuais devem ser verdadeiramente generalistas nas suas capacidades de raciocínio. Esta lacuna no desempenho em várias tarefas representa um obstáculo à criação de sistemas de IA flexíveis e de uso geral.
Vários métodos existentes visam resolver este problema. Esses métodos geralmente incentivam os LLMs a gerar etapas de pensamento, geralmente chamadas de pensamento de cadeia de pensamento (CoT), e classificar essas etapas com base no resultado ou na estabilidade. No entanto, estes métodos, como STAR e LMSI, têm limitações. Eles usam conjuntos pequenos e padronizados de métodos de raciocínio projetados por humanos que ajudam os modelos a ter um bom desempenho em tarefas semelhantes àquelas nas quais foram treinados, mas apresentam dificuldades quando aplicados a tarefas fora de domínio (OOD), limitando sua aplicabilidade geral. Portanto, embora estes modelos possam melhorar o pensamento num ambiente controlado, eles precisam de integrar e fornecer um desempenho consistente quando confrontados com novos desafios.
Para responder a essas limitações, os pesquisadores da Salesforce AI Research introduziram uma nova abordagem chamada ReGenesis. Esta abordagem permite que os LLMs desenvolvam suas habilidades de raciocínio por conta própria, sem a necessidade de exemplos adicionais feitos pelo homem. O ReGenesis permite que os modelos integrem seus processos de pensamento como dados pós-treinamento, ajudando-os a se adaptarem a novas tarefas de forma mais eficaz. Ao refinar gradualmente o pensamento, desde orientações vagas até construções específicas de tarefas, o método aborda as deficiências dos modelos existentes e ajuda a desenvolver competências de pensamento mais gerais.
A metodologia por trás do ReGenesis está organizada em três etapas principais. Primeiro, gera diretrizes conceituais amplas e independentes de tarefas, que são princípios gerais que se aplicam a uma variedade de tarefas. Estas orientações não estão vinculadas a nenhum problema específico, permitindo ao modelo manter flexibilidade no seu pensamento. Em seguida, estas orientações abstratas são transformadas em estruturas de pensamento específicas para tarefas, permitindo ao modelo desenvolver estratégias de pensamento mais focadas para problemas específicos. Finalmente, o LLM usa essas estruturas de pensamento para criar métodos de pensamento detalhados. Depois que os caminhos são gerados, o modelo os filtra usando respostas verdadeiras ou técnicas de votação por maioria para eliminar soluções incorretas. Portanto, este processo melhora o poder de raciocínio do modelo sem depender de exemplos predefinidos ou de extensas contribuições humanas, tornando todo o processo escalável e eficiente para uma série de tarefas.
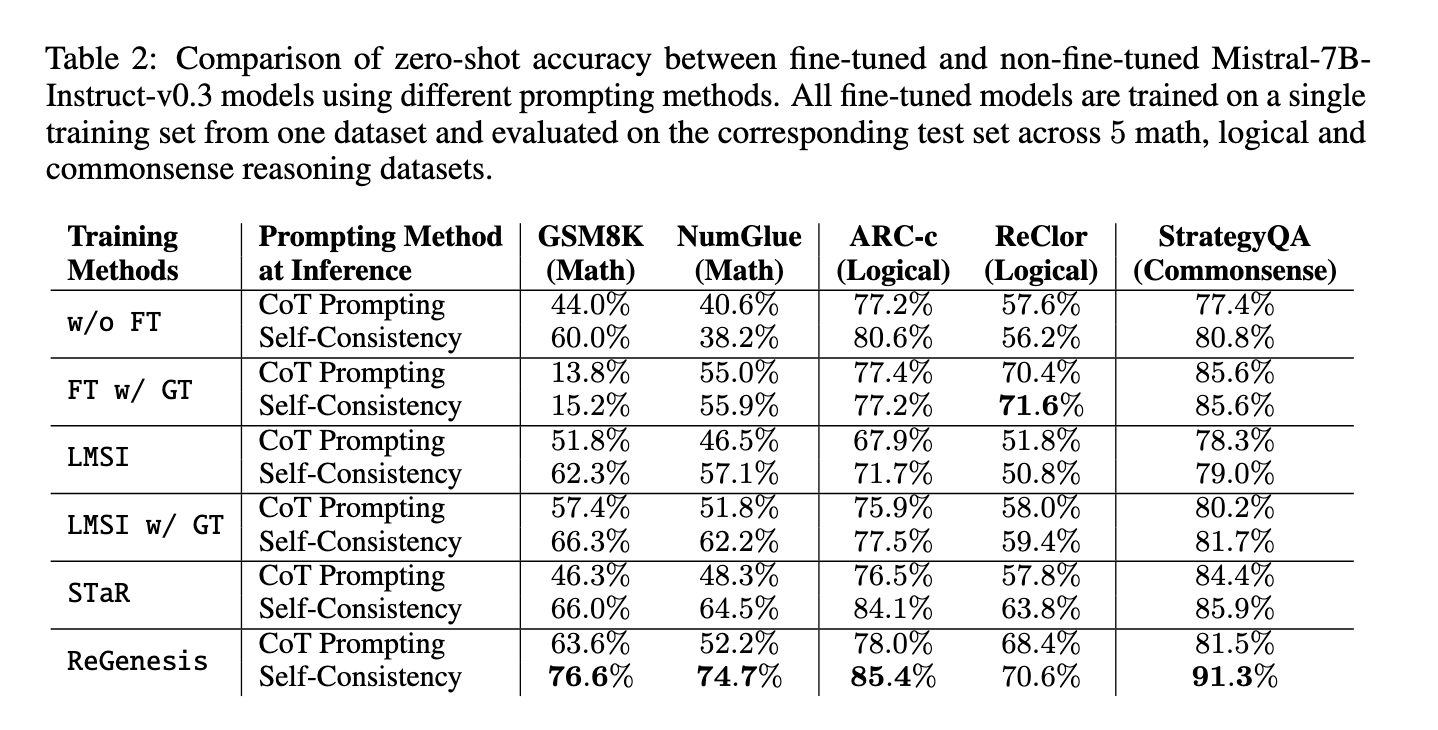
Os resultados do uso do ReGenesis são surpreendentes. Os pesquisadores testaram esse método em todas as operações locais e externas e descobriram que o ReGenesis superou consistentemente os métodos existentes. Especificamente, o ReGenesis apresentou uma melhoria de 6,1% no desempenho do OOD, enquanto outros modelos mostraram uma queda média de desempenho de 4,6%. Num conjunto de testes envolvendo seis tarefas OOD, como raciocínio matemático e lógico, o ReGenesis conseguiu manter o seu desempenho, enquanto outros modelos registaram quedas significativas após o treino. Para tarefas no domínio, como aquelas nas quais os modelos foram originalmente treinados, o ReGenesis também apresentou desempenho superior. Por exemplo, obteve resultados entre 7,1% e 18,9% melhores em uma variedade de tarefas, incluindo raciocínio geral e resolução de problemas matemáticos.
Resultados mais detalhados do ReGenesis também destacam seu desempenho. Para seis tarefas OOD, incluindo matemática, lógica e interpretação de linguagem natural, o ReGenesis mostrou uma melhoria constante na precisão. Num caso, o modelo mostrou um aumento de 6,1% no desempenho do OOD, em contraste com a diminuição média do desempenho de 4,6% observada nos métodos de referência. Além disso, embora os métodos existentes como o STAR tenham sofrido uma diminuição na precisão quando aplicados a novas tarefas, o ReGenesis pode evitar esta diminuição e apresentar melhorias significativas, tornando-se uma solução mais robusta para consulta geral. Em outro teste envolvendo cinco tarefas de domínio, o ReGenesis passou nos cinco métodos básicos por uma média de 7,1% a 18,9% e enfatiza sua alta capacidade de pensar com sucesso em diferentes tarefas.
Concluindo, a introdução do ReGenesis pela Salesforce AI Research aborda uma grande lacuna no desenvolvimento de LLMs. Ao permitir que os modelos sintetizem seus próprios métodos de pensamento a partir de diretrizes padrão e os adaptem a tarefas específicas, o ReGenesis fornece uma solução confiável para melhorar o desempenho local e externo. A capacidade do método de desenvolver o raciocínio sem depender de supervisão humana dispendiosa ou de dados de treinamento específicos de tarefas marca um passo importante no desenvolvimento de sistemas de IA verdadeiramente produtivos para uma variedade de tarefas. Os benefícios de desempenho relatados para tarefas dentro e fora do domínio tornam o ReGenesis uma ferramenta promissora para melhorar as habilidades de raciocínio em IA.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] A melhor plataforma para modelos ajustados: mecanismo de inferência Predibase (atualizado)
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


