
O desenvolvimento de modelos linguísticos de larga escala (LLMs) no processamento de linguagem natural melhorou muito vários domínios. À medida que modelos mais complexos são desenvolvidos, avaliar com precisão seus resultados torna-se importante. Tradicionalmente, os testes em humanos têm sido um método comum de avaliação da qualidade, mas este processo é demorado e precisa de ser ampliado com o ritmo rápido do desenvolvimento do modelo.
A pesquisa de IA da Salesforce apresenta Juiz SFRuma família de três modelos de juízes baseados no LLM, para mudar a forma como os resultados do LLM são avaliados. Construído usando Meta Llama 3 e Mistral NeMO, o SFR-Judge vem em três tamanhos: parâmetros de 8 bilhões (8B), 12 bilhões (12B) e 70 bilhões (70B). Cada modelo é projetado para realizar múltiplas tarefas exploratórias, como comparações de pares, medidas únicas e classificação binária. Esses modelos são projetados para apoiar equipes de pesquisa na avaliação rápida e eficiente de novos LLMs.
Uma das principais limitações do uso de LLMs tradicionais como juízes é a sua tendência ao preconceito e à inconsistência. A maioria dos modelos de jurados, por exemplo, apresentam viés de classificação, onde seus julgamentos são influenciados pela forma como as respostas são apresentadas. Outros podem apresentar um viés de comprimento, favorecendo respostas mais longas que parecem completas mesmo quando as mais curtas são mais precisas. Para resolver esses problemas, os modelos SFR-Judge são treinados usando Direct Preference Optimization (DPO), que permite ao modelo aprender com exemplos positivos e negativos. Este método de treinamento ajuda o modelo a desenvolver uma compreensão diferente das tarefas de avaliação, reduzir preconceitos e garantir um julgamento consistente.
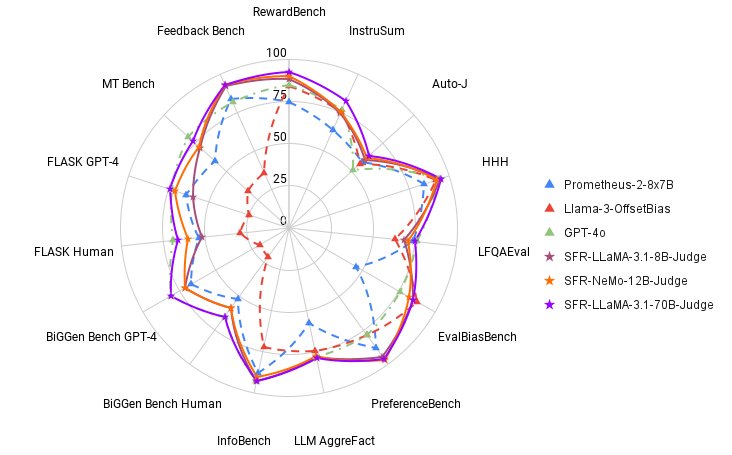
Os modelos SFR-Judge foram testados em 13 benchmarks em três tarefas de teste, mostrando desempenho superior aos modelos de juízes existentes, incluindo modelos proprietários como o GPT-4o. Notavelmente, o SFR-Judge obteve excelente desempenho em 10 dos 13 benchmarks, estabelecendo um novo padrão na avaliação baseada em LLM. Por exemplo, na tabela de classificação do RewardBench, o SFR-Judge alcançou uma precisão de 92,7%, marcando a primeira e a segunda vez que qualquer modelo de juiz produtivo excedeu o limite de 90%. Estes resultados destacam a eficácia do SFR-Judge não apenas como modelo de avaliação, mas também como modelo de recompensa capaz de orientar modelos downstream na aprendizagem por reforço em situações de resposta humana (RLHF).
O método de treinamento SFR-Judge inclui três formatos de dados diferentes. A primeira, Crítica da Cadeia de Pensamento, ajuda o modelo a gerar uma análise sistemática e detalhada das respostas testadas. Esta crítica melhora a capacidade do modelador de pensar sobre ideias complexas e tomar decisões informadas. O segundo formato, Julgamento Padrão, simplifica a avaliação ao eliminar críticas que fornecem feedback direto sobre se as respostas atendem aos critérios especificados. Finalmente, a Dedução de Respostas permite ao modelo descobrir como são as respostas de alta qualidade, fortalecendo as suas capacidades de julgamento. Esses três formatos de dados trabalham juntos para fortalecer a capacidade do modelo de produzir avaliações completas e precisas.
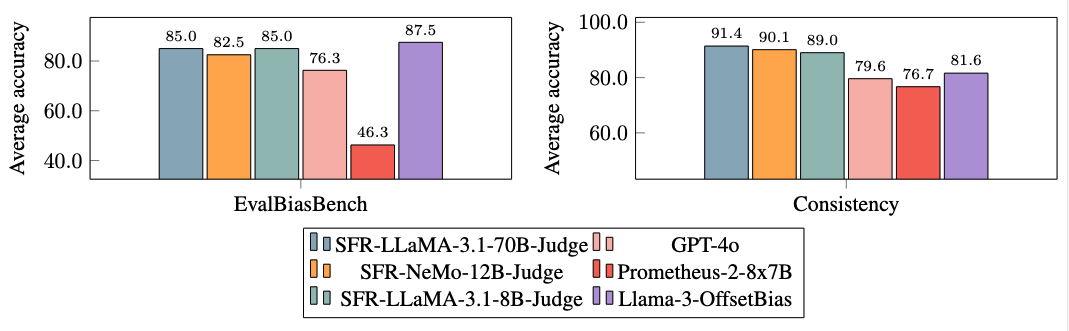
Testes extensivos revelaram que os modelos SFR-Judge são mais tendenciosos do que os modelos concorrentes, como demonstrado pelo seu desempenho no EvalBiasBench, um benchmark concebido para testar seis tipos de preconceito. Os modelos apresentam altos níveis de ordenação de pares na maioria dos benchmarks, indicando que seus julgamentos permanecem estáveis mesmo quando a ordem das respostas é alterada. Esta robustez posiciona o SFR-Judge como uma solução confiável para automatizar a avaliação de LLMs, reduzindo a dependência de anotações humanas e fornecendo uma alternativa livre de riscos à avaliação de modelos.
Principais conclusões do estudo:
- Alta precisão: O SFR-Judge obteve pontuações máximas em 10 dos 13 benchmarks, incluindo 92,7% de precisão no RewardBench, superando muitos dos modelos de juízes mais bem classificados.
- Para reduzir o preconceito: Os modelos apresentaram níveis mais baixos de viés, incluindo altura e posição, em comparação com outros modelos de jurados, conforme verificado pelo seu desempenho no EvalBiasBench.
- Vários programas: O SFR-Judge suporta três funções principais de avaliação – comparação pareada, estimativa única e classificação binária, tornando-o adequado para uma variedade de situações de avaliação.
- Definições Sistemáticas: Ao contrário da maioria dos modelos de juízes, o SFR-Judge é treinado para produzir explicações detalhadas dos seus julgamentos, reduzindo a natureza de caixa negra das avaliações baseadas no LLM.
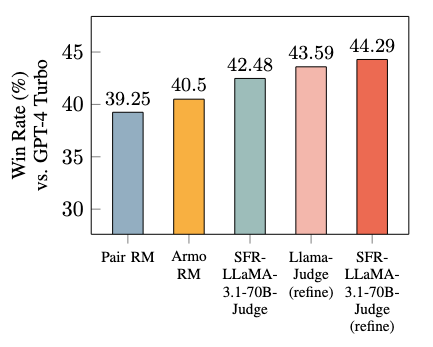
- Melhorando o desempenho em modelos descendentes: As interpretações dos modelos podem melhorar o resultado dos modelos downstream, tornando-os uma ferramenta eficaz para cenários RLHF.
Concluindo, a introdução do SFR-Judge pela Salesforce AI Research marca um avanço significativo na avaliação automatizada de grandes modelos de linguagem. Usando a Otimização de Preferência Direta e um conjunto diversificado de dados de treinamento, a equipe de pesquisa criou uma família de modelos de julgamento robustos e confiáveis. Esses modelos podem aprender com diferentes exemplos, fornecer feedback detalhado e reduzir preconceitos comuns, tornando-os ferramentas valiosas para avaliar e refinar conteúdo produtivo. SFR-Judge estabelece um novo marco na avaliação baseada em LLM e abre as portas para novos avanços na avaliação automatizada de modelos.
Confira Papel de novo Detalhes. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit.
Convidamos startups, empresas e institutos de pesquisa que trabalham em modelos de microlinguagem para participar deste próximo projeto Revista/Relatório 'Modelos de Linguagem Pequena' Marketchpost.com. Esta revista/relatório será lançada no final de outubro/início de novembro de 2024. Clique aqui para agendar uma chamada!
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.


