
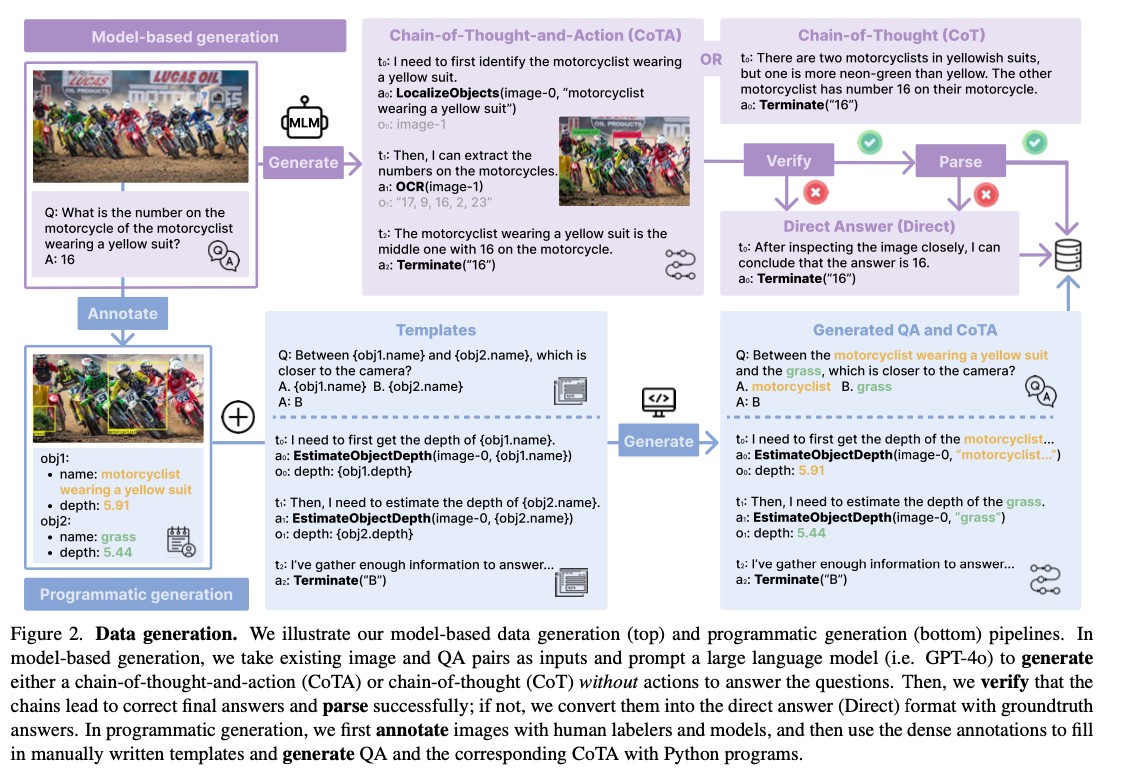
O desenvolvimento de sistemas de IA multidimensionais para aplicações do mundo real requer o gerenciamento de uma variedade de tarefas, como reconhecimento refinado, localização visual, raciocínio e resolução de problemas em várias etapas. Os modelos de código aberto multilíngues existentes são insuficientes nessas áreas, especialmente para tarefas que envolvem ferramentas externas, como OCR ou cálculos matemáticos. As limitações acima mencionadas podem ser atribuídas principalmente a conjuntos de dados de uma única etapa que não podem fornecer uma estrutura coerente para o raciocínio em várias etapas e cadeias de ação lógicas. Superar isso será fundamental para desbloquear o verdadeiro poder do uso de IA multidimensional em níveis complexos.
Os modelos multivariados atuais geralmente dependem de programação instrucional com conjuntos de dados que possuem respostas específicas ou poucos mecanismos de feedback. Sistemas proprietários, como o GPT-4, demonstraram a capacidade de pensar com sucesso nas cadeias CoTA. Ao mesmo tempo, os modelos de código aberto enfrentam os desafios da falta de conjuntos de dados e de integração com ferramentas. Esforços anteriores, como LLaVa-Plus e Visual Program Distillation, também foram limitados por conjuntos de dados pequenos, dados de treinamento de baixa qualidade e foco em tarefas simples de resposta a perguntas, limitando os problemas multimodais complexos que eles exigem. pensamento complexo e uso de ferramentas.
Pesquisadores da Universidade de Washington e da Salesforce Research desenvolveram o TACO, uma nova estrutura para treinar modelos de ação multipercurso usando conjuntos de dados de desempenho CoTA. Este trabalho apresenta várias melhorias importantes para resolver as limitações dos métodos anteriores. Primeiro, mais de 1,8 milhão de traces foram gerados usando GPT-4 e programação em Python, enquanto um subconjunto de 293 mil exemplos foi selecionado para apresentar alta qualidade após rigorosas técnicas de filtragem. Estes exemplos garantem a inclusão de diversas sequências de pensamento e ação que são importantes na aprendizagem multimodal. Em segundo lugar, o TACO inclui um conjunto robusto de 15 ferramentas, incluindo OCR, localização de objetos e solucionadores matemáticos, permitindo que os modeladores lidem com tarefas complexas de forma eficaz. Terceiro, técnicas avançadas de filtragem e integração de dados melhoram o conjunto de dados, enfatizando a integração do pensamento-ação e promovendo melhores resultados de aprendizagem. Esta estrutura redefine a aprendizagem multimodal, permitindo que os modelos gerem um raciocínio coerente em várias etapas, ao mesmo tempo que integram ações perfeitamente, estabelecendo assim uma nova referência para o desempenho em situações complexas.
O desenvolvimento do TACO envolve treinamento em um conjunto de dados CoTA cuidadosamente selecionado com 293 mil instâncias retiradas de 31 fontes diferentes, incluindo o Genoma Visual. Esses conjuntos de dados contêm uma ampla gama de tarefas, como raciocínio matemático, reconhecimento visual de caracteres e percepção visual detalhada. É muito diversificado, com ferramentas fornecidas, incluindo localização de objetos e solucionadores baseados em linguagem que permitem uma ampla variedade de tarefas de pensamento e ação. A estrutura de treinamento combinou LLaMA3 como linguagem base com CLIP como entrada visual, criando assim uma forte estrutura multimodal. O ajuste fino desenvolveu o ajuste de hiperparâmetros que se concentra na redução das taxas de aprendizagem e no aumento do número de períodos de treinamento para garantir que os modelos possam resolver desafios complexos de múltiplas vias.
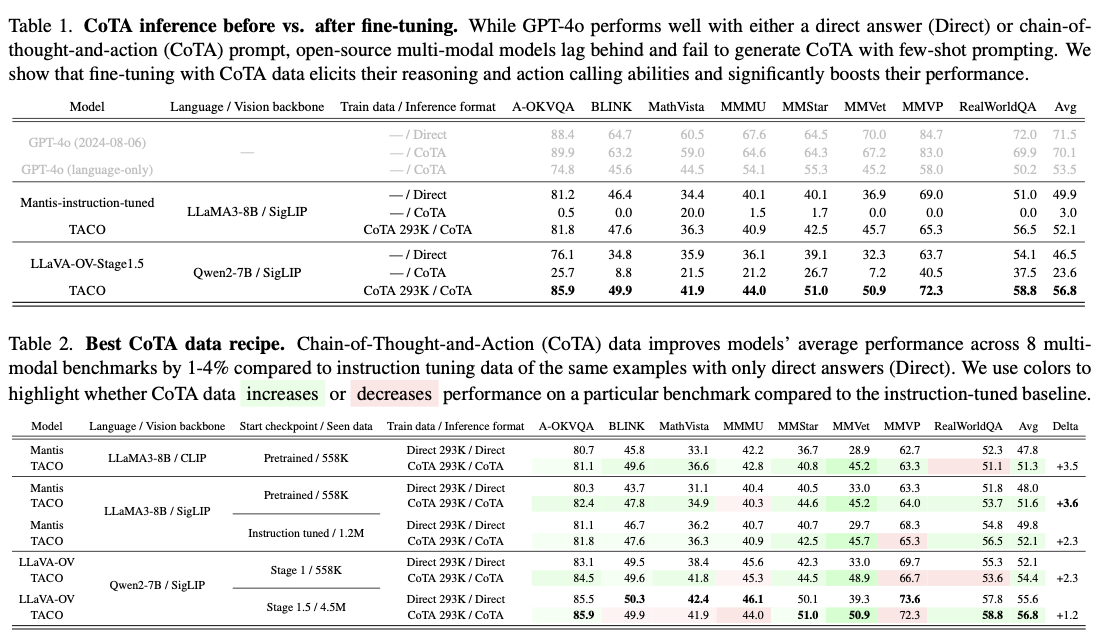
O desempenho da TACO em todos os oito parâmetros de referência demonstra o seu impacto significativo no desenvolvimento de competências de pensamento multimodal. O sistema alcançou uma melhoria média de precisão de 3,6% em relação às linhas de base ativadas por instrução, com ganhos de até 15% em tarefas MMVet envolvendo OCR e raciocínio matemático. Notavelmente, o conjunto de dados CoTA 293K de alta qualidade teve um desempenho significativamente melhor do que os conjuntos de dados maiores e menos refinados, sublinhando a importância da recolha de dados direccionada. Algumas melhorias de desempenho são alcançadas através da otimização de técnicas de hiperparâmetros, incluindo otimização de codificadores de visão e otimização de taxas de aprendizagem. Tabela 2: Os resultados mostram o melhor desempenho do TACO em comparação com os benchmarks, sendo este último considerado o melhor em tarefas complexas que envolvem a integração do pensamento e da ação.
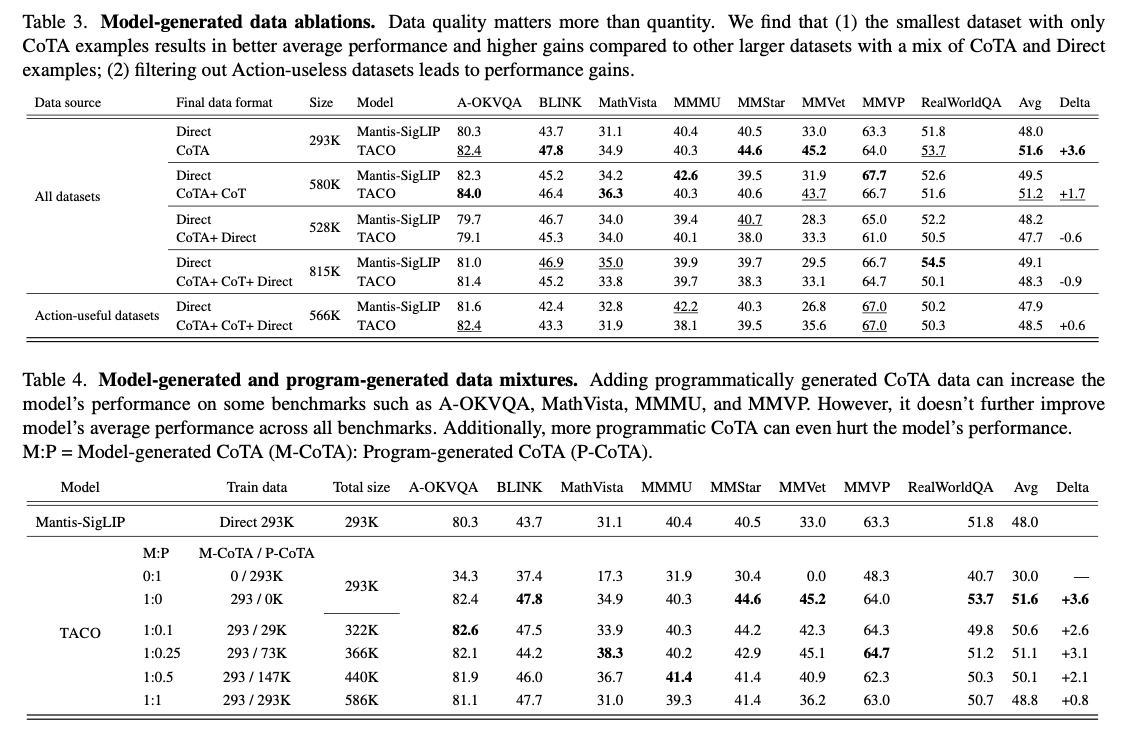

O TACO apresenta uma nova abordagem à modelação multi-acções que aborda eficazmente as principais deficiências tanto do raciocínio como das acções baseadas em ferramentas, utilizando conjuntos de dados sintéticos de alta qualidade e novos métodos de formação. A pesquisa supera as limitações dos modelos tradicionais ativados por instrução e seu desenvolvimento está preparado para mudar a face das aplicações do mundo real, desde respostas visuais a perguntas até tarefas complexas de raciocínio em várias etapas.
Confira Artigo, página GitHub, e página do projeto. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 65k + ML.
🚨 PRÓXIMO WEBINAR GRATUITO DE IA (15 DE JANEIRO DE 2025): Aumente a precisão do LLM com dados artificiais e inteligência–Participe deste webinar para obter insights práticos sobre como melhorar o desempenho e a precisão do modelo LLM e, ao mesmo tempo, proteger a privacidade dos dados.
Aswin AK é consultor da MarkTechPost. Ele está cursando seu diploma duplo no Instituto Indiano de Tecnologia, Kharagpur. Ele é apaixonado por ciência de dados e aprendizado de máquina, o que traz consigo uma sólida formação acadêmica e experiência prática na solução de desafios de domínio da vida real.
✅ [Recommended Read] Nebius AI Studio se expande com modelos de visão, novos modelos de linguagem, incorporados e LoRA (Aprimorado)


