
As interfaces gráficas do usuário (GUIs) desempenham um papel importante na interação humano-computador, fornecendo uma maneira para os usuários realizarem tarefas na web, desktop e plataformas móveis. A automação neste setor está mudando, melhorando potencialmente a produtividade e permitindo fluxos de trabalho contínuos sem a necessidade de intervenção manual. Agentes autônomos capazes de compreender e interagir com GUIs podem transformar fluxos de trabalho, especialmente em ambientes de trabalho repetitivos ou complexos. No entanto, a complexidade inerente e a diversidade das GUIs entre plataformas representam desafios significativos. Cada plataforma utiliza um design visual, espaços de ação e lógica de interação diferentes, o que dificulta a criação de soluções simples e robustas. O desenvolvimento de sistemas que possam navegar nessas áreas automaticamente e, ao mesmo tempo, generalizar entre plataformas continua sendo um desafio constante para os pesquisadores neste domínio.
Existem muitas barreiras técnicas para a automação de GUI no momento; o outro combina instruções em linguagem natural com várias GUIs visuais. As abordagens tradicionais geralmente dependem de representações textuais, como HTML ou árvores de acessibilidade, para modelar elementos GUI. Esses métodos são limitados porque as GUIs são de natureza visual e as abstrações textuais não conseguem capturar as nuances do design visual. Além disso, as representações de texto variam entre plataformas, resultando em dados diferentes e desempenho inconsistente. Essa incompatibilidade entre o ambiente visual das GUIs e a entrada de texto usada em aplicativos automatizados resulta em escalabilidade reduzida, tempos de decisão mais longos e generalização limitada. Além disso, muitos métodos atuais não são capazes de raciocínio multidimensional e básico, o que é essencial para a compreensão de ambientes visuais complexos.
As ferramentas e técnicas existentes tentaram enfrentar esses desafios com sucesso misto. Muitos sistemas dependem de modelos de código fechado para desenvolver habilidades de raciocínio e programação. Estes modelos utilizam frequentemente comunicação em linguagem natural para integrar processos de raciocínio, mas esta abordagem introduz perda de informação e carece de escalabilidade. Outra limitação comum é a natureza díspar do conjunto de dados de treinamento, que não fornece suporte completo para inferência e tarefas de inferência. Por exemplo, os conjuntos de dados muitas vezes enfatizam o apoio ou a inferência, mas não ambos, levando a modelos que se destacam numa área enquanto enfrentam dificuldades noutras. Esta seção restringe o desenvolvimento de soluções integradas para interações GUI independentes.
Pesquisadores da Universidade de Hong Kong e da Salesforce Research apresentaram AGUVIS (7B e 72B), uma estrutura unificada projetada para superar essas limitações usando observações puramente baseadas em teoria. AGUVIS elimina a dependência da apresentação textual e, em vez disso, concentra-se na entrada baseada em gráficos, alinhando o design do modelo com o ambiente visual das GUIs. O quadro inclui um espaço de ação consistente para todas as plataformas, o que facilita a atualização da plataforma. AGUVIS combina planejamento transparente e pensamento multidisciplinar para navegar em ambientes digitais complexos. Os pesquisadores criaram um grande conjunto de dados de trajetórias de agentes GUI, que foi usado para treinar o AGUVIS em um processo de duas etapas. A arquitetura modular da estrutura, que inclui um sistema de ação conectável, permite uma adaptação perfeita a novos ambientes e tarefas.
A estrutura AGUVIS usa um paradigma de treinamento em dois estágios equipar o modelo com habilidades de modelagem e raciocínio:
- Durante a primeira fase, o modelo se concentra no mapeamento e mapeamento de instruções de linguagem natural para objetos físicos em ambientes GUI. Esta seção usa uma estratégia básica de empilhamento, combinando vários pares de comando-ação em uma única captura de tela da GUI. Essa abordagem melhora a eficiência do treinamento, maximizando o uso de cada imagem sem sacrificar a precisão.
- A segunda fase introduz planejamento e raciocínio, treinando o modelo para executar tarefas de várias etapas em diferentes plataformas e situações. Esta seção inclui monólogos internos detalhados, que incluem descrições de observações, pensamentos e instruções de ação de baixo nível. Ao aumentar gradualmente a complexidade dos dados de treinamento, o modelo aprende a lidar com diversas tarefas com precisão e flexibilidade.
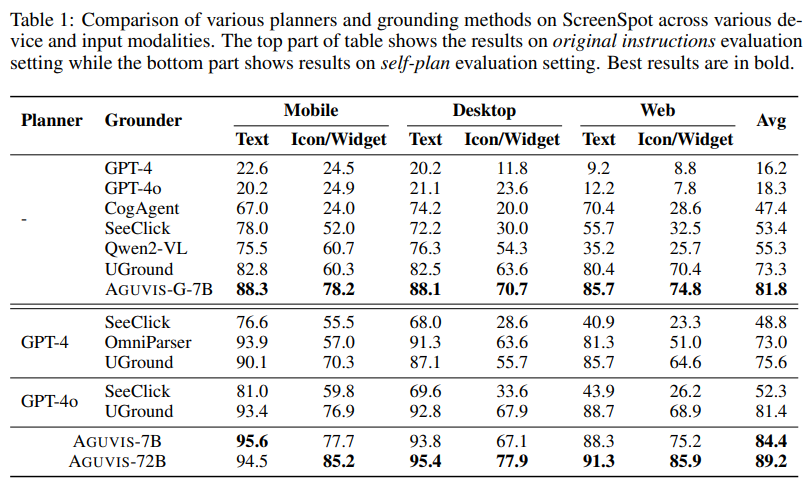
AGUVIS mostrou bons resultados em testes reais offline e online. No suporte GUI, o modelo alcançou uma precisão média de 89,2, que supera os melhores métodos em plataformas móveis, desktop e web. Em cenários online, o AGUVIS superou os modelos concorrentes com uma melhoria de 51,9% na taxa de sucesso de etapas durante tarefas de planejamento offline. Além disso, o modelo obteve uma redução de 93% no custo de inferência em comparação ao GPT-4o. Ao focar na inspeção visual e integrar um ambiente de ação unificado, o AGUVIS estabelece uma nova referência para automação de GUI, tornando-o o primeiro agente baseado em visão totalmente autônomo que pode concluir tarefas do mundo real sem depender de modelos de código fechado.
Principais conclusões da pesquisa da AGUVIS na área de automação de GUI:
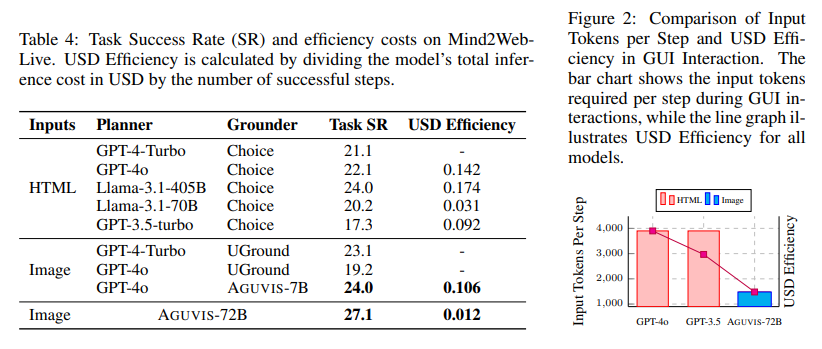
- AGUVIS usa entrada baseada em gráficos, reduzindo significativamente os custos de token e alinhando o modelo com o ambiente visual natural das GUIs. Essa abordagem resulta em um custo simbólico de apenas 1.200 para visualizações de imagens em 720p, em comparação com 6.000 para árvores de acessibilidade e 4.000 para visualizações baseadas em HTML.
- O modelo combina os estágios de configuração e planejamento, permitindo realizar operações de etapa única e de várias etapas de maneira eficaz. Somente o treinamento básico equipa o modelo para processar múltiplas instruções em uma única imagem, enquanto a fase de inferência melhora sua capacidade de implementar fluxos de trabalho complexos.
- A coleção AGUVIS integra e complementa conjuntos de dados existentes com dados sintéticos para apoiar o raciocínio híbrido e complementar. Isso resulta em um conjunto de dados diversificado e escalável, permitindo o treinamento de modelos robustos e flexíveis.
- O uso de comandos pyautogui e um sistema de ação conectável permite que o modelo generalize entre plataformas enquanto incorpora ações específicas da plataforma, como deslizar em dispositivos móveis.
- AGUVIS obteve resultados impressionantes em benchmarks básicos de GUI, com taxas de precisão de 88,3% em plataformas web, 85,7% em dispositivos móveis e 81,8% em desktops. Além disso, demonstrou eficiência superior, reduzindo os custos em dólares americanos em 93% em comparação com os modelos existentes.
Para concluir, a estrutura AGUVIS aborda os principais desafios em suporte, conceituação e automação de GUI. Sua abordagem baseada na visão elimina as ineficiências associadas à exibição de texto, enquanto sua interface interativa permite uma comunicação perfeita entre diversas plataformas. A Research fornece uma solução robusta para tarefas de GUI autônomas, com aplicações que vão desde ferramentas de produtividade até sistemas avançados de IA.
Confira eu Papel, Página GitHubde novo O projeto. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 60k + ML.
🚨 Tendências: LG AI Research Release EXAONE 3.5: Modelos de três níveis de IA bilíngue de código aberto oferecem seguimento de comando incomparável e insights profundos de conteúdo Liderança global em excelência em IA generativa….
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.
🧵🧵 [Download] Avaliação do relatório de trauma do modelo de linguagem principal (estendido)


