
Os modelos de linguagem visual (VLMs) estão ganhando destaque na inteligência artificial devido à sua capacidade de combinar dados visuais e textuais. Esses modelos desempenham um papel importante em áreas como compreensão de vídeo, interação humano-computador e aplicações multimídia, fornecendo ferramentas para responder perguntas, gerar insights e melhorar a tomada de decisões com base na entrada de vídeo. A necessidade de sistemas de processamento de vídeo eficientes está aumentando à medida que as tarefas baseadas em vídeo proliferam em todos os setores, desde aplicações privadas até aplicações médicas e de entretenimento. Apesar do progresso, lidar com a grande quantidade de informações visuais em vídeos ainda é um desafio fundamental no desenvolvimento de VLMs escaláveis e eficientes.
Um problema importante no reconhecimento de vídeo é que os modelos existentes muitas vezes dependem do processamento individual de cada quadro de vídeo, gerando milhares de tokens visuais. Esse processo consome extensos recursos computacionais e tempo, limitando a capacidade do modelo de lidar adequadamente com vídeos longos ou complexos. O desafio é reduzir a carga computacional e ao mesmo tempo capturar informações visuais e temporais relevantes. Sem uma solução, as tarefas que exigem processamento de vídeo em tempo real ou em grande escala tornam-se impraticáveis, criando a necessidade de novos métodos que equilibrem eficiência e precisão.
As soluções atuais tentam reduzir o número de tokens virtuais usando técnicas como pooling de quadros. Modelos como Video-ChatGPT e Video-LLaVA concentram-se em métodos de agregação espacial e temporal para compactar informações em nível de quadro em pequenos tokens. No entanto, esses métodos ainda geram muitos tokens, com modelos como MiniGPT4-Video e LLaVA-OneVision gerando milhares de tokens, resultando em um manuseio inadequado de vídeos longos. Esses modelos geralmente exigem ajuda para melhorar a eficiência dos tokens e o desempenho do processamento de vídeo, o que requer soluções mais eficientes para agilizar o gerenciamento de tokens.
Em resposta, pesquisadores da Salesforce AI Research apresentaram o BLIP-3-Video, um VLM avançado projetado especificamente para solucionar ineficiências no processamento de vídeo. O modelo inclui um “codificador temporal” que reduz significativamente os tokens virtuais necessários para representar o vídeo. Ao limitar a contagem de tokens a apenas 16 a 32 tokens, o modelo melhora muito a eficiência da computação sem sacrificar o desempenho. Esta inovação permite que o BLIP-3-Video execute operações baseadas em vídeo com custo computacional muito baixo, tornando-se um passo importante em direção a soluções de compreensão de vídeo não supervisionadas.

O codificador transitório do BLIP-3-Video é a base de sua capacidade de processar vídeos com eficiência. Ele usa um método de agrupamento de atenção espaço-temporal que pode ser aprendido que extrai apenas os tokens mais informativos de cada quadro de vídeo. O sistema agrega os dados espaciais e temporais de cada quadro, convertendo-os em um conjunto coerente de tokens de nível de vídeo. O modelo inclui um codificador de visão, um token em nível de quadro e um modelo de linguagem automático que gera texto ou respostas com base na entrada de vídeo. O codificador temporal usa modelos sequenciais e mecanismos de atenção para preservar informações importantes de vídeo e, ao mesmo tempo, reduzir dados redundantes, garantindo que o BLIP-3-Video possa lidar bem com tarefas complexas de vídeo.
Os resultados de desempenho mostram a alta eficiência do BLIP-3-Video em comparação com os modelos principais. O modelo atinge precisão de resposta de consulta de vídeo (QA) semelhante a modelos de última geração, como o Tarsier-34B, usando apenas uma fração dos tokens virtuais. Por exemplo, Tarsier-34B usa 4.608 tokens para 8 quadros de vídeo, enquanto BLIP-3-Video reduz esse número para apenas 32 tokens. Apesar desta redução, o BLIP-3-Video ainda mantém um forte desempenho, alcançando uma pontuação de 77,7% no benchmark MSVD-QA e 60,0% no benchmark MSRVTT-QA, ambos conjuntos de dados amplamente utilizados para respostas a perguntas baseadas em vídeo. . Esses resultados enfatizam a capacidade do modelo de manter altos níveis de precisão enquanto opera com menos recursos.
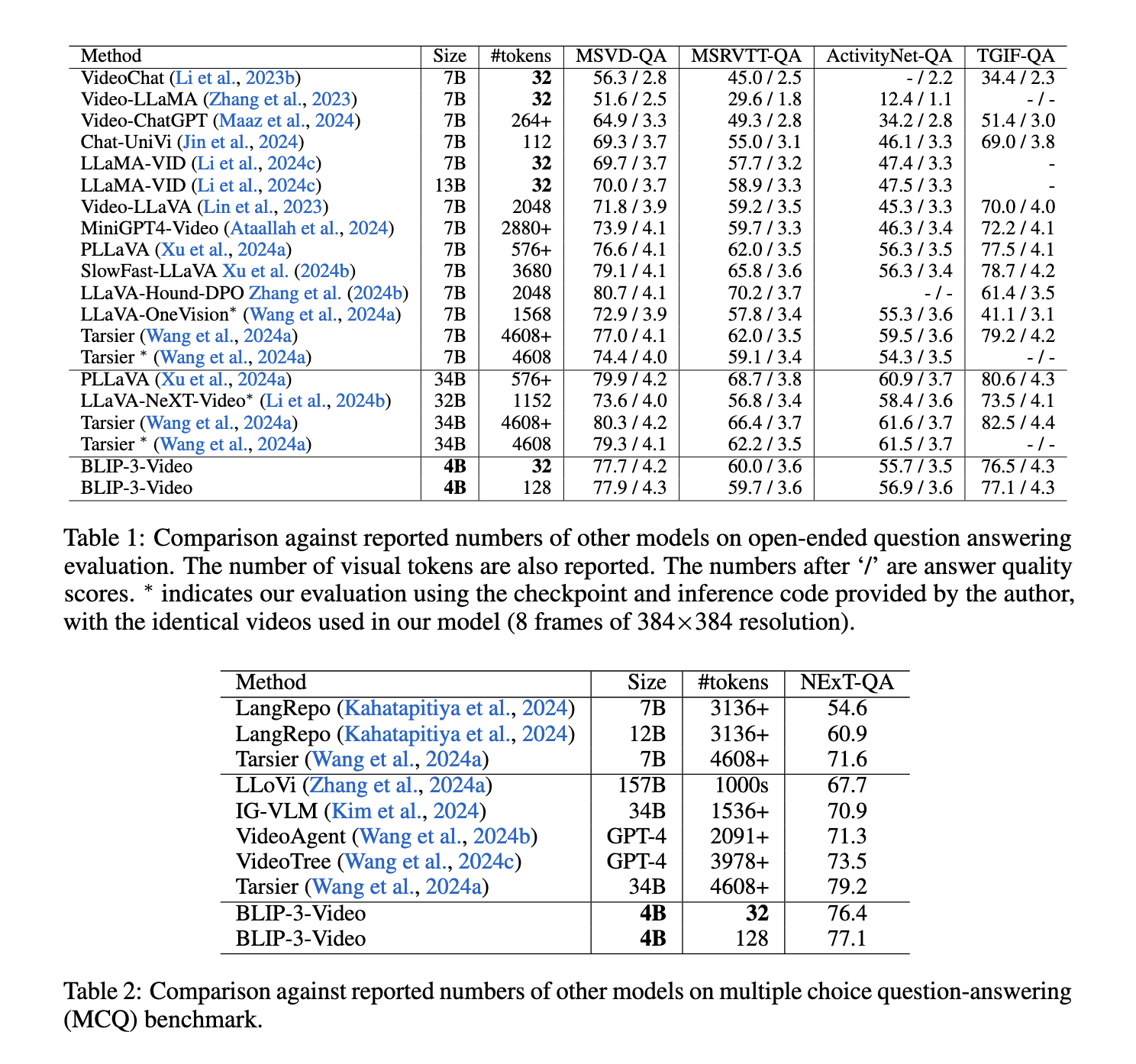
O modelo teve um desempenho particularmente bom em tarefas de resposta a perguntas de múltipla escolha, como o conjunto de dados NExT-QA, com pontuação de 77,1%. Isto é especialmente notável porque apenas 32 tokens são usados por vídeo, muito menos do que muitos modelos concorrentes. Além disso, no conjunto de dados TGIF-QA, que precisa compreender ações e transições dinâmicas em vídeos, o modelo alcançou uma precisão impressionante de 77,1%, destacando ainda mais sua eficácia no tratamento de consultas de vídeo complexas. Esses resultados estabelecem o BLIP-3-Video como um dos modelos de token mais eficientes disponíveis, fornecendo precisão comparável ou superior a modelos muito maiores e, ao mesmo tempo, reduzindo drasticamente a sobrecarga computacional.

Concluindo, o BLIP-3-Video aborda o desafio da ineficiência do token no processamento de vídeo, introduzindo um codificador temporal que reduz o número de tokens virtuais enquanto mantém o alto desempenho. Desenvolvido pela pesquisa da Salesforce AI, o modelo mostra que é possível processar dados de vídeo complexos com muito menos tokens do que se pensava anteriormente, fornecendo uma solução poderosa e altamente eficiente para tarefas de compreensão de vídeo. Este desenvolvimento representa um avanço significativo nos modelos de linguagem visual, abrindo caminho para o uso prático da IA em aplicações baseadas em vídeo em diversos setores.
Confira Artigo e Projeto. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[Upcoming Live Webinar- Oct 29, 2024] A melhor plataforma para modelos ajustados: mecanismo de inferência Predibase (atualizado)
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


