: Família de modelos de recuperação de código conquistando a primeira posição no benchmark CoIR e suportando 12 linguagens de programação")
A recuperação de código tornou-se essencial para desenvolvedores no desenvolvimento de software moderno, permitindo acesso eficiente a trechos de código e documentação relevantes. Ao contrário da recuperação de texto tradicional, que lida efetivamente com consultas em linguagem natural, a recuperação de código deve enfrentar desafios únicos, como a diversidade estrutural das linguagens de programação, dependências e compatibilidade de contexto. Com ferramentas como GitHub Copilot ganhando popularidade, sistemas avançados de recuperação de código estão se tornando cada vez mais importantes para melhorar a produtividade e reduzir erros.
Os modelos de recuperação existentes muitas vezes lutam para capturar nuances específicas do programa, como sintaxe, fluxo de controle e dependências variáveis. Essas limitações impedem a solução de problemas no resumo de código, na depuração e na tradução entre idiomas. Embora os modelos de recuperação de texto tenham apresentado melhorias significativas, eles não atendem a certos requisitos de recuperação de código, destacando a necessidade de modelos especializados que melhorem a precisão e a eficiência em uma variedade de tarefas de programação. Modelos como CodeBERT, CodeGPT e UniXcoder abordaram recursos de recuperação de código usando estruturas pré-treinadas. No entanto, eles são limitados em escalabilidade e versatilidade devido ao seu pequeno tamanho e foco específico na tarefa. Embora o Voyage-Code tenha introduzido um grande potencial, a sua natureza de código fechado limita uma adoção mais ampla. Isso destaca a necessidade crítica de um sistema de recuperação de código de código aberto para generalização em múltiplas funções.
Pesquisadores da Salesforce AI Research apresentaram CodeXEmbeduma família de modelos de incorporação de código aberto projetados especificamente para descoberta de código e texto. Esses modelos, lançados em três tamanhos, Código de incorporação SFR-400M_R, Código de incorporação SFR-2B_Re 7 bilhões de parâmetros, que se referem a diversas linguagens de programação e funções de recuperação. O pipeline de treinamento do CodeXEmbed integra 12 linguagens de programação e transforma cinco estágios diferentes de codificação em uma estrutura unificada. Ao suportar várias funções, como texto para código, código para texto e recuperação híbrida, o modelo amplia os limites do que os sistemas de recuperação podem alcançar, proporcionando flexibilidade e desempenho sem precedentes.
CodeXEmbed usa uma abordagem inovadora que transforma tarefas relacionadas ao código em uma estrutura unificada de perguntas e respostas, permitindo que você faça uma variedade de coisas em todas as situações diferentes. A recuperação de texto para código mapeia consultas de linguagem natural para trechos de código relacionados, facilitando tarefas como codificação e depuração. A recuperação de código para texto cria descrições e resumos de código, melhorando a documentação e compartilhando informações. A recuperação híbrida combina texto e dados de codificação, lidando com eficácia com consultas complexas que exigem informações técnicas e descritivas. O treinamento do modelo maximiza a perda diferencial para otimizar o alinhamento da resposta à consulta e, ao mesmo tempo, minimiza o impacto de dados irrelevantes. Técnicas avançadas, como adaptação de baixo nível e pooling de tokens, melhoram a eficiência sem sacrificar o desempenho.
Nos testes, ele foi testado em vários benchmarks. No benchmark CoIR, um conjunto completo de dados de teste de recuperação de código que consiste em 10 subconjuntos e mais de 2 milhões de entradas, o modelo de 7 bilhões de parâmetros alcançou uma melhoria de desempenho de mais de 20% em comparação com o Voyage-Code de última geração. modelo. . Notavelmente, os modelos de parâmetros de 400 milhões e 2 mil milhões também funcionaram muito além do Voyage-Code, mostrando a escala dos edifícios nos vários tamanhos. Além disso, CodeXEmbed tem um desempenho muito bom em tarefas de recuperação de texto, com um modelo de 7 bilhões de parâmetros alcançou uma média de 60 pontos no benchmark BEIR, uma série de 15 conjuntos de dados que inclui diversas tarefas de recuperação, como resposta a consultas e verificação de fatos.
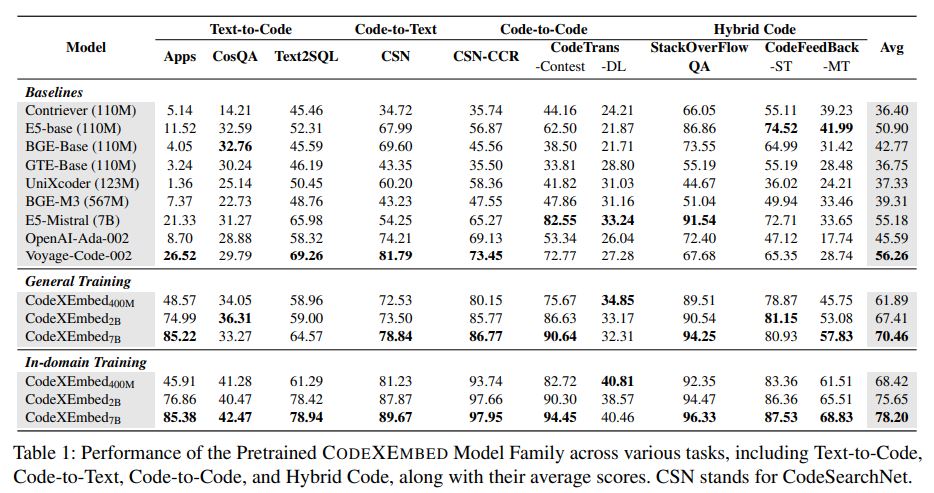
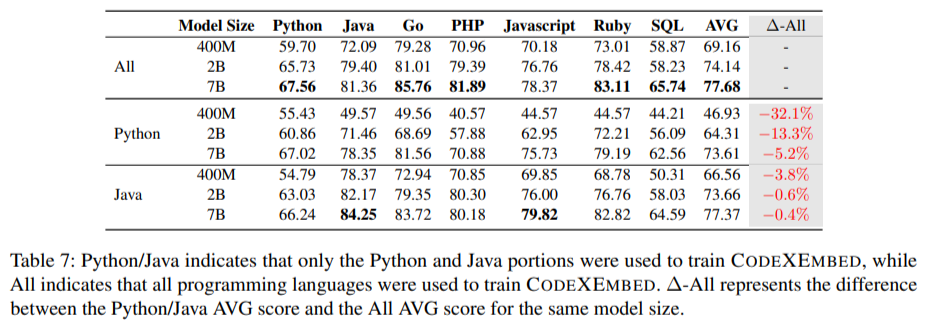
Os modelos podem codificar a recuperação e desenvolver sistemas de recuperação-recuperação para recuperação (RAG). Por exemplo, quando usado em tarefas em nível de repositório, como conclusão de código e solução de problemas, o modelo de 7 bilhões de parâmetros alcançou resultados significativos em benchmarks como RepoEval e SWE-Bench-Lite. RepoEval, que se concentra na eliminação de código em nível de repositório, obteve uma melhoria máxima de precisão de 1 quando o modelo encontrou trechos contextualmente relevantes. No SWE-Bench-Lite, um conjunto de dados selecionado para solução de problemas do GitHub, o CodeXEmbed supera os sistemas de recuperação tradicionais.
As principais conclusões do estudo destacam as contribuições e os impactos do CodeXEmbed na melhoria da adoção de código:
- O modelo de 7 bilhões de parâmetros alcançou desempenho de última geração, com melhoria de mais de 20% no benchmark CoIR e resultados competitivos no BEIR. Flexibilidade demonstrada em todas as tarefas de codificação e script.
- Os modelos de parâmetros de 400 milhões e 2 bilhões fornecem alternativas viáveis para áreas onde os recursos computacionais são limitados.
- Os modelos abordam uma ampla gama de aplicações relacionadas a código, integrando 12 linguagens de programação e cinco classes de recuperação.
- Ao contrário de programas fechados como o Voyage-Code, o CodeXEmbed incentiva a pesquisa e a inovação voltadas para a comunidade.
- A integração com sistemas avançados de recuperação de produtividade melhora os resultados de tarefas como conclusão de código e solução de problemas.
- O uso de tokens de perda variável e pooling melhora a precisão e a adaptabilidade da recuperação.
Concluindo, a introdução do Salesforce à família CodeXEmbed de descoberta de código. Esses modelos apresentam flexibilidade e escalabilidade incomparáveis, alcançando desempenho de última geração no benchmark CoIR e excelente desempenho em tarefas de recuperação de texto. Uma estrutura multilíngue e multitarefa integrada, que suporta 12 linguagens de programação, posiciona o CodeXEmbed como uma ferramenta essencial para desenvolvedores e pesquisadores. Sua acessibilidade de código aberto incentiva a inovação impulsionada pela comunidade, ao mesmo tempo que preenche a lacuna entre a linguagem natural e a descoberta de código.
Confira Papel, Modelo 400M, de novo Modo 2Beu. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 65k + ML.
🚨 Recomendar plataforma de código aberto: Parlant é uma estrutura que muda a forma como os agentes de IA tomam decisões em situações voltadas para o cliente. (Promovido)
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.
📄 Conheça 'Height': ferramenta independente de gerenciamento de projetos (patrocinado)


: um benchmark abrangente para analisar como os modelos de IA avaliam a segurança e a consciência contextual em todas as diferentes situações do mundo real")