
Modelos linguísticos de grande escala (LLMs), úteis para responder perguntas e gerar conteúdo, estão agora sendo treinados para lidar com tarefas que exigem pensamento avançado, como resolver problemas complexos em matemática, ciências e dedução lógica. O desenvolvimento de habilidades de raciocínio dentro dos LLMs está no centro da pesquisa em IA, que visa capacitar modelos para executar processos de raciocínio sequencial. O desenvolvimento desta área pode permitir aplicações robustas em vários campos, permitindo que modelos naveguem em tarefas complexas de raciocínio de forma independente.
Um desafio constante no desenvolvimento do LLM é desenvolver suas habilidades de pensamento sem feedback externo. Os LLMs atuais se saem bem em tarefas relativamente simples, mas precisam de ajuda com pensamento sequencial ou em múltiplas etapas, onde a resposta é obtida por meio de uma série de etapas vinculadas logicamente. Esta limitação limita o uso de LLMs a tarefas que requerem uma progressão lógica de ideias, como resolver problemas matemáticos complexos ou analisar dados de forma sistemática. Portanto, desenvolver habilidades de pensamento independente nos LLMs tornou-se importante para aumentar a sua eficácia e eficiência em tarefas onde o pensamento é importante.
Os pesquisadores tentaram várias abordagens baseadas no tempo para enfrentar esses desafios, a fim de melhorar o raciocínio. Outro método proeminente é a motivação por Cadeia de Pensamento (CoT), que incentiva o modelador a dividir um problema complexo em partes gerenciáveis, tomando cada decisão passo a passo. Esta abordagem permite que os modelos sigam uma abordagem sistemática para a resolução de problemas, tornando-os mais adequados para tarefas que requerem lógica e precisão. Outros métodos, como a Árvore do Pensamento e o Programa do Pensamento, permitem que os LLMs explorem múltiplas formas de pensar, oferecendo diferentes abordagens para a resolução de problemas. Embora eficientes, estes métodos focam principalmente na melhoria do tempo de execução e não melhoram a capacidade de raciocínio durante a fase de treinamento do modelo.
Pesquisadores da Salesforce AI Research introduziram uma nova estrutura chamada LaTent Reasoning Optimization (LaTRO). LaTRO é um método inovador que transforma o processo de inferência em um problema de amostragem discreta, proporcionando uma melhoria intrínseca no poder de inferência do modelo. Esta estrutura permite que os LLMs refinem as suas formas de pensar através de uma abordagem auto-recompensadora, permitindo-lhes avaliar e melhorar as suas respostas sem depender de recompensas externas ou feedback supervisionado. Ao focar na estratégia de autoaperfeiçoamento, o LaTRO melhora o desempenho cognitivo no nível de treinamento, criando uma mudança fundamental na forma como os modelos entendem e lidam com tarefas complexas.
O método LaTRO é baseado na localização de padrões de inferência a partir de distribuições latentes e na otimização desses padrões usando várias técnicas. LaTRO usa uma abordagem única de interesse próprio, amostrando várias maneiras de pensar sobre uma determinada questão. Cada método é avaliado com base em sua probabilidade de produzir a resposta correta, o modelo então ajusta seus parâmetros para priorizar os métodos com maiores taxas de sucesso. Este processo iterativo permite ao modelo melhorar simultaneamente a sua capacidade de gerar padrões de pensamento de alto nível e testar a eficácia desses padrões, promovendo assim um ciclo contínuo de auto-aperfeiçoamento. Ao contrário dos métodos tradicionais, o LaTRO não depende de modelos de recompensa externos, tornando-o uma estrutura independente e flexível para o desenvolvimento do pensamento em LLMs. Além disso, ao mudar para a otimização de inferência na fase de treinamento, o LaTRO reduz efetivamente as demandas de computação durante a inferência, tornando-o uma solução eficiente em termos de recursos.

O desempenho do LaTRO foi rigorosamente testado em vários conjuntos de dados, com resultados que sublinham a sua eficácia. Por exemplo, nos testes do conjunto de dados GSM8K, que inclui desafios de raciocínio matemático, o LaTRO mostrou uma melhoria significativa de 12,5% em relação aos modelos básicos na precisão do disparo zero. Este ganho representa uma melhoria acentuada na capacidade de raciocínio do modelo sem exigir treinamento específico para tarefas. Além disso, o LaTRO superou os modelos de ajuste fino supervisionados em 9,6%, demonstrando sua capacidade de fornecer resultados mais precisos, mantendo a eficiência. No conjunto de dados ARC-Challenge, que se concentra no raciocínio lógico, o LaTRO superou os modelos de referência e os modelos ajustados, aumentando significativamente o desempenho. Para o Mistral-7B, uma das estruturas LLM utilizadas, a precisão de tiro zero no GSM8K melhorou de 47,8% nos modelos básicos para 67,3% no LaTRO com decodificação gananciosa. No teste de consistência, quando vários métodos de inferência foram considerados, o LaTRO obteve uma melhoria adicional no desempenho, com uma precisão impressionante de 90,5% para modelos Phi-3.5 em GSM8K.
Além dos resultados quantitativos, a abordagem autocompensadora do LaTRO reflete-se nas suas melhorias qualitativas. Esta abordagem ensina efetivamente os LLMs a explorar formas de pensar internamente, produzindo respostas concisas e logicamente coerentes. A análise experimental revela que o LaTRO permite que os LLMs utilizem melhor o seu poder de pensamento latente, mesmo em situações complexas, reduzindo assim a dependência de organismos de avaliação externos. Este desenvolvimento tem implicações para muitos sistemas, especialmente em domínios onde a coerência lógica e o pensamento sistemático são importantes.
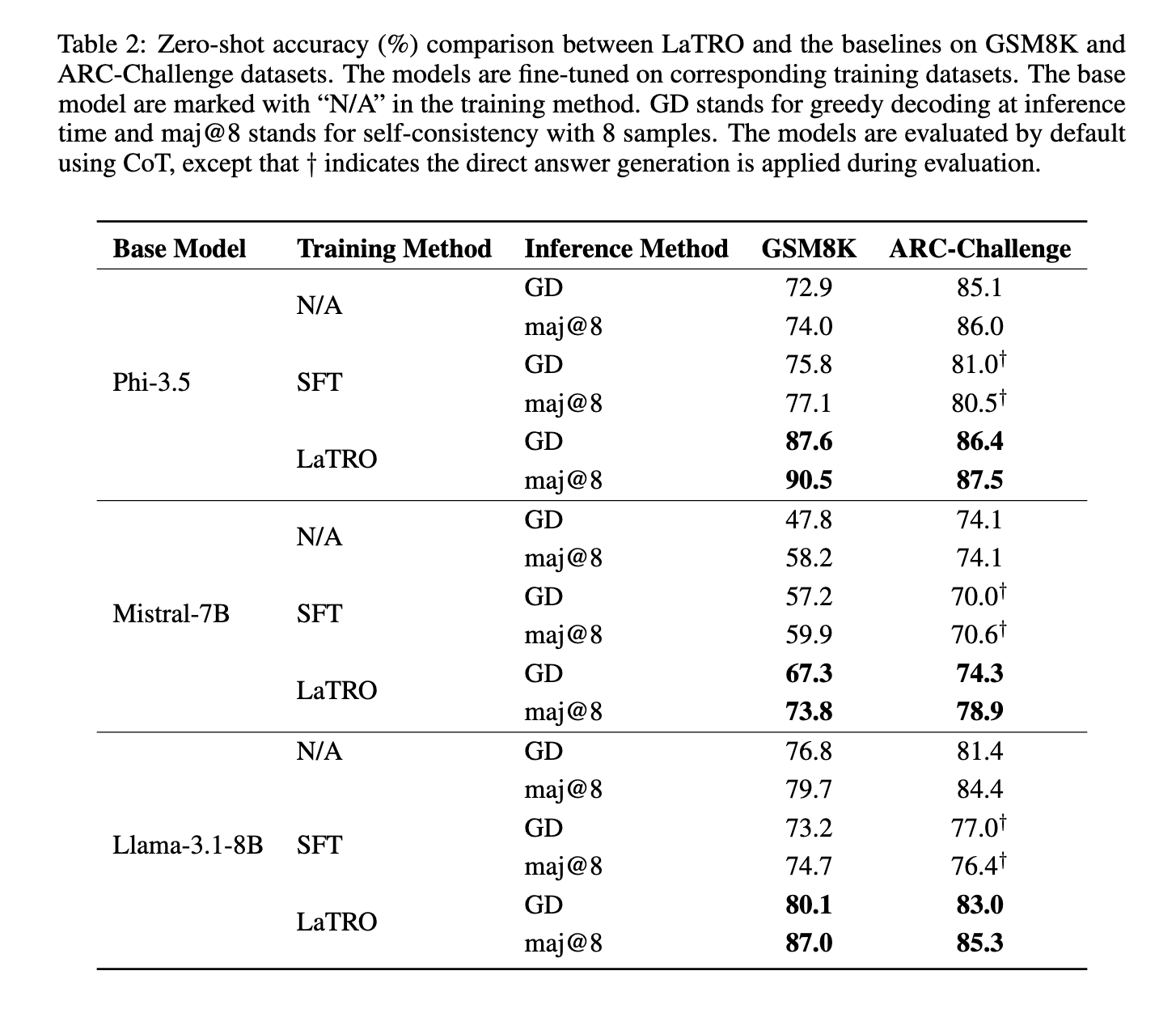
Concluindo, o LaTRO oferece uma solução nova e eficaz para melhorar o pensamento do LLM sobre o interesse próprio, estabelecendo um novo padrão para o modelo de autodesenvolvimento. Esta estrutura permite que LLMs pré-treinados liberem seus pontos fortes latentes em atividades de pensamento, concentrando-se no desenvolvimento do pensamento durante o período de treinamento. Este desenvolvimento na pesquisa de IA da Salesforce destaca o poder do pensamento independente em modelos de IA e mostra que os LLMs podem se transformar em solucionadores de problemas altamente eficazes. LaTRO representa um salto significativo, aproximando a IA de alcançar capacidades de pensamento autônomo em uma variedade de domínios.
Confira Página de papel e GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[FREE AI WEBINAR] Usando processamento inteligente de documentos e GenAI em serviços financeiros e transações imobiliárias
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
🐝🐝 O próximo evento ao vivo do LinkedIn, 'Uma plataforma, possibilidades multimodais', onde o CEO da Encord, Eric Landau, e o chefe de engenharia de produto, Justin Sharps, falarão sobre como estão reinventando o processo de desenvolvimento de dados para ajudar as equipes a construir modelos de IA revolucionários , rápido.


: oferece aumento de até 2 a 4x na velocidade de computação e redução de 56% no tamanho do modelo")