
Modelos de linguagem em larga escala (LLMs) com capacidades de processamento de conteúdo de longo alcance revolucionaram as aplicações técnicas em todos os domínios. Desenvolvimentos recentes permitiram casos de uso complexos, incluindo suporte de codificação em nível de sala, análise de vários documentos e desenvolvimento de agentes autônomos. Estes modelos mostram capacidades notáveis no tratamento de informações contextuais extensas, o que requer métodos avançados para recuperar e integrar eficazmente informações dispersas. No entanto, o estado atual do mundo apresenta desafios significativos na manutenção de um desempenho consistente em tarefas cognitivas complexas. Embora os LLMs tenham alcançado uma precisão quase idêntica em situações de agulha no palheiro, persistem grandes limitações de desempenho quando confrontados com desafios de raciocínio contextual dinâmico de longo prazo. Esta diversidade destaca a necessidade crítica de novas formas de melhorar a compreensão do contexto e as capacidades de raciocínio em sistemas de inteligência artificial.
A pesquisa de modelagem contextual de linguagem de longo prazo emergiu como uma fronteira importante na inteligência artificial, explorando novas maneiras de melhorar as capacidades de processamento de modelos linguísticos de grande escala. Dois métodos principais de pesquisa ganharam destaque: metodologias centradas em modelos e metodologias centradas em dados. As estratégias orientadas para modelos envolvem modificações direcionadas às estruturas existentes, incluindo ajustes sutis nas incorporações espaciais e nos mecanismos de atenção. Os pesquisadores também propuseram projetos arquitetônicos exclusivos destinados a melhorar a eficiência computacional e a compreensão contextual. Ao mesmo tempo, os métodos de mineração de dados concentram-se em técnicas sofisticadas de engenharia de dados, como o pré-treinamento contínuo em sequências estendidas e o uso de modelos especializados ou anotações humanas para obter dados de treinamento refinados. Estes esforços de investigação multifacetados visam colectivamente ultrapassar os limites da compreensão situacional e das capacidades de raciocínio dos modelos linguísticos, abordando os principais desafios nos sistemas de inteligência artificial.
Pesquisadores da Universidade Chinesa de Hong Kong, da Universidade de Pequim, da Universidade de Tsinghua e da Tencent apresentam SEALONGum método robusto de autoaperfeiçoamento projetado para melhorar as habilidades de raciocínio para modelos de linguagem de grande escala em contextos de longo prazo. Ao amostrar múltiplas hipóteses e usar uma pontuação de risco mínimo de Bayes (MBR), o método prioriza resultados que mostram alta consistência em todas as respostas geradas. Esta abordagem aborda o desafio crítico da falta de objetos em modelos de linguagem, identificando e priorizando os mecanismos de raciocínio que são mais consistentes com os resultados cumulativos do modelo. A metodologia fornece duas estratégias principais de otimização: otimização supervisionada usando resultados de alta pontuação e otimização de preferência que inclui trajetórias de pontuação alta e baixa. Testes experimentais em todos os principais modelos de linguagem mostram melhorias significativas de desempenho, com aumentos significativos nas habilidades de raciocínio contextual de longo prazo, sem depender de anotações de modelos humanos externos ou especializados.
SEALONG apresenta um novo método de dois estágios para desenvolver raciocínio de contexto longo em grandes modelos de linguagem. A abordagem concentra-se na autocorreção e otimização do modelo, usando um método de teste rigoroso baseado em clustering MBR. Ao gerar múltiplas trajetórias de pensamento para cada entrada, o método avalia a qualidade da saída usando consistência semântica e incorporando similaridade. Este método permite que o modelo identifique e priorize métodos de pensamento confiáveis, comparando diferentes resultados gerados. Esta técnica utiliza um método de Monte Carlo para encontrar cada trajetória, distinguindo efetivamente entre respostas possíveis e mais precisas. Notavelmente, o SEALONG mostra melhorias significativas de desempenho sem depender de anotações humanas externas ou intervenções de modelos especializados.
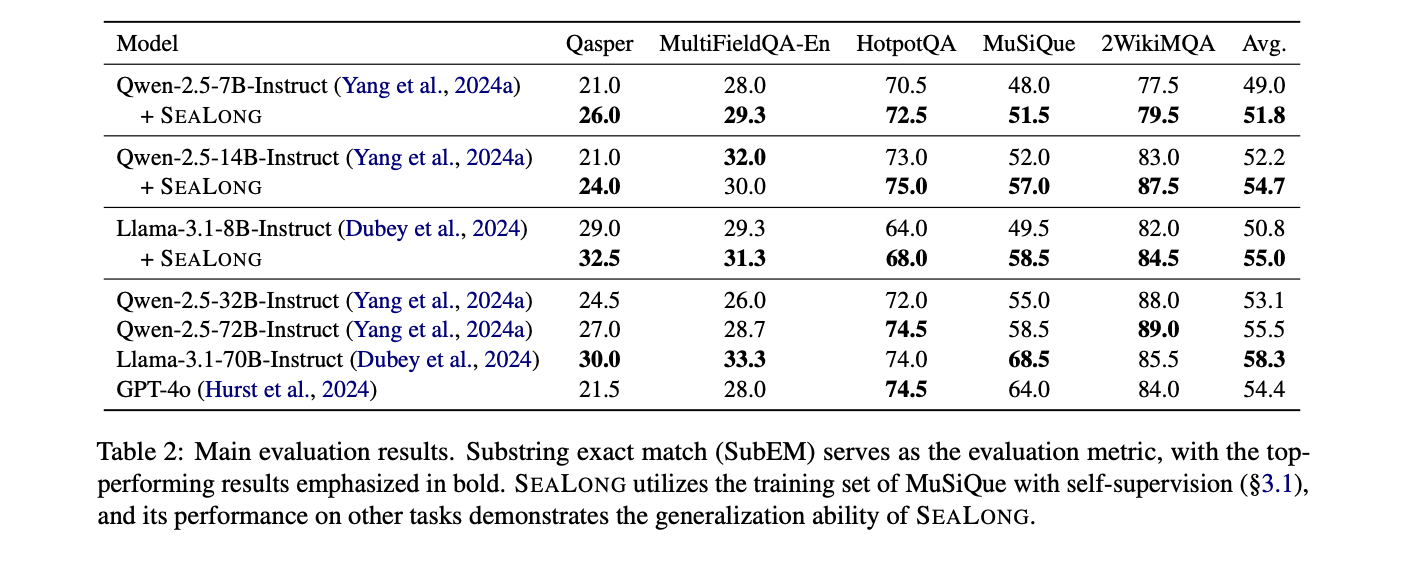
Este estudo apresenta SEALONGUma maneira inovadora de melhorar as habilidades de pensamento de modelos de linguagem longa usando métodos de autoaperfeiçoamento. SEALONG representa um avanço significativo na abordagem de desafios importantes relacionados à compreensão do contexto e ao raciocínio em sistemas de inteligência artificial. Ao demonstrar a capacidade dos modelos para desenvolver os seus próprios processos de raciocínio sem a intervenção de especialistas externos, o estudo oferece uma abordagem promissora para um maior desenvolvimento do modelo. A abordagem proposta não só melhora o desempenho em todas as tarefas de raciocínio contextual de longo prazo, mas também fornece uma estrutura para pesquisas futuras em inteligência artificial. Esta abordagem inovadora tem implicações importantes para o desenvolvimento de grandes modelos linguísticos, potencialmente colmatando a lacuna entre as actuais capacidades de IA e o raciocínio mais avançado, semelhante ao humano.
Confira Página de papel e GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
🎙️ 🚨 'Avaliação de vulnerabilidade de um modelo de linguagem grande: uma análise comparativa de técnicas de clustering vermelho' Leia o relatório completo (Promovido)
Asjad é consultor estagiário na Marktechpost. Ele está cursando B.Tech em engenharia mecânica no Instituto Indiano de Tecnologia, Kharagpur. Asjad é um entusiasta do aprendizado de máquina e do aprendizado profundo que pesquisa regularmente a aplicação do aprendizado de máquina na área da saúde.
🧵🧵 [Download] Avaliação do relatório do modelo de risco linguístico principal (ampliado)


