
A inteligência artificial revolucionou a geração de código, com modelos de linguagem em larga escala (LLMs) de códigos agora essenciais para a engenharia de software. Esses modelos oferecem suporte a tarefas de integração, depuração e otimização de código por meio da análise de grandes bases de código. No entanto, o desenvolvimento destes LLMs orientados a códigos enfrenta desafios significativos. O treinamento requer dados de alto nível seguindo instruções, muitas vezes coletados por meio de anotações humanas trabalhosas ou informações significativas de grandes modelos proprietários. Embora esses métodos melhorem o desempenho do modelo, eles apresentam problemas em termos de acessibilidade, licenciamento e custo dos dados. À medida que cresce a necessidade de formas transparentes, eficientes e acessíveis de treinar esses modelos, novas soluções que superem esses desafios sem sacrificar o desempenho tornam-se essenciais.
A divulgação de informações de modelos proprietários pode violar restrições de licenciamento, limitando seu uso em projetos de código aberto. Outra limitação importante é que os dados de crowdsourcing, embora valiosos, são caros e difíceis de medir. Outros métodos de código aberto, como OctoCoder e OSS-Instruct, tentaram superar essas limitações. No entanto, muitas vezes exigem mais parâmetros de desempenho e requisitos de transparência. Essas limitações enfatizam a necessidade de uma solução que mantenha alto desempenho e esteja alinhada aos valores de código aberto e transparência.
Pesquisadores da Universidade de Illinois Urbana-Champaign, Northeastern University, Universidade da Califórnia em Berkeley, ServiceNow Research, Hugging Face, Roblox e Cursor AI introduziram uma nova técnica chamada. SelfCodeAlign. Este método permite que os LLMs treinem de forma independente, gerando pares de instruções de alta qualidade sem intervenção humana ou dados de modelo proprietários. Ao contrário de outros modelos que dependem de anotações humanas ou da transferência de informações de modelos maiores, o SelfCodeAlign gera instruções automaticamente extraindo vários conceitos de codificação de dados iniciais. O modelo então usa essas ideias para criar funções únicas e gerar respostas múltiplas. Essas respostas são combinadas com casos de teste automatizados e verificadas em um ambiente sandbox controlado. Somente as respostas bem-sucedidas são usadas para editar as instruções finais, para garantir que os dados sejam precisos e variados.
A metodologia do SelfCodeAlign começa extraindo trechos de código inicial de um grande corpus, com foco na variedade e qualidade. O primeiro conjunto de dados, “Stack V1”, é filtrado para selecionar 250.000 funções Python de alta qualidade de um conjunto de 5 milhões, usando uma verificação de qualidade rigorosa. Depois de selecionar esses trechos, o modelo divide cada um deles em conceitos-chave de codificação, como conversão de tipo de dados ou correspondência de padrões. Em seguida, gera tarefas e respostas com base nesses conceitos, fornecendo níveis de dificuldade e categorias para garantir variedade. Essa abordagem em várias etapas garante dados de alta qualidade e minimiza distorções, tornando o modelo adaptável a uma variedade de desafios de codificação.
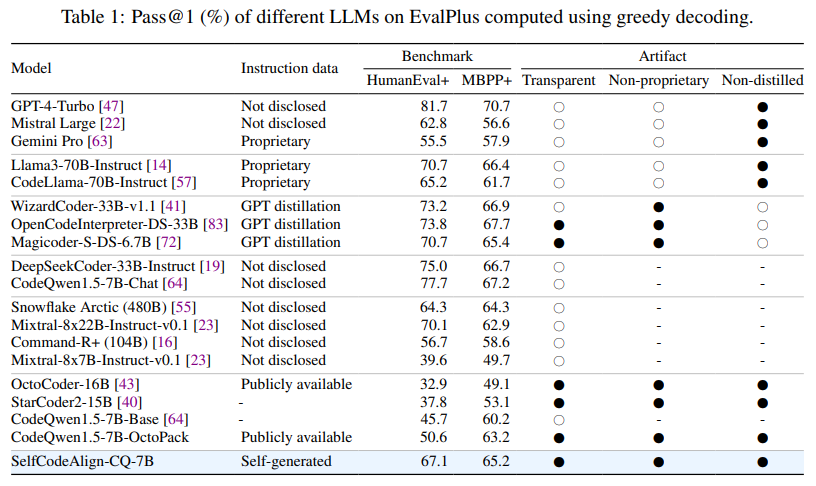
O desempenho do SelfCodeAlign foi rigorosamente testado com o modelo CodeQwen1.5-7B. Comparado com modelos como o CodeLlama-70B, o SelfCodeAlign superou muitas soluções de ponta, alcançando uma pontuação HumanEval+ pass@1 de 67,1%, que é 16,5 pontos maior que seu modelo básico, o CodeQwen1.5-7B-OctoPack. O modelo teve um desempenho consistentemente bom em uma ampla gama de tarefas, incluindo geração de tarefas e classes, programação e codificação de ciência de dados, mostrando que o SelfCodeAlign melhora o desempenho em modelos de tamanhos diferentes, de parâmetros de 3B a 33B. Em tarefas de produção em nível de classe, o SelfCodeAlign alcançou uma taxa de aprovação@1 de 27% em nível de classe e 52,6% em nível de método, superando a maioria dos modelos baseados em instrução. Esses resultados destacam a capacidade do SelfCodeAlign de produzir modelos que não são apenas funcionais, mas também de tamanho pequeno, aumentando a acessibilidade.
Em termos de eficiência, no benchmark EvalPerf, que avalia a eficiência do código, o modelo recebeu um Differential Performance Score (DPS) de 79,9%. Isto mostra que as soluções produzidas pela SelfCodeAlign correspondem ou excedem a eficiência de 79,9% de soluções comparáveis em vários testes de eficiência. Além disso, SelfCodeAlign alcançou uma taxa de aprovação @1 de 39% em tarefas de alinhamento de código, corrigindo, convertendo e modificando códigos corretamente. Este desempenho consistente em vários benchmarks ressalta a eficácia do método de dados autogerados do SelfCodeAlign.
As principais conclusões do sucesso do SelfCodeAlign estão revolucionando o campo da codificação de LLMs:
- Transparência e acessibilidade: SelfCodeAlign é um método totalmente aberto e transparente que não requer dados de modelo proprietários, tornando-o ideal para pesquisadores focados em IA comportamental e replicação.
- Benefícios de eficiência: Com um DPS de 79,9% em benchmarks de eficiência, o SelfCodeAlign mostra que modelos pequenos e treinados de forma independente podem alcançar resultados impressionantes, equivalentes a modelos proprietários muito maiores.
- Versatilidade entre tarefas: O modelo se destaca em uma variedade de tarefas de codificação, incluindo integração de código, depuração e aplicativos de ciência de dados, enfatizando sua aplicabilidade em vários domínios na engenharia de software.
- Custos e benefícios de licenciamento: A capacidade do SelfCodeAlign de operar sem dados personalizados caros ou filtragem LLM proprietária o torna altamente escalável e economicamente viável, abordando limitações comuns aos métodos tradicionais de alinhamento de instruções.
- Adaptabilidade para pesquisas futuras: O pipeline do modelo pode incluir campos além da codificação, mostrando-se promissor para adaptação a diferentes domínios tecnológicos.

Concluindo, SelfCodeAlign fornece uma nova solução para os desafios dos modelos instrucionais de geração de código. Ao eliminar a necessidade de anotações humanas e a dependência de modelos proprietários, o SelfCodeAlign oferece uma alternativa escalonável, transparente e altamente eficiente que pode redefinir como os códigos LLM são desenvolvidos. A pesquisa mostra que o alinhamento independente, sem refinamento, pode produzir resultados semelhantes a modelos grandes e caros, marcando um avanço importante em LLMs de código aberto para geração de código.
Confira Papel de novo Página GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[Sponsorship Opportunity with us] Promova sua pesquisa/produto/webinar para mais de 1 milhão de leitores mensais e mais de 500 mil membros da comunidade
Sana Hassan, estagiária de consultoria na Marktechpost e estudante de pós-graduação dupla no IIT Madras, é apaixonada pelo uso de tecnologia e IA para enfrentar desafios do mundo real. Com um profundo interesse em resolver problemas do mundo real, ele traz uma nova perspectiva para a interseção entre IA e soluções da vida real.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️
")

