
Os modelos de texto para imagem (T2I) tiveram um rápido progresso nos últimos anos, permitindo a geração de imagens complexas com base na entrada de linguagem natural. No entanto, mesmo os modelos T2I avançados precisam de ajuda para capturar e exibir com precisão toda a semântica de uma determinada informação, resultando em imagens que podem perder detalhes importantes, como múltiplos tópicos ou certas relações espaciais. Por exemplo, produzir uma composição como “um gato com asas voando sobre um campo de donuts” apresenta desafios e obstáculos devido à inerente complexidade e especificidade da informação. À medida que estes modelos tentam compreender e replicar as nuances dos significados textuais, surgem as suas limitações. Além disso, o desenvolvimento destes modelos é muitas vezes dificultado pela necessidade de grandes conjuntos de dados anotados e de alta qualidade, o que os torna intensivos em recursos e em mão-de-obra. O resultado é um gargalo na obtenção de modelos que possam produzir imagens confiáveis e estatisticamente precisas em uma ampla variedade de condições.
O principal problema enfrentado pelos pesquisadores é a necessidade de ajuda na criação de imagens verdadeiramente fiéis de descrições textuais complexas. Essa inconsistência geralmente leva à falta de itens, ao posicionamento incorreto ou à renderização inconsistente de vários itens. Por exemplo, quando solicitados a gerar uma imagem de uma cena de parque com um banco, um pássaro e uma árvore, os modelos T2I podem precisar manter as relações espaciais corretas entre essas entidades, resultando em imagens irrealistas. As soluções atuais tentam melhorar essa confiabilidade ajustando os dados supervisionados com anotações ou instruções de texto com legendas repetidas. Embora estes métodos mostrem progresso, eles dependem fortemente da disponibilidade de extensos dados definidos pelo homem. Essa dependência introduz maiores custos e complexidade de treinamento. Assim, existe uma necessidade premente de uma solução que possa melhorar a fidelidade da imagem sem depender de anotação de dados manual, cara e demorada.
Muitas soluções existentes tentaram enfrentar esses desafios. Uma abordagem popular é o treinamento supervisionado, onde os modelos T2I são treinados usando pares imagem-texto de alta qualidade ou conjuntos de dados selecionados manualmente. Outra linha de pesquisa concentra-se na compreensão de modelos T2I e dados de preferência humana por meio de aprendizagem por reforço. Isso envolve medir e pontuar imagens com base em quão bem elas correspondem às descrições do texto e usar essas pontuações para ajustar ainda mais os modelos. Embora esses métodos tenham se mostrado promissores na melhoria do alinhamento, eles dependem de extensas anotações manuais e de dados de alta qualidade. Além disso, foi explorada a combinação de componentes adicionais, como caixas delimitadoras ou estruturas de objetos, para orientar a geração de imagens. No entanto, estas técnicas muitas vezes exigem muito esforço humano e processamento de dados, tornando-as impraticáveis em escala.
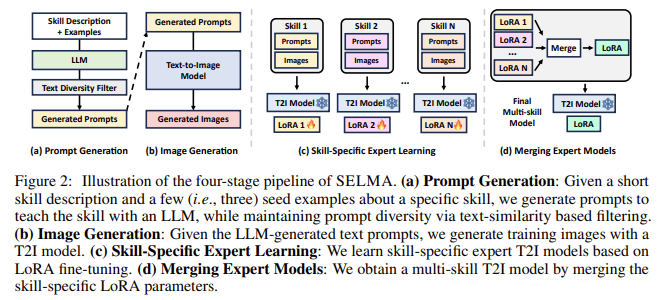
Pesquisadores da Universidade da Carolina do Norte em Chapel Hill apresentaram SELMA: Sespecífico para matar Eespecialista euassalariados e Mir com UMDados gerados por uto. SELMA apresenta uma nova maneira de desenvolver modelos T2I sem depender de dados definidos por humanos. Essa abordagem aproveita os recursos dos Large Language Models (LLMs) para gerar automaticamente informações específicas de habilidades. Os modelos T2I usam então esses alertas para gerar imagens correspondentes, criando um rico conjunto de dados sem intervenção humana. Os pesquisadores usaram uma técnica conhecida como Adaptação de Baixo Rank (LoRA) para ajustar os modelos T2I a esses conjuntos de dados específicos de habilidades, resultando em modelos especialistas específicos para múltiplas habilidades. Ao combinar esses modelos especializados, a SELMA cria um modelo T2I integrado com múltiplas habilidades que pode produzir imagens de alta qualidade com maior fidelidade e alinhamento semântico.
SELMA opera em um pipeline de quatro estágios. Primeiro, informações específicas sobre habilidades são geradas usando LLMs, o que ajuda a garantir a diversidade no conjunto de dados. A segunda fase envolve a geração de imagens correspondentes com base nesses recursos utilizando modelos T2I. Em seguida, o modelo é ajustado usando módulos LoRA para focar em cada habilidade. Finalmente, estes especialistas especializados são combinados para produzir um modelo T2I robusto, capaz de lidar com diversas informações. Este processo de fusão reduz efetivamente os conflitos de informação entre diferentes habilidades, resultando em um modelo que pode produzir imagens mais precisas do que os modelos tradicionais de múltiplas habilidades. Em média, a SELMA apresentou uma melhoria de +2,1% no benchmark de alinhamento de texto TIFA e uma melhoria de +6,9% no benchmark DSG, demonstrando a sua eficácia na melhoria da fiabilidade.
O desempenho do SELMA foi validado em relação aos modelos T2I de última geração, como Stable Diffusion v1.4, v2 e XL. Resultados robustos mostraram que o SELMA melhorou a confiabilidade das métricas de texto e de preferência humana em vários benchmarks, incluindo PickScore, ImageReward e Human Preference Score (HPS). Por exemplo, o ajuste fino com SELMA melhorou o HPS em 3,7 pontos e as métricas de preferência das pessoas em 0,4 no PickScore e 0,39 no ImageReward. Notavelmente, a otimização com conjuntos de dados gerados automaticamente foi comparada à otimização com dados reais. Os resultados sugerem que o SELMA é um método custo-efetivo sem extensa anotação manual. Os pesquisadores descobriram que o ajuste fino de um modelo T2I forte, como o SDXL, usando imagens produzidas por um modelo fraco, como o SD v2, levou a ganhos de desempenho, sugerindo o potencial de generalização de modelos T2I fracos para fortes.
Principais conclusões do estudo SELMA:
- Melhoria de desempenho: A SELMA melhorou os modelos T2I em +2,1% no TIFA e +6,9% nos benchmarks DSG.
- Geração de dados econômica: Os conjuntos de dados gerados automaticamente alcançaram desempenho semelhante aos conjuntos de dados definidos por humanos.
- Métricas de preferência das pessoas: Melhorou o HPS em 3,7 pontos e aumentou PickScore e ImageReward em 0,4 e 0,39, respectivamente.
- Normalização fraca a forte: O ajuste fino com imagens do modelo fraco melhorou o desempenho do modelo T2I forte.
- Dependência reduzida da anotação humana: SELMA demonstrou que modelos T2I de alta qualidade podem ser desenvolvidos sem extensa anotação manual de dados.

Concluindo, o SELMA fornece um método robusto e eficiente para melhorar a confiabilidade e o alinhamento semântico dos modelos T2I. Ao usar dados gerados automaticamente e um novo método de agregação para especialistas especializados, o SELMA elimina a necessidade de dados caros definidos por humanos. Esta abordagem aborda as principais limitações dos atuais modelos T2I e prepara o terreno para desenvolvimentos futuros na geração de texto para imagem.
Confira Papel de novo O projeto. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.


