
Os modelos linguísticos de grande escala (LLMs) estão melhorando na estimativa e no tratamento de instâncias longas. Como são utilizados em larga escala, tem havido uma necessidade crescente de suporte eficaz para projeções de alto desempenho. No entanto, a implementação adequada desses LLMs de longo contexto apresenta desafios relacionados ao cache de valor-chave (KV), que armazena ativações anteriores de valor-chave para evitar o recálculo. Mas à medida que o texto que eles manipulam se torna mais longo, o aumento da memória e a necessidade de acessá-la para cada geração de token levam a um rendimento menor ao renderizar LLMs com conteúdo mais longo.
Os métodos existentes enfrentam três problemas principais: degradação da precisão, redução insuficiente de memória e o importante tópico do atraso na gravação. Técnicas para remover dados antigos do cache ajudam a economizar memória, mas podem levar à perda de precisão, especialmente em tarefas como entrevistas. Maneiras como Pouca atenção é poderosamantém todos os dados armazenados em cache na GPU, acelerando os cálculos, mas não reduzindo os requisitos de memória o suficiente para lidar com documentos muito longos. A solução básica para isso é mover alguns dados da GPU para a CPU para economizar memória, mas esse método fica mais lento porque a recuperação de dados da CPU leva tempo.
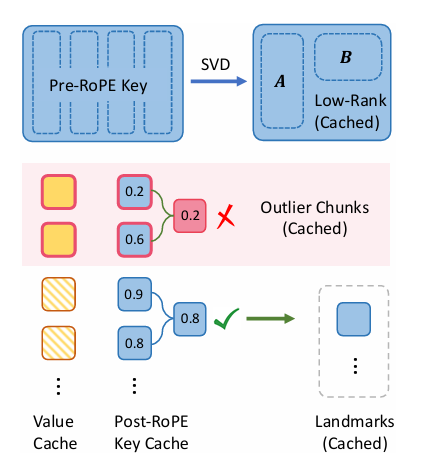
Chaves Pré-RoPE eles são algum tipo de dado possuem uma estrutura simples, o que facilita a compactação e o bom armazenamento. Eles diferem entre as sequências, mas são variáveis em muitas partes dessa sequência, permitindo que sejam mais estressados durante cada sequência. Isso ajuda a manter apenas dados importantes na GPU, enquanto outros dados podem ser armazenados na CPU sem afetar significativamente a velocidade e a precisão do sistema. Este método consegue um manuseio rápido e eficiente de documentos longos por LLMs, otimizando o uso de memória e armazenando cuidadosamente dados importantes.
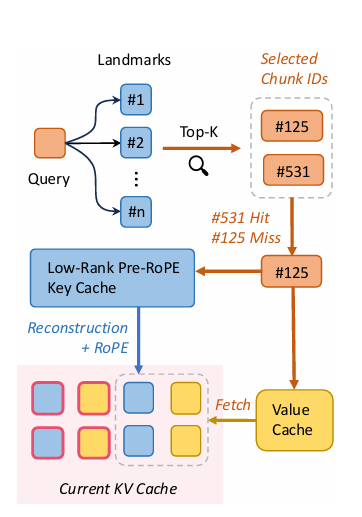
Um grupo de pesquisadores de Universidade Carnegie Mellon de novo ByteDança propôs um método chamado ShadowKVum sistema LLM de alto conteúdo para conteúdo longo que mantém um cache de chave de baixo nível e um cache de valor de carga para reduzir o consumo de memória de lotes grandes e sequências longas. Para reduzir a latência de decodificação, ShadowKV usa um método intuitivo de seleção de pares de valores-chave (KV), criando apenas os pares de KV necessários que se sobrepõem conforme necessário.
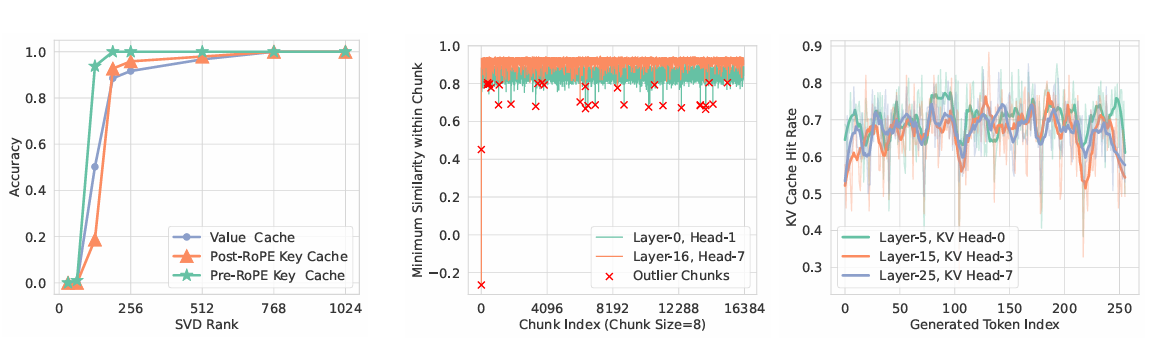
O algoritmo ShadowKV é dividido em duas fases principais: pré-preenchimento e decodificação. Na fase de pré-preenchimento, ele compacta os caches de chaves com posições de baixo nível e remove os caches de valores da memória da CPU, para ativar. SVD no cache de chaves pré-RoPE e a divisão dos caches de chaves pós-RoPE em fragmentos com atributos locais são calculados. Outliers, identificados pela similaridade de cosseno entre essas frações, são armazenados na memória estática da GPU, enquanto os pontos de referência associados são armazenados na memória da CPU. Durante a decodificação, ShadowKV integra estimativa de atenção baseada em componentes para pontuação alta, reconstrói caches críticos a partir de suposições de baixo nível e usa caches CUDA com reconhecimento de cache para reduzir a computação. 60%, cria apenas pares KV significativos. O conceito de “largura de banda igual” é usado pelo ShadowKV, ele carrega dados de forma eficiente para atingir a largura de banda 7,2 TB/s de A100 GPU, isto é 3,6 vezes sua memória de largura de banda. Testando ShadowKV em uma ampla gama de benchmarks, incluindo O Governador, O banco longoe Needle In A Haystack e modelos semelhantes Lhama-3.1-8B, Lhama-3-8B-1M, GLM-4-9B-1M, É 9B-200K, Phi-3-Mini-128Kde novo Qwen2-7B-128Ké mostrado que ShadowKV pode suportar até 6 vezes tamanhos de lote maiores, excedendo até mesmo o desempenho alcançável com tamanho de lote infinito sob a suposição de memória GPU infinita.
Concluindo, o método proposto pelos pesquisadores denominado ShadowKV é um sistema avançado de previsão LLM para conteúdos longos. ShadowKV otimiza a utilização da memória da GPU usando um cache de chave de baixo nível e um cache de valor carregado, permitindo tamanhos de cluster maiores. Reduz a latência de codificação com menos atenção à precisão, aumentando a velocidade de processamento e mantendo a precisão constante. Este método pode ser a base para futuras pesquisas no crescente campo dos Big Language Models!
Confira Papel de novo Página GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[Sponsorship Opportunity with us] Promova sua pesquisa/produto/webinar para mais de 1 milhão de leitores mensais e mais de 500 mil membros da comunidade
Divyesh é estagiário de consultoria na Marktechpost. Ele está cursando BTech em Engenharia Agrícola e Alimentar pelo Instituto Indiano de Tecnologia, Kharagpur. Ele é um entusiasta de Ciência de Dados e Aprendizado de Máquina que deseja integrar essas tecnologias avançadas no domínio agrícola e resolver desafios.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


