
Modelos linguísticos de larga escala (LLMs) revolucionaram o processamento de linguagem natural, mostrando notáveis capacidades de generalização em uma ampla variedade de tarefas. No entanto, devido à fraca adesão às instruções, estes modelos enfrentam um desafio significativo na produção de resultados formatados corretamente, como JSON. Esta limitação representa um obstáculo significativo para aplicações orientadas por IA que requerem resultados LLM sistemáticos integrados nos seus fluxos de dados. À medida que aumenta a procura de resultados controlados e estruturados dos LLMs, os investigadores enfrentam uma necessidade urgente de desenvolver métodos que possam garantir uma formatação precisa, mantendo ao mesmo tempo as capacidades de poderosos modelos de geração de linguagem.
Os pesquisadores exploraram várias maneiras de reduzir o desafio da produção com formato restrito em LLMs. Esses métodos podem ser divididos em três grupos principais: ajuste de pré-geração, controle de geração e análise de pós-geração. O ajuste da geração anterior envolvia a modificação dos dados ou comandos de treinamento para alinhá-los com determinados parâmetros de formato. Mecanismos de controle em geração intervêm durante o processo de decodificação, usando técnicas como JSON Schema, expressões regulares ou gramáticas livres de contexto para garantir a conformidade do formato. No entanto, estes métodos muitas vezes comprometem a qualidade da resposta. As técnicas de análise pós-geracional refinam a saída bruta em formatos estruturados usando algoritmos de pós-processamento. Embora cada abordagem ofereça vantagens únicas, todas elas enfrentam limitações na medição da precisão do formato e na qualidade e generalização da resposta.
Pesquisadores da Academia de Inteligência Artificial de Pequim, AstralForge AI Lab, Instituto de Tecnologia de Computação, Academia Chinesa de Ciências, Universidade de Ciência Eletrônica e Tecnologia da China, Instituto de Tecnologia Harbin, Faculdade de Computação e Ciência de Dados, Universidade Tecnológica de Nanyang propuseram. Esboçoum kit de ferramentas inovador projetado para melhorar o desempenho dos LLMs e garantir a produção de resultados formatados. Este framework apresenta um conjunto de esquemas para definir o trabalho de diversas tarefas de PNL, permitindo aos usuários definir suas necessidades específicas, incluindo objetivos de trabalho, sistemas de rotulagemde novo informações de formato de saída. O Sketch permite a geração pronta para uso de LLMs para tarefas não padrão, mantendo a integridade e a compatibilidade do formato de saída.
As principais contribuições da estrutura incluem:
- facilitar o funcionamento do LLM através da utilização de esquemas previamente definidos
- melhorando o desempenho por meio da criação de conjuntos de dados e otimização de modelos baseados em LLaMA3-8B-Instruct
- incluindo parâmetros de gravação em bloco para controle preciso do formato de saída.
Essas melhorias melhoram a confiabilidade e a precisão dos resultados do LLM, tornando o Sketch uma solução versátil para uma variedade de aplicações de PNL em ambientes industriais e de pesquisa.
A arquitetura do Sketch possui quatro etapas principais: seleção de esquema, resumo do trabalho, embalando rapidamentede novo uma geração. Os usuários primeiro selecionam o esquema apropriado em um conjunto predefinido que corresponde às suas necessidades de tarefa de PNL. Durante a execução da tarefa, os usuários preenchem o esquema selecionado com informações específicas da tarefa, criando uma instância da tarefa no formato JSON. Uma etapa rápida de empacotamento converte automaticamente a entrada da tarefa em informações estruturadas para interações LLM, incluindo definição de tarefa, estrutura de rótulo, formato de saída e dados de entrada.

Na fase de produção, o Sketch pode gerar respostas diretamente ou utilizar métodos de controle mais precisos. Opcionalmente, inclui lm-format-enforcer, que usa uma gramática livre de contexto para garantir a conformidade do formato de saída. Além disso, o Sketch usa uma ferramenta de esquema JSON para validar a saída, reamostrar ou lançar exceções para saída não compatível. Essa estrutura permite formatação controlada e fácil interação com LLMs em várias tarefas de PNL, agilizando o processo para os usuários enquanto mantém a precisão da saída e a consistência do formato.

Sketch-8B aprimora a capacidade do LLaMA3-8B-Instruct de gerar dados estruturados que aderem às restrições do esquema JSON em uma variedade de tarefas. O processo de otimização concentra-se em dois aspectos importantes: garantir a adesão estrita às restrições do esquema JSON e promover um desempenho robusto. Para conseguir isso, dois conjuntos de dados de destino foram criados: dados de tarefas de PNL e dados de acompanhamento de esquema.
Os dados de tarefas de PNL incluem mais de 20 conjuntos de dados, incluindo classificação de texto, geração de texto e extração de informações, e 53 cenários de tarefas. Os dados de esquema a seguir incluem 20.000 dados de ajuste fino gerados a partir de 10.000 esquemas JSON diferentes. O método de ajuste fino melhora a aderência ao formato e o desempenho da tarefa de PNL usando o método de conjunto de dados misto. O objetivo de treinamento é formulado como a maximização da probabilidade logarítmica da sequência de saída correta, dados os dados de entrada. Esta abordagem visa melhorar a aderência do modelo a vários formatos de saída e melhorar as suas capacidades para o trabalho de PNL.
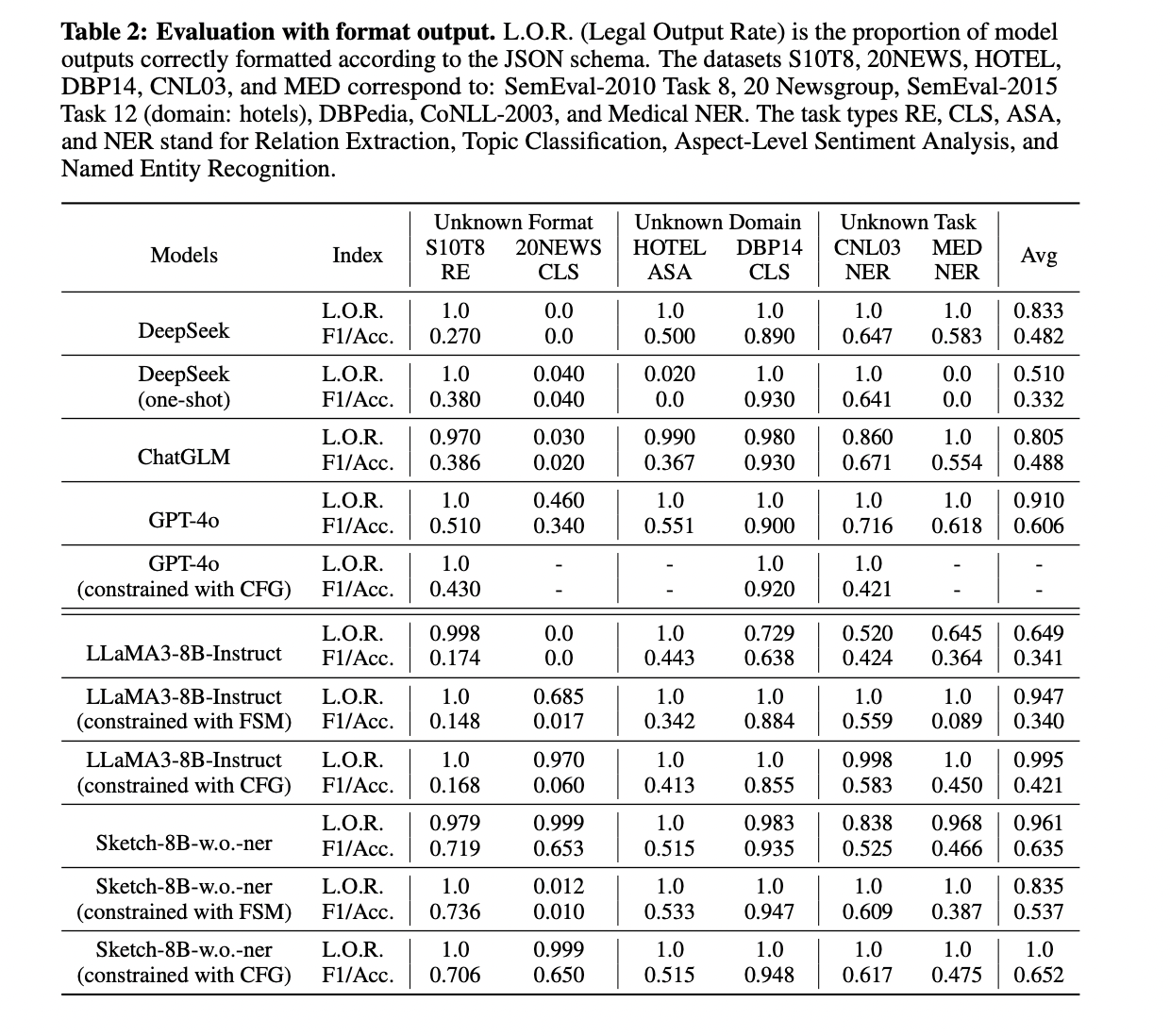
O teste do Sketch-8B-wo-ner mostra suas fortes capacidades de produção em todos os formatos, domínios e funções desconhecidos. Na adesão ao esquema, Sketch-8B-wo-ner atinge uma taxa média de produção formal de 96,2% sob condições não forçadas, superando significativamente a linha de base do LLaMA3-8B-Instruct de 64,9%. Essa melhoria é especialmente perceptível em formatos complexos como 20NEWS, onde Sketch-8B-wo-ner mantém alto desempenho enquanto LLaMA3-8B-Instruct falha completamente.
As comparações de desempenho revelam que o Sketch-8B-wo-ner supera consistentemente o LLaMA3-8B-Instruct para todas as estratégias de decodificação e conjuntos de dados. Comparado com modelos convencionais como DeepSeek, ChatGLM e GPT-4o, Sketch-8B-wo-ner mostra desempenho superior em conjuntos de dados de formato desconhecido e resultados comparáveis em conjuntos de dados de domínio desconhecido. No entanto, enfrenta algumas limitações em conjuntos de dados de atividades anônimas devido ao pequeno tamanho do modelo.
Os experimentos também destacam os efeitos consistentes dos métodos de decodificação restritos (FSM e CFG) no desempenho da tarefa. Embora esses métodos possam melhorar as medições formais de resultados, eles nem sempre melhoram as pontuações dos testes de desempenho, especialmente para conjuntos de dados com formatos de saída complexos. Isto sugere que os atuais métodos de decodificação restritos podem não ser igualmente confiáveis para aplicações de PNL do mundo real.
Este estudo apresenta Esboçoprogresso significativo na simplificação e otimização do uso de modelos de macrolinguagem. Ao introduzir uma abordagem baseada em esquemas, aborda eficazmente os desafios de gerar resultados estruturados e integrar modelos. As principais inovações da estrutura incluem a estrutura completa do esquema da descrição da tarefa, preparação robusta de dados e modelagem estratégica para melhorar o desempenho, e a integração de uma estrutura de registro estruturada para controle preciso dos resultados.
Os resultados dos testes mostram de forma convincente a superioridade do modelo Sketch-8B bem configurado em aderir aos formatos de saída especificados para todas as diversas tarefas. O desempenho de conjuntos de dados bem planejados e personalizados, especialmente os dados de esquema a seguir, reflete-se na melhoria do desempenho do modelo. O diagrama não apenas melhora o desempenho prático dos LLMs, mas também abre caminho para resultados mais confiáveis e compatíveis com o formato em diversas atividades de PNL, marcando um grande passo em direção a tornar os LLMs mais acessíveis e eficazes em aplicações do mundo real.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)
Asjad é consultor estagiário na Marktechpost. Ele está cursando B.Tech em engenharia mecânica no Instituto Indiano de Tecnologia, Kharagpur. Asjad é um entusiasta do aprendizado de máquina e do aprendizado profundo que pesquisa regularmente a aplicação do aprendizado de máquina na área da saúde.
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)


