
Modelos de linguagem visual em larga escala surgiram como ferramentas poderosas para a compreensão multimodal, mostrando capacidades impressionantes na interpretação e geração de conteúdo que combina informação visual e escrita. Esses modelos, como LLaVA e suas variantes, ajustam modelos de linguagem em larga escala (LLMs) para dados de instrução visual para executar tarefas visuais complexas. No entanto, a criação de um conjunto de dados educacionais virtuais de alta qualidade apresenta desafios significativos. Esses conjuntos de dados exigem uma variedade de imagens e documentos de diversas atividades para gerar uma variedade de consultas, cobrindo áreas como detecção de objetos, percepção visual e legenda de imagens. A qualidade e diversidade desses conjuntos de dados afetam diretamente o desempenho do modelo, conforme evidenciado pela melhoria significativa do LLaVA em relação aos métodos anteriores de alta qualidade em trabalhos como GQA e VizWiz. Apesar desses avanços, os modelos atuais enfrentam limitações devido à lacuna processual entre codificadores visuais pré-treinados e modelos linguísticos, o que dificulta sua capacidade de generalização e representação de recursos.
Os pesquisadores fizeram avanços significativos na abordagem dos desafios dos modelos de percepção da linguagem usando diferentes métodos. O ajuste instrucional emergiu como uma técnica fundamental, permitindo que os LLMs traduzam e apliquem instruções em linguagem humana em uma variedade de tarefas. Essa abordagem evoluiu da programação de instruções de domínio fechado, que usa conjuntos de dados disponíveis publicamente, para a programação de instruções de domínio aberto, que usa conjuntos de dados de resposta a consultas do mundo real para melhorar o desempenho do modelo em cenários de usuários autênticos.
Na integração da linguagem visual, abordagens como o LLaVA desenvolveram uma combinação de LLMs com embeddings visuais CLIP, que mostram capacidades notáveis em tarefas de diálogo visual e textual. A pesquisa subsequente concentrou-se no refinamento do conjunto de instruções visuais, melhorando a qualidade e a variabilidade do conjunto de dados durante as fases de pré-treinamento e ajuste fino. Modelos como LLaVA-v1.5 e ShareGPT4V alcançaram sucesso significativo na compreensão geral da linguagem de visão, demonstrando sua capacidade de lidar com tarefas complexas de resposta a consultas.
Este desenvolvimento destaca a importância de técnicas sofisticadas de gerenciamento e modelagem de dados no desenvolvimento de modelos de linguagem visual eficazes. No entanto, permanecem desafios para colmatar a lacuna do processo entre a teoria e o domínio linguístico, o que exige inovação contínua na concepção de modelos e nos métodos de formação.
Pesquisadores do Rochester Institute of Technology e da Salesforce AI Research propõem uma estrutura única, SQ-LLaVA baseado em um método de questionamento visualusado em um modelo denominado SQ-LLaVA (Self-Questioning LLaVA). Este método visa melhorar a compreensão da linguagem visual, treinando o LLM para fazer perguntas e encontrar pistas visuais sem a necessidade de dados externos adicionais. Ao contrário dos métodos existentes de planejamento de instruções visuais que se concentram mais na previsão de respostas, o SQ-LLaVA extrai o contexto de questões relevantes das imagens.
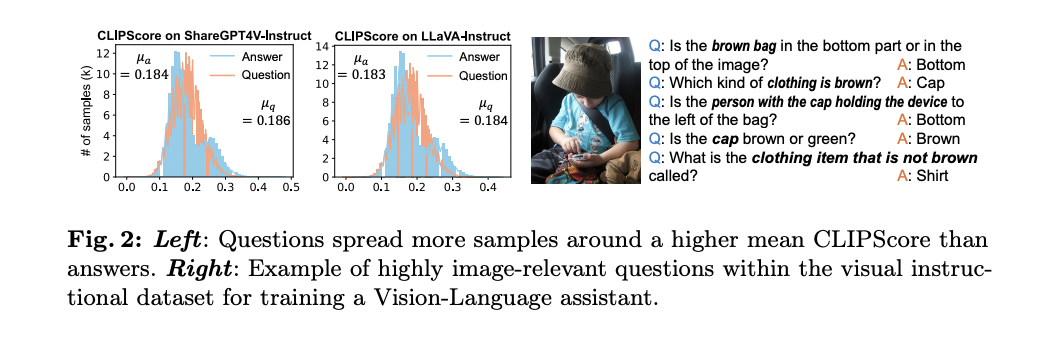
Esta abordagem é baseada na observação de que as perguntas geralmente contêm mais informações relacionadas à imagem do que respostas, conforme evidenciado pelos CLIPcores mais elevados de pares de perguntas de imagem em comparação com pares de respostas de imagem em conjuntos de dados existentes. Usando esse entendimento, o SQ-LLaVA utiliza consultas nos dados instrucionais como um recurso adicional de aprendizagem, aumentando efetivamente a curiosidade e a capacidade de questionamento do modelo.
A fim de combinar com sucesso os domínios perceptivo e linguístico, o SQ-LLaVA usa argumentos de baixo nível (LoRAs) para melhorar tanto o codificador perceptivo quanto a instrução LLM. Além disso, um extrator de protótipo é desenvolvido para melhorar a representação visual usando clusters aprendidos com informações semânticas significativas. Esta abordagem abrangente visa melhorar a compreensão da linguagem visual e o desempenho geral em diversas tarefas de compreensão visual sem a necessidade de nova coleta de dados ou extensos recursos computacionais.
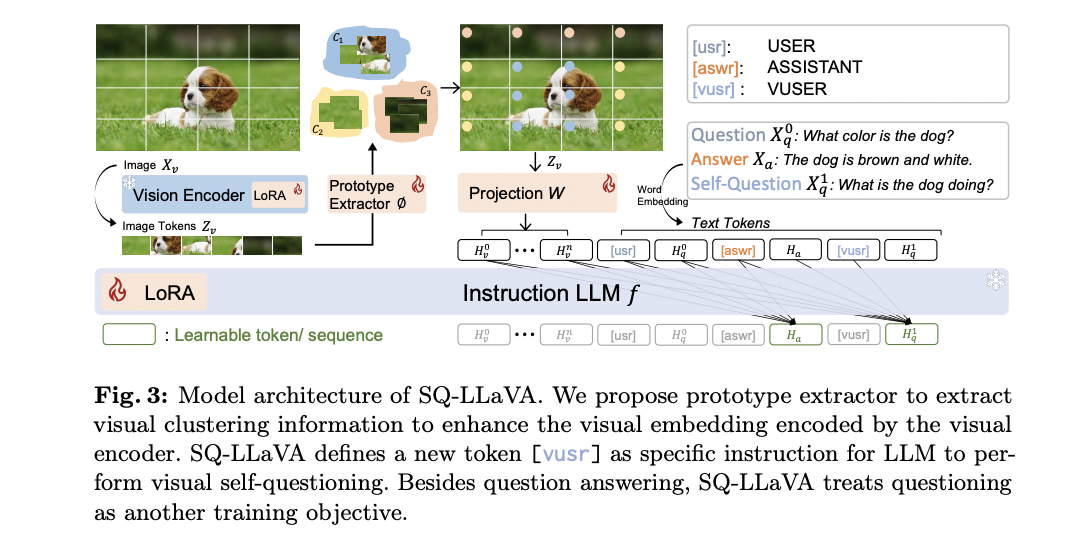
A estrutura do modelo SQ-LLaVA inclui quatro componentes principais concebidos para melhorar a compreensão da linguagem visual. Em sua essência está o codificador de visão pré-treinado CLIP-ViT que extrai incorporações sequenciais de imagens de entrada. Isto é complementado por um extrator de protótipo robusto que aprende clusters visuais para enriquecer os tokens de imagem originais, melhorando a capacidade do modelo de reconhecer e agrupar padrões visuais semelhantes.
Um bloco de predição treinável, composto por duas camadas sequenciais, mapeia os tokens de imagem aprimorados para o domínio da linguagem, abordando a incompatibilidade de dimensionalidade entre a representação visual e linguística. O núcleo do modelo é o Vicuna LLM pré-treinado, que prevê os próximos tokens com base nas incorporações sucessivas anteriores.
O modelo apresenta um método de investigação visual, utilizando variáveis [vusr] um sinal de ensino do LLM para gerar questões sobre a imagem. Esta técnica foi projetada para aproveitar a rica informação semântica frequentemente presente nas perguntas, que pode exceder a das respostas. A estrutura também inclui um componente avançado de representação visual com um extrator de protótipo que utiliza técnicas de clustering para capturar semântica representacional em um ambiente oculto. Este gerador atualiza iterativamente as funções e centros do cluster, mapeando dinamicamente as informações visuais do cluster para incorporações de imagens brutas.
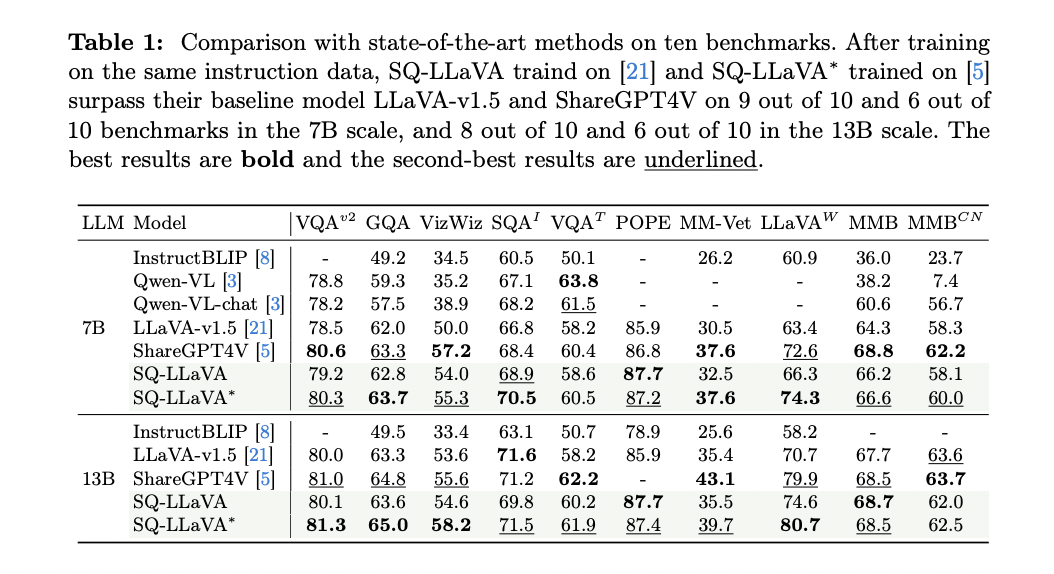
Os pesquisadores testaram o SQ-LLaVA em um conjunto abrangente de dez benchmarks visuais de resposta a perguntas, cobrindo uma ampla gama de tarefas, desde VQA acadêmico até tarefas de ajuste instrucional projetadas para modelos de linguagem visual em grande escala. O modelo mostrou melhorias significativas em relação aos métodos existentes em diversas áreas principais:
1. Desempenho: O SQ-LLaVA-7B e o SQ-LLaVA-13B superaram seus antecessores em seis entre dez tarefas de ajuste de instruções visuais. Notavelmente, o SQ-LLaVA-7B alcançou uma melhoria de 17,2% em relação ao LLaVA-v1.5-7B no benchmark LLaVA (selvagem), mostrando capacidades superiores em descrição detalhada e raciocínio complexo.
2. Raciocínio científico: O modelo apresentou melhor desempenho no ScienceQA, sugerindo fortes habilidades em raciocínio multi-hop e compreensão de conceitos científicos complexos.
3. Confiabilidade: SQ-LLaVA-7B apresentou melhoria de 2% e 1% em relação a LLaVA-v1.5-7B e ShareGPT4V-7B no benchmark POPE, mostrando melhor confiabilidade e redução de alucinações.
4. Robustez: SQ-LLaVA-13B superou trabalhos anteriores em seis dos dez benchmarks, demonstrando a eficácia do método com grandes modelos de linguagem.
5. Aquisição de informações visuais: O modelo mostrou habilidades avançadas em descrição detalhada de imagens, resumo de informações visuais e questionamento visual. Ele gerou questões diversas e lógicas sobre as imagens fornecidas, sem a necessidade de instruções escritas por humanos.
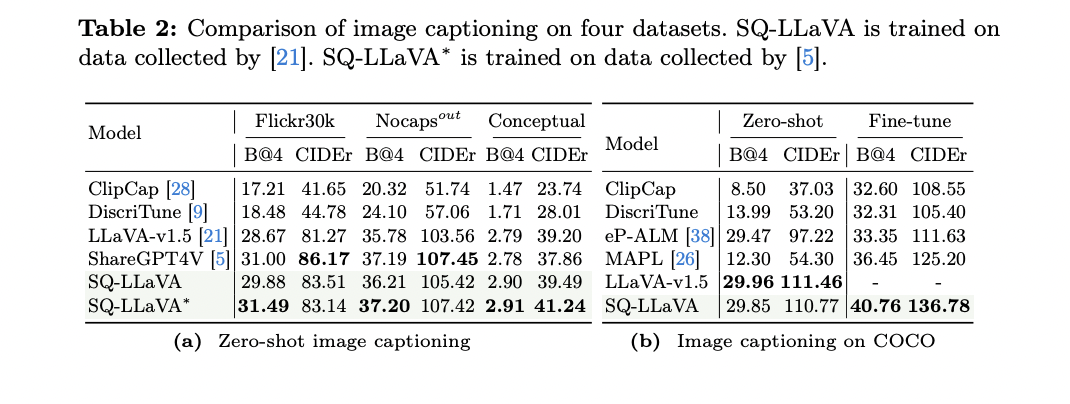
6. Legendagem descritiva de imagens: SQ-LLaVA obteve melhorias significativas em relação aos modelos de linha de base, como ClipCap e DiscriTune, com uma melhoria média de 73% e 66% para todos os conjuntos de dados.
Esses resultados foram alcançados com poucos parâmetros de treinamento em comparação com outros métodos, destacando a eficiência do método SQ-LLaVA. A capacidade do modelo de gerar diversas questões e fornecer descrições detalhadas de imagens demonstra seu potencial como uma ferramenta poderosa para aquisição e compreensão de informações visuais.


SQ-LLaVA apresenta uma abordagem única para o planejamento de instrução visual que melhora a compreensão da linguagem visual por meio do autoquestionamento. O método atinge alto desempenho com menos parâmetros e menos dados em vários benchmarks. Mostra melhor generalização para tarefas abstratas, reduz alucinações e melhora a interpretação semântica da imagem. Ao incorporar perguntas como princípio fundamental, o SQ-LLaVA avalia a curiosidade e as habilidades de questionamento do modelo. Esta pesquisa destaca o poder da investigação visual como uma técnica de treinamento poderosa, abrindo caminho para modelos de linguagem visual de grande escala e alto desempenho que podem resolver problemas complexos em uma variedade de domínios.
Confira Papel de novo GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – Conferência de recuperação de dados GenAI (promovida)
Asjad é consultor estagiário na Marktechpost. Ele está cursando B.Tech em engenharia mecânica no Instituto Indiano de Tecnologia, Kharagpur. Asjad é um entusiasta do aprendizado de máquina e do aprendizado profundo que pesquisa regularmente a aplicação do aprendizado de máquina na área da saúde.


