
Visão computacional muda devido ao desenvolvimento de modelos básicos em reconhecimento de objetos, classificação de imagens e estimativa de profundidade monocular, que mostra um forte desempenho de zero e poucos em todas as diferentes tarefas do rio. Correspondência estéreoque ajuda a perceber a profundidade e a criar visualizações 3D de cenas, importantes em áreas como robótica, carros autônomos e realidade aumentada. Porém, a avaliação de modelos básicos em correspondência estéreo permanece limitada devido à dificuldade de obtenção de contrastes precisos. verdade fundamental (GT) dados. Existem muitos conjuntos de dados estéreo, mas é difícil usá-los de maneira eficaz no treinamento. Além disso, esses conjuntos de dados anotados não podem treinar um bom modelo de linha de base, mesmo quando agregados.
Atualmente, Estéreo de mono está liderando pesquisas focadas na criação de pares de imagens estéreo e mapas de contraste diretamente de uma única imagem para enfrentar esses desafios. No entanto, este método só teve sucesso 500.000 amostras de dadosé baixo em comparação com a média necessária para treinar modelos básicos robustos com sucesso. Embora este esforço represente um passo importante para reduzir a dependência da dispendiosa coleta de dados estéreo, o conjunto de dados gerado não é suficiente para construir modelos em larga escala que possam se adaptar bem a diferentes situações do mundo real. Os primeiros métodos de correspondência estéreo dependiam fortemente de recursos feitos à mão, mas foram mudados para CNN-os modelos suportados são semelhantes GCNet de novo PSMNetmelhorar a precisão com técnicas semelhantes 3D consolidação de custos. A correspondência estéreo de vídeo usa dados temporais para correspondência, mas tem dificuldade com a generalização. As abordagens entre domínios abordam isso aprendendo características invariantes do domínio usando técnicas como adaptação não supervisionada e aprendizagem cruzada, como visto em modelos como A JANGADA–Estéreo de novo AntigoStereo.
Um grupo de pesquisadores da Escola de Ciência da Computação, Universidade de Wuhan, Instituto de Inteligência Artificial e Robótica, Universidade Xi'an Jiaotong, Waytous, Universidade de Bolonha, Rock Universe, Instituto de Automação, Academia Chinesa de Ciências e Universidade da Califórnia, Berkeley . Um estudo detalhado para superar essas questões também é proposto EstéreoQualquer coisaum modelo básico de correspondência estéreo desenvolvido para produzir medições de contraste de alta qualidade para qualquer imagem de correspondência estéreo, não importa quão complexo seja o campo ou quão desafiadoras sejam as condições ambientais. Ele foi projetado para treinar uma rede estéreo robusta usando grandes dados mistos. Consiste principalmente em quatro partes: extração de recursos, estrutura de custos, integração de custos e redução de variação.
Para melhorar a normalização, foram utilizados dados estéreo supervisionados sem normalização de profundidade, uma vez que a correspondência estéreo depende de informações de escala. O treinamento começou com um único conjunto de dados e conjuntos de dados de alto nível foram combinados para melhorar a robustez. Para leitura de imagem única, os modelos de profundidade monocular previram a profundidade que foi convertida em mapas de disparidade para produzir pares estéreo realistas por colapso direto. Lacunas e lacunas foram preenchidas usando texturas de outras imagens do conjunto de dados.

O teste mostrou um teste de EstéreoTanto faz estrutura usando OpenStereo de novo NMRF-Estéreoo básico com Transformador Swin para remover o recurso. Treinamento aplicado AdamW otimizador, OneCycleLR edição e ajuste fino em conjuntos de dados rotulados, mistos e pseudo-rotulados com aumento de dados. O teste está aberto GATINHOMiddlebury, ETH3Dde novo Condução estéreo mostrou erros de StereoAnything significativamente reduzidos, NMRF-Stereo-SwinT reduziu o erro médio de 18.11 a 5.01. O ajuste fino do StereoCarla em vários conjuntos de dados leva à melhor métrica de descrição 8,52%. Isso mostrou a importância da diversidade do conjunto de dados quando se trata de desempenho de correspondência estéreo.
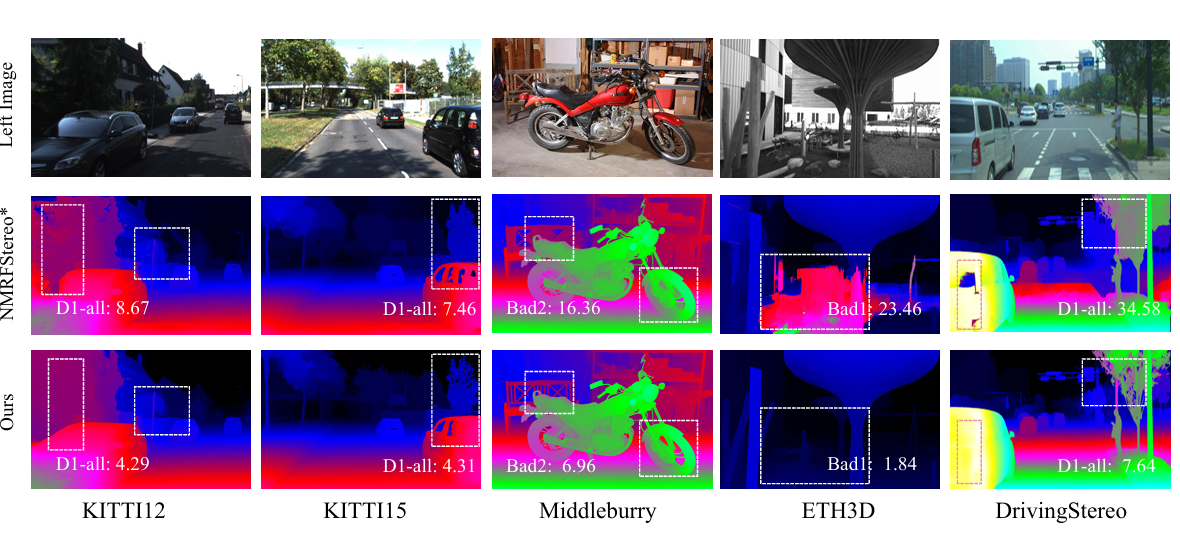
Em termos de resultados, o StereoAnything mostrou estabilidade sólida em uma variedade de ambientes, tanto em cenas internas quanto externas. Este método forneceu consistentemente um mapa de contraste mais preciso que o NMRF-Stereo-SwinTmode. Portanto, este método apresenta forte produtividade e tem melhor desempenho em todos os domínios com muitas diferenças físicas e ambientais.
É seguro concluir que o StereoAnything forneceu uma solução muito útil para emparelhamento estéreo sólido. Um novo conjunto de dados sintéticos é chamado EstéreoCarla é usado para generalizar melhor em todas as situações diferentes e melhorar o desempenho. Além disso, o desempenho de conjuntos de dados estéreo rotulados e conjuntos de dados pseudo-estéreo gerados usando modelos de estimativa de profundidade monocular foi investigado. Em relação ao desempenho, EstéreoTanto faz alcançou desempenho competitivo em vários benchmarks e condições do mundo real. Estes resultados demonstram o poder das técnicas de treinamento híbrido, combinando diversas fontes de dados para melhorar a robustez do modelo estéreo, e podem ser usados como base para desenvolvimento e pesquisas futuras!
Confira Papel e GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
🎙️ 🚨 'Avaliação de vulnerabilidade de um grande modelo de linguagem: uma análise comparativa dos métodos da Cruz Vermelha' Leia o relatório completo (Promovido)
Divyesh é estagiário de consultoria na Marktechpost. Ele está cursando BTech em Engenharia Agrícola e Alimentar pelo Instituto Indiano de Tecnologia, Kharagpur. Ele é um entusiasta de Ciência de Dados e Aprendizado de Máquina que deseja integrar essas tecnologias avançadas no domínio agrícola e resolver desafios.
🧵🧵 [Download] Avaliação do relatório do modelo de risco linguístico principal (ampliado)


