
O rápido escalonamento dos modelos de distribuição levou a desafios de uso de memória e latência, dificultando sua implantação, especialmente em ambientes com uso intensivo de recursos. Tais modelos têm demonstrado notável capacidade de fornecer imagens de alta fidelidade, mas são exigentes tanto em memória quanto em computação, o que impede sua disponibilidade em dispositivos e aplicativos de consumo que exigem baixa latência. Portanto, estes desafios precisam ser enfrentados para tornar possível treinar grandes modelos de distribuição em múltiplas plataformas em tempo real.
As técnicas atuais para resolver os problemas de memória e velocidade dos modelos de distribuição incluem estimativa pós-treinamento e treinamento de habilidades de estimativa, principalmente com métodos de estimativa apenas de peso, como NormalFloat4 (NF4). Embora esses métodos funcionem bem para modelos linguísticos, eles falham em modelos distributivos devido à alta exigência computacional. Ao contrário dos modelos de linguagem, os modelos de distribuição exigem redução simultânea de pesos e ativações para evitar a degradação do desempenho. Os métodos de medição existentes sofrem com a presença de valores discrepantes tanto nos pesos quanto na ativação com precisão de 4 bits e contribuem para o comprometimento da qualidade visual e ineficiências computacionais, tornando a solução mais robusta.
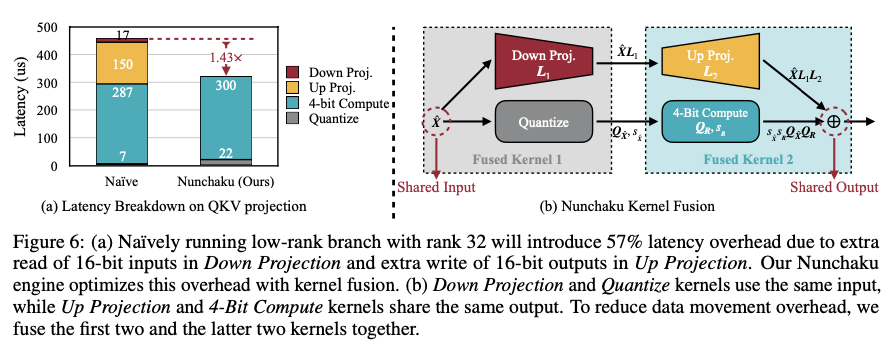
Pesquisadores do MIT, NVIDIA, CMU, Princeton, UC Berkeley, SJTU e Pika Labs propuseram o SVDQuant. Este paradigma de quantização introduz uma ramificação de baixo nível para absorver valores discrepantes, permitindo uma quantização eficiente de 4 bits em modelos de distribuição. Usando SVD criativo para lidar com valores discrepantes, o SVDQuant irá transferi-los da configuração para o peso e sugá-los para uma ramificação de baixo nível que permite que o restante seja dimensionado para 4 bits sem perda de desempenho e evita um erro comum relacionado a valores discrepantes. melhoria contínua do processo de medição sem repetição excessiva. Os cientistas desenvolveram um mecanismo de benchmarking chamado Nunchaku que combina caracteres de computação de baixo e baixo custo e otimização de acesso à memória para reduzir a latência.
SVDQuant funciona perfeitamente e envia valores discrepantes de ativações para pesos. Em seguida, aplique a decomposição SVD sobre os pesos, divida os pesos em mínimo e residual. A parte de baixo nível absorverá a saída com precisão de 16 bits, enquanto o restante será medido com precisão de 4 bits. O mecanismo de inferência Nunchaku melhora ainda mais isso, permitindo ramificações de baixo nível e ramificações de baixo nível juntas, combinando assim dependências de entrada e saída, resultando em acesso reduzido à memória e, subsequentemente, latência reduzida. Impressionantemente, a análise de modelos como FLUX.1 e SDXL, usando conjuntos de dados como MJHQ e sDCI, revela uma enorme economia de memória de 3,5x e economia de latência de até 10,1x em dispositivos móveis. Por exemplo, o uso de SVDQuant reduz o parâmetro FLUX.1 bilhão 12 de 22,7 GB para 6,5 GB, evitando a carga da CPU em configurações com atraso de memória.
O SVDQuant superou os métodos de medição de última geração em termos de eficiência e confiabilidade visual. Com uma medição de 4 bits, o SVDQuant sempre mostra grande consistência de compreensão com números de alta qualidade que podem ser salvos para qualquer tarefa de produção de imagem, superando consistentemente concorrentes, como NF4, em termos de pontuações Fréchet Inception Distance, ImageReward, LPIPS e PSNR. . para todos os modelos que criam vários modelos de distribuição e, por exemplo, em comparação com o modelo FLUX.1-dev, a otimização SVDQuant é ajustada para pontuações LPIPS alinhadas perto da base de 16 bits, economizando 3,5× no tamanho do modelo e atingindo aproximadamente 3,5× no tamanho do modelo. . Aceleração de 10,1 × em dispositivos GPU sem carga de CPU. Essa funcionalidade suporta a produção em tempo real de imagens de alta qualidade em dispositivos com memória limitada, enfatizando a implantação eficiente e eficaz de modelos de grande distribuição.

Concluindo, o método SVDQuant proposto usa uma aproximação aprimorada de 4 bits; aqui, os problemas externos encontrados no modelo de distribuição são tratados mantendo a qualidade das imagens, com redução significativa de memória e latência. Melhorar a padronização e eliminar a movimentação redundante de dados com o mecanismo de raciocínio do Nunchaku constitui a base para a implantação bem-sucedida de modelos de distribuição em larga escala e, assim, avança seu uso potencial em aplicações interativas do mundo real em plataformas de computação de consumo.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[AI Magazine/Report] Leia nosso último relatório sobre 'MODELOS DE TERRENO PEQUENOS'
Aswin AK é consultor da MarkTechPost. Ele está cursando seu diploma duplo no Instituto Indiano de Tecnologia, Kharagpur. Ele é apaixonado por ciência de dados e aprendizado de máquina, o que traz consigo uma sólida formação acadêmica e experiência prática na solução de desafios de domínio da vida real.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️
 da Meta")

