
Modelos linguísticos de larga escala (LLMs) evoluíram para se tornarem ferramentas poderosas, capazes de compreender e responder às instruções do usuário. Baseados na arquitetura do transformador, esses modelos prevêem a próxima palavra ou token em uma frase, gerando respostas com notável fluência. No entanto, muitas vezes respondem sem se envolverem em processos de pensamento internos que podem ajudar a melhorar a precisão das suas respostas, especialmente em tarefas complexas. Embora métodos como a estimulação da Cadeia de Pensamento (CoT) sejam projetados para melhorar o pensamento, esses métodos exigem mais sucesso fora das tarefas lógicas e matemáticas. Os pesquisadores estão agora se concentrando em equipar os LLMs para pensar antes de responder, melhorando seu desempenho em uma ampla gama de tarefas, incluindo redação criativa e questões de conhecimentos gerais.
Um dos maiores desafios dos LLMs é a tendência de responder sem considerar a complexidade das instruções. Para tarefas simples, respostas rápidas podem ser suficientes, mas esses modelos muitas vezes ficam aquém de problemas complexos que exigem pensamento lógico ou resolução de problemas. A dificuldade está em treinar os modelos para fazer uma pausa, gerar pensamentos internos e avaliar esses pensamentos antes de entregar uma resposta final. Este tipo de treinamento tradicionalmente consome muitos recursos e requer grandes conjuntos de dados de pensamentos anotados por humanos, que estão disponíveis apenas em alguns domínios. Como resultado, o problema que os investigadores enfrentam é como construir LLMs altamente inteligentes que possam aplicar o raciocínio a uma variedade de tarefas sem depender de dados rotulados por humanos.
Muitos métodos foram desenvolvidos para lidar com esse problema e permitir que os LLMs isolem problemas complexos. A informação da cadeia de pensamento (CoT) é um método em que o modelo é solicitado a listar etapas intermediárias do pensamento, permitindo-lhe lidar com tarefas mais estruturadas. No entanto, os métodos CoT têm tido sucesso principalmente em áreas como a matemática e a lógica, onde são necessários passos claros de raciocínio. Em domínios como o marketing ou a escrita criativa, onde as respostas são altamente consistentes, o CoT muitas vezes não consegue proporcionar melhorias significativas. Esta limitação é agravada pelo facto de os conjuntos de dados utilizados para treinar LLMs conterem frequentemente respostas humanas em vez dos processos de pensamento internos por detrás dessas respostas, tornando difícil refinar as capacidades de raciocínio do modelo em diferentes áreas.
Pesquisadores da Meta FAIR, da Universidade da Califórnia, Berkeley e da Universidade de Nova York introduziram um novo método de treinamento chamado Desenvolvendo uma preferência de pensamento (TPO). O TPO visa equipar os LLMs existentes com a capacidade de gerar e refinar pensamentos internos antes de gerar feedback. Ao contrário dos métodos tradicionais que dependem de dados rotulados por humanos, o TPO não requer anotações humanas adicionais, o que o torna uma solução econômica. O método TPO começa instruindo o modelo a dividir a saída em duas partes distintas: processo de pensamento de novo resposta final. Vários pensamentos são gerados para cada comando do usuário, e esses pares de pensamento-resposta são avaliados através da criação de preferências. Os melhores pares pensamento-resposta são selecionados para treinamento adicional, permitindo gradualmente que o modelo melhore sua capacidade de raciocínio.
No centro do TPO está um método de aprendizagem por reforço (RL) que permite ao modelo aprender com sua geração de lógica. O modelo é solicitado a gerar pensamentos antes de responder e o modelo julga as respostas resultantes. Ao repetir esse processo e ajustar os pensamentos que levam a respostas de alta qualidade, o modelo melhora na compreensão de questões complexas e na entrega de respostas bem pensadas. Esta abordagem iterativa é importante porque permite que o modelo ajuste as suas suposições sem exigir intervenção humana direta, tornando-o uma solução escalável para o desenvolvimento de LLMs numa variedade de domínios.
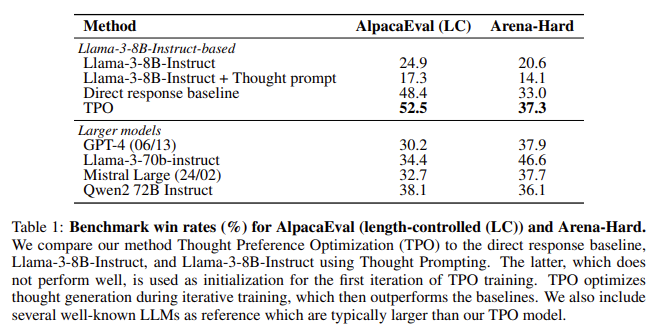
O desempenho do TPO foi testado em dois benchmarks proeminentes: AlpacaEval e Arena-Hard. No AlpacaEval, o modelo TPO alcançou uma taxa de vitória de 52,5%, superando a base de resposta direta em 4,1%. Da mesma forma, registou uma taxa de vitórias de 37,3% no Arena-Hard, superando os métodos tradicionais em 4,3%. Estas melhorias significativas mostram que o TPO é eficaz em tarefas baseadas em lógica e em áreas normalmente não associadas à lógica, como marketing e questões relacionadas com a saúde. Os pesquisadores observaram que os LLMs equipados com TPO mostraram benefícios mesmo em tarefas de escrita criativa e de conhecimentos gerais, indicando a ampla aplicabilidade do método.
Uma das descobertas mais importantes do estudo foi que os modelos baseados no raciocínio tiveram melhor desempenho do que os modelos de resposta direta em vários domínios. Mesmo em tarefas que não envolvem pensamento, como a escrita criativa, os modelos habilitados para TPO podem organizar suas respostas de forma mais eficaz, levando a melhores resultados. A natureza iterativa do treinamento TPO também significa que o modelo continua a melhorar a cada iteração, como pode ser visto no aumento das taxas de vitória em vários benchmarks. Por exemplo, após quatro iterações de treinamento TPO, o modelo alcançou uma taxa de vitória de 52,5% no AlpacaEval, o que representa um aumento de 27,6% em relação ao modelo inicial original. O benchmark Arena-Hard viu tendências semelhantes, com o modelo correspondendo e finalmente ultrapassando a linha de base exata após várias iterações.
Principais conclusões do estudo:
- A TPO aumentou a taxa de vitórias de LLMs em 52,5% no AlpacaEval e 37,3% no Arena-Hard.
- Essa abordagem elimina a necessidade de dados rotulados por humanos, tornando-os econômicos e escaláveis.
- A TPO desenvolveu atividades não pensantes, como marketing, redação criativa e consultas relacionadas à saúde.
- Após quatro iterações, os modelos TPO alcançaram uma melhoria de 27,6% em relação ao modelo de sementes original no AlpacaEval.
- A metodologia tem ampla aplicabilidade, estendendo-se além das tarefas cognitivas tradicionais até à educação regular subsequente.

Concluindo, a Otimização de Preferência de Pensamento (TPO) permite que os modelos pensem antes de responder. O TPO aborda as principais limitações dos LLMs tradicionais: sua incapacidade de lidar com tarefas complexas que exigem pensamento lógico ou resolução de problemas em várias etapas. A pesquisa mostra que o TPO pode melhorar o desempenho em uma ampla variedade de tarefas, desde problemas baseados em lógica até questões criativas e independentes. A natureza repetitiva e de autodesenvolvimento do TPO torna-o um caminho promissor para o desenvolvimento futuro em LLMs, proporcionando amplas aplicações em campos além das tarefas cognitivas tradicionais.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] Melhor plataforma para modelos ajustados: mecanismo de inferência Predibase (avançado)
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre o público.


: uma série 1B, 3B e 40B de modelos de IA generativos")
