
Os Transformers revolucionaram a inteligência artificial, oferecendo desempenho incomparável em PNL, visão computacional e integração de dados multimodais. Esses modelos são excelentes na identificação de padrões nos dados usando seus mecanismos de atenção, tornando-os ideais para tarefas complexas. No entanto, o rápido escalonamento dos modelos de transformadores precisa ser melhorado devido aos elevados custos computacionais associados à sua estrutura tradicional. À medida que esses modelos crescem, eles exigem recursos de hardware e tempo de treinamento significativos, que aumentam exponencialmente com o tamanho dos modelos. Os pesquisadores pretendem resolver essas limitações desenvolvendo maneiras mais eficientes de gerenciar e dimensionar modelos de transformadores sem sacrificar o desempenho.
O principal obstáculo na medição de transformadores reside nos parâmetros constantes dentro de suas camadas de projeção linear. Essa estrutura estática limita a capacidade de escalabilidade do modelo sem um retreinamento completo, o que é caro à medida que os modelos escalam. Esses modelos tradicionais geralmente exigem um retreinamento completo quando ocorrem mudanças estruturais, como o aumento do tamanho do canal. Portanto, o custo computacional destas extensões aumenta exponencialmente e o método carece de flexibilidade. A incapacidade de adicionar novos parâmetros dificulta o crescimento, tornando estes modelos menos adaptáveis às condições mutáveis das aplicações de IA e mais caros em termos de tempo e recursos.
Historicamente, as abordagens para controlar o dimensionamento do modelo incluíam pesos iterativos ou reprogramação de modelos usando métodos como Net2Net, onde neurônios iterativos abrangem camadas. No entanto, estes métodos tendem a perturbar o equilíbrio dos modelos pré-treinados, resultando em taxas de convergência mais baixas e em maior dificuldade de treinamento. Embora esses métodos tenham feito progressos incrementais, eles ainda enfrentam limitações na manutenção da integridade do modelo durante o dimensionamento. Os transformadores dependem fortemente da suposição de linearidade, o que torna a expansão de parâmetros cara e inconveniente. Modelos tradicionais, como GPT e outros grandes transformadores, muitas vezes se reciclam do zero, incorrendo em altos custos computacionais para cada nova fase de escalonamento.
Pesquisadores do Instituto Max Planck, do Google e da Universidade de Pequim criaram uma nova estrutura chamada formador de token. Este modelo basicamente reimagina os transformadores tratando os parâmetros do modelo como tokens, permitindo interações dinâmicas entre tokens e parâmetros. Nesta estrutura, o Tokenformer introduz um novo componente chamado token-parã atenção (Direitos autorais) camada, o que ajuda a aumentar a escala. O modelo pode adicionar novos tokens de parâmetro sem retreinamento, reduzindo bastante o custo de treinamento. Ao representar tokens e parâmetros de entrada dentro de uma estrutura comum, o Tokenformer permite o escalonamento dinâmico, fornecendo aos pesquisadores uma maneira de construir modelos altamente eficientes e conscientes de recursos que mantêm robustez e alto desempenho.
A camada Pattention do Tokenformer usa tokens de entrada como consultas, enquanto os parâmetros do modelo atuam como chaves e valores, o que é diferente do método de conversão padrão, que depende apenas de suposições diretas. O escalonamento do modelo é obtido adicionando novos valores de parâmetro ao valor-chave, mantendo as dimensões de entrada e saída constantes e evitando o retreinamento completo. A arquitetura do Tokenformer foi projetada para ser modular, permitindo que os pesquisadores estendam o modelo de maneira transparente, integrando tokens adicionais. Esse recurso de escalonamento incremental oferece suporte à reutilização eficiente de pesos pré-treinados, ao mesmo tempo que permite a rápida adaptação a novos conjuntos de dados ou tamanhos de modelos maiores, sem comprometer as informações aprendidas.
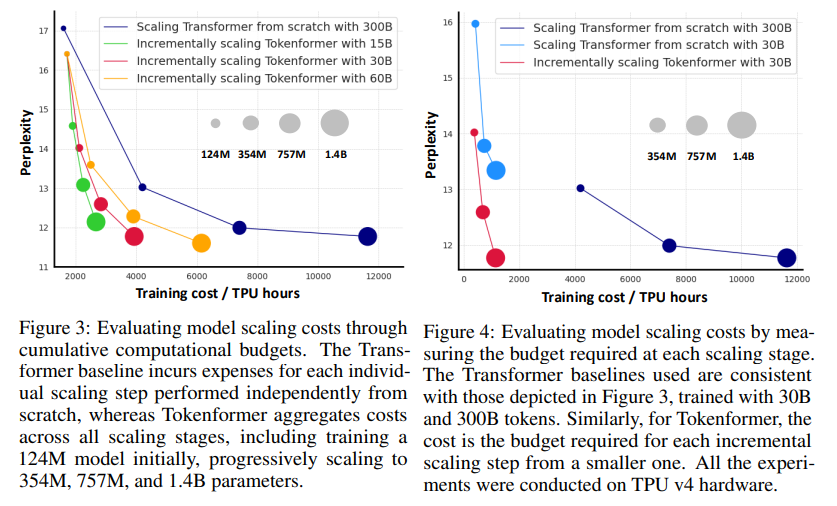
Os benefícios de desempenho do Tokenformer são significativos, pois o modelo reduz significativamente os custos computacionais, mantendo a precisão. Por exemplo, o Tokenformer vai de 124 milhões para 1,4 bilhão de parâmetros com apenas uma fração dos custos típicos de treinamento exigidos pelos conversores tradicionais. Em outro teste, o modelo obteve um erro de teste de 11,77 para uma configuração de parâmetros de 1,4 bilhão, que é quase o mesmo que um erro de 11,63 para um transformador do mesmo tamanho treinado do zero. Essa eficiência significa que o Tokenformer pode alcançar alto desempenho em vários domínios, incluindo operações de linguagem e modelagem física, por uma fração do custo de recursos dos modelos convencionais.
Tokenformer apresenta muitas conclusões importantes para o desenvolvimento de pesquisas em IA e modelos baseados em transformadores. Isso inclui:
- Grande economia de custos: As arquiteturas Tokenformer reduziram os custos de treinamento em mais de 50% em comparação aos transformadores convencionais. Por exemplo, a escala de parâmetros de 124M para 1,4B requer uma fração do orçamento dos transformadores inicialmente treinados.
- Ampliando para alto desempenho: O modelo oferece suporte ao escalonamento incremental adicionando novos tokens de parâmetros sem modificar a arquitetura central, permitindo flexibilidade e redução das demandas de retreinamento.
- Preservação da informação aprendida: O tokenformer armazena informações de modelos pequenos e pré-treinados, acelerando a convergência e evitando a perda de informações aprendidas durante o dimensionamento.
- Desempenho multitarefa aprimorado: Nos benchmarks, o Tokenformer alcançou níveis de precisão competitivos em todas as tarefas de linguagem e modelagem virtual, demonstrando sua força como modelo base dinâmico.
- Taxas fixas de transação de token: Ao combinar custos de transação com tokens de escalonamento, o Tokenformer pode gerenciar com eficiência sequências longas e modelos grandes.

Concluindo, o Tokenformer oferece uma maneira flexível de dimensionar modelos baseados em transformadores. Este modelo arquitetônico alcança medição e eficiência de recursos gerenciando parâmetros como tokens, reduzindo custos e mantendo o desempenho do modelo em todas as operações. Esta flexibilidade representa um avanço no design de transformadores, fornecendo um modelo que pode se adaptar às necessidades de desenvolvimento de aplicações de IA sem necessidade de reciclagem. A arquitetura do Tokenformer é uma promessa para pesquisas futuras em IA, fornecendo uma maneira de desenvolver modelos em grande escala de forma contínua e eficiente.
Confira Papel, Página GitHubde novo Modelos no HuggingFace. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[Sponsorship Opportunity with us] Promova sua pesquisa/produto/webinar para mais de 1 milhão de leitores mensais e mais de 500 mil membros da comunidade
Sana Hassan, estagiária de consultoria na Marktechpost e estudante de pós-graduação dupla no IIT Madras, é apaixonada pelo uso de tecnologia e IA para enfrentar desafios do mundo real. Com um profundo interesse em resolver problemas do mundo real, ele traz uma nova perspectiva para a intersecção entre IA e soluções da vida real.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


