
PyTorch é lançado oficialmente um tornadouma biblioteca abrangente projetada para otimizar modelos PyTorch para melhor desempenho e eficiência. A introdução desta biblioteca é um marco no desenvolvimento da modelagem de aprendizagem profunda, fornecendo aos usuários um kit de ferramentas acessível que implementa técnicas avançadas como bitmaps, quantização e dispersão. A biblioteca é amplamente escrita em código PyTorch, o que garante facilidade de uso e integração para desenvolvedores que trabalham com cargas de trabalho de compreensão e treinamento.
Características importantes do torchao
- Ele fornece suporte completo para vários modelos de produção de IA, como Llama 3 e modelos de distribuição, garantindo compatibilidade e facilidade de uso.
- Ele mostra ganhos de desempenho impressionantes, alcançando até 97% de aceleração e uma redução significativa no uso de memória durante a definição e treinamento do modelo.
- Ele fornece uma variedade de técnicas de medição, incluindo dtypes de baixo nível, como int4 e float8, para desenvolver modelos de inferência e treinamento.
- Ele suporta ativação dinâmica de quantização e dispersão para vários tipos, melhorando a flexibilidade do desempenho do modelo.
- Possui Quantization Aware Training (QAT) para reduzir a degradação da precisão que pode ocorrer com a quantização de baixo bit.
- Ele fornece um fluxo de trabalho de treinamento computacional e interativo fácil de usar e de baixa precisão, compatível com as camadas 'nn.Linear' do PyTorch.
- Apresenta suporte experimental para otimizadores de 8 e 4 bits, servindo como um substituto para AdamW para melhorar o treinamento do modelo.
- Ele se integra perfeitamente aos principais projetos de código aberto, como conversores e difusores HuggingFace, e serve como referência para modelos de aceleração.
Esses recursos principais estabelecem o torchao como uma biblioteca multitarefa de desenvolvimento de modelos de aprendizagem profunda.
Técnicas Matemáticas Avançadas
Uma das características marcantes do torchao é seu forte suporte à quantização. Os algoritmos de quantização de inferência funcionam em cima de modelos PyTorch arbitrários que consistem em camadas 'nn.Linear', que fornecem ativações variáveis apenas de peso para vários dtypes e estruturas esparsas. Os desenvolvedores podem escolher as técnicas de quantização mais adequadas usando a API de alto nível 'quantize_'. Esta API inclui opções para modelos vinculados à memória, como int4_weight_only e int8_weight_only, e modelos vinculados computacionalmente. Para modelos com restrições computacionais, torchao pode realizar quantização float8, proporcionando mais flexibilidade para modelagem de alto desempenho. Além disso, as técnicas de escala do torchao são muito flexíveis, permitindo uma combinação de pequeno e grande para melhorar o desempenho.
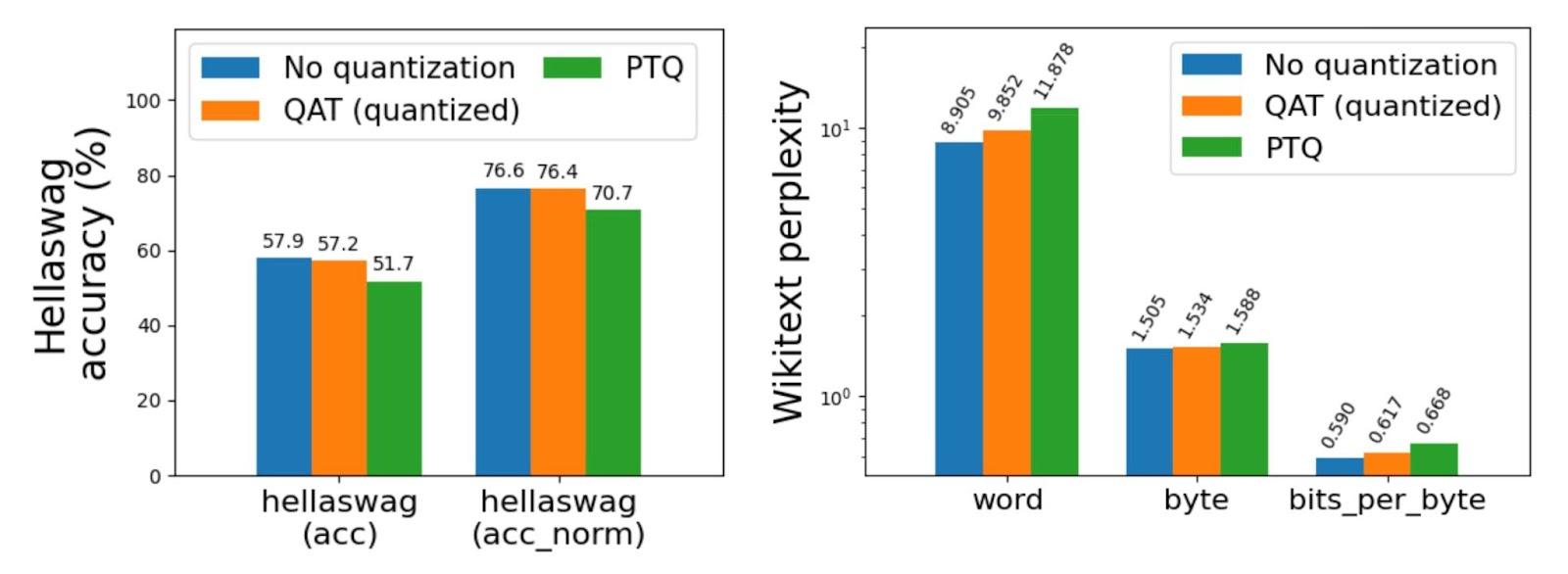
Treinamento consciente de quantização (QAT)
Torchao aborda a potencial degradação da precisão associada à quantização pós-treinamento, especialmente para modelos com valores inferiores a 4 bits. A biblioteca inclui suporte para Quantization Aware Training (QAT), que demonstrou recuperar até 96% da degradação da precisão em benchmarks desafiadores, como Hellaswag. Este recurso é compilado como uma receita ponta a ponta no torchtune, com um pequeno tutorial para simplificar seu uso. A inclusão do QAT torna o torchao uma ferramenta poderosa para treinar modelos com quantização de baixo bit, mantendo a precisão.
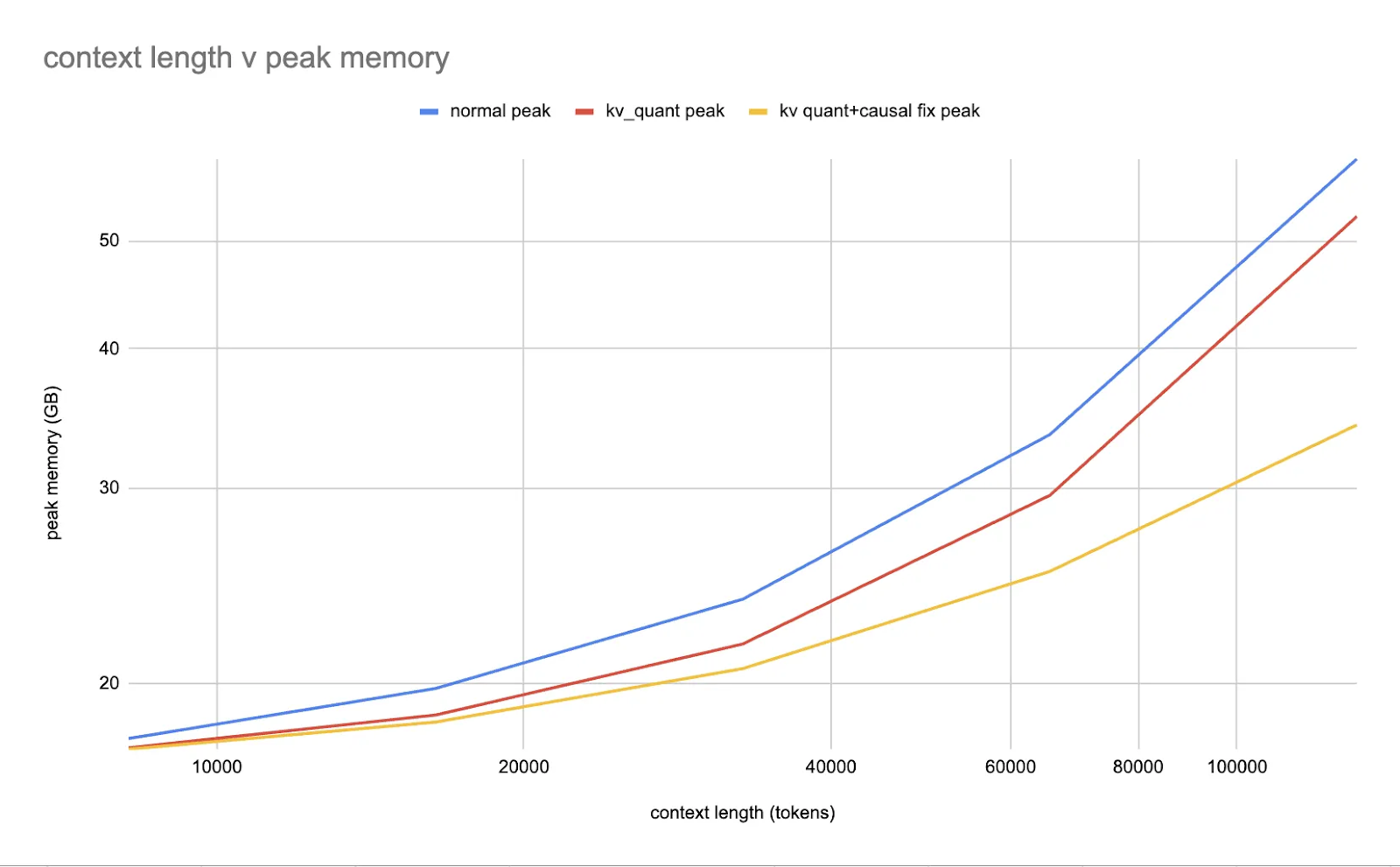
Melhorando o treinamento de baixa precisão
Além do desempenho ideal, o torchao oferece suporte completo para computação e comunicação de baixa precisão durante o treinamento. A biblioteca inclui um fluxo de trabalho fácil de usar para reduzir a precisão dos cálculos de treinamento e correlações distribuídas, começando com float8 para camadas `torch.nn.Linear`.
Torchao mostrou resultados impressionantes, como uma aceleração de 1,5x do pré-treinamento do Llama 3 70B ao usar float8. A biblioteca também fornece suporte de teste para outros aprimoramentos de treinamento, como NF4 QLoRA em torchtune, treinamento de protótipo int8 e treinamento acelerado 2:4. Esses recursos tornam o torchao uma opção atraente para usuários que buscam acelerar o treinamento e, ao mesmo tempo, minimizar o uso de memória.
Otimizadores de baixo bit
Inspirado no trabalho pioneiro de Bits e Bytes em otimizadores de baixo bit, torchao introduz suporte para otimizadores de 8 e 4 bits, por exemplo, como um substituto para o amplamente utilizado otimizador AdamW. Esse recurso permite que os usuários mudem perfeitamente para otimizadores de baixo bit, melhorando a eficiência do treinamento do modelo sem alterar significativamente a infraestrutura existente.
Integração e Desenvolvimento Futuro
Torchao está ativamente envolvido em alguns dos projetos de código aberto mais importantes da comunidade de aprendizado de máquina. Essa integração inclui funcionar como um back-end de inferência para transformadores HuggingFace, contribuindo com difusores-torchao para acelerar modelos de difusão e fornecendo receitas QLoRA e QAT para ajustar o torch. As técnicas de quantização de 4 e 8 bits do Torchao também são suportadas no projeto SGLang, tornando-o uma ferramenta valiosa para quem trabalha em aplicações de pesquisa e produção.
Seguindo em frente, a equipe PyTorch descreveu várias melhorias interessantes no torchao. Isso inclui ultrapassar os limites do dimensionamento abaixo de 4 bits, desenvolver caracteres ativos de toque de alto impacto, dimensionar para várias camadas, tipos de dimensionamento ou granularidades e oferecer suporte a back-ends de hardware adicionais, como hardware MX.
Principais conclusões para a iniciação de Torchao
- Principais benefícios de desempenho: Alcançada aceleração de até 97% nos cálculos do Llama 3 8B usando métodos avançados de benchmarking.
- Redução do uso de recursos: Foi mostrada uma redução máxima de 73% na VRAM no Llama 3.1 8B direto e uma redução de 50% na VRAM em modelos distribuídos.
- Vários suportes de quantização: Ele fornece uma ampla gama de opções de medição, incluindo float8 e int4, com suporte QAT para precisão.
- Otimizadores de baixo bit: Introduzimos otimizadores de 8 e 4 bits como substitutos do AdamW.
- Integração com os principais projetos de código aberto: Totalmente integrado em transformadores HuggingFace, difusores-torchao e outros projetos importantes.
Concluindo, a introdução do torchao representa um grande avanço para o PyTorch, fornecendo aos desenvolvedores um kit de ferramentas poderoso para tornar os modelos mais rápidos e eficientes em todos os cenários de treinamento e interpretação.
Confira Detalhes de novo GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.


