
O Processamento de Linguagem Natural (PNL) avançou muito com o aprendizado profundo, impulsionado por inovações como incorporação de palavras e estruturas transformadoras. A aprendizagem autodirigida utiliza grandes quantidades de dados não rotulados para criar tarefas de treinamento e se tornou o principal método para modelos de treinamento, especialmente em idiomas amplamente utilizados, como inglês e chinês. As diferenças nos recursos e no desempenho da PNL variam desde idiomas amplamente utilizados, como inglês e chinês, até idiomas com poucos recursos, como Portuguêse mais de 7.000 idiomas em todo o mundo. Tal lacuna dificulta a capacidade dos aplicativos de PNL para linguagens menos utilizadas crescerem e se tornarem mais poderosos e acessíveis. Além disso, os modelos que utilizam uma única linguagem de poucos recursos são muitas vezes pequenos e não documentados, e carecem de dimensões padrão, dificultando o desenvolvimento e os testes.
Os métodos de desenvolvimento atuais geralmente usam grandes quantidades de dados e recursos computacionais que estão prontamente disponíveis em idiomas com muitos recursos, como inglês e chinês. A PNL portuguesa utiliza modelos multilíngues como mBERT, mT5 e BLOOM ou modelos treinados em inglês com bom desempenho. No entanto, estes métodos muitas vezes ignoram as características únicas do português. Os benchmarks de teste são antigos ou baseados em conjuntos de dados em inglês, o que os torna menos aplicáveis ao português.
Para lidar com isso, pesquisadores de na Universidade de Bonn eles desenvolveram GigaVerboum grande corpus de texto português de 200 bilhões de tokens e treinou uma série de decodificadores-transformadores nomeados. O Tucano. Estes modelos visam melhorar o desempenho dos modelos de língua portuguesa através da utilização de um conjunto de dados grande e de alta qualidade.
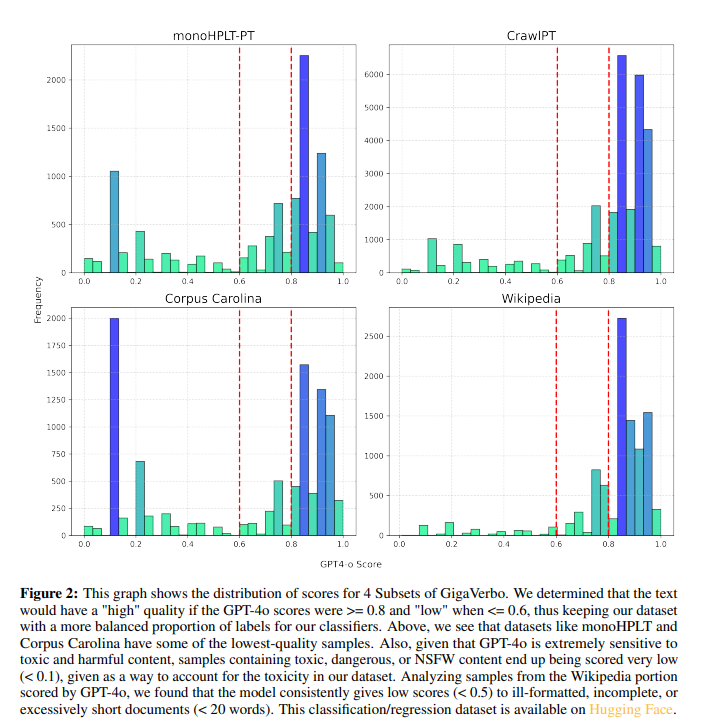
EU GigaVerbo O conjunto de dados é uma compilação de texto em português de alta qualidade, refinado usando técnicas de filtragem personalizadas baseadas no teste GPT-4. O processo de filtragem melhorou o pré-processamento do texto, retendo 70% do conjunto de dados do modelo. Baseados no design da Llama, os modelos Tucano são implementados utilizando um Hugging Face para facilitar o acesso ao público. Técnicas como incorporação RoPE, raiz quadrada média padrão e ativação Silu em vez de SwiGLU foram usadas. O treinamento é feito usando simulação de linguagem causal e perda de entropia cruzada. Os modelos variam de parâmetros de 160M a 2,4B, o maior dos quais é treinado em 515 bilhões de tokens.
Os testes destes modelos mostram que têm um desempenho igual ou melhor que outros modelos portugueses e multilingues da mesma dimensão em vários benchmarks portugueses. As curvas de perda e confusão de treinamento para validação dos quatro modelos básicos mostraram que modelos maiores geralmente reduzem a perda e a confusão de forma mais eficaz, com o efeito amplificado por tamanhos de cluster maiores. Os benchmarks são salvos regularmente em 10,5 bilhões de tokens e o desempenho é monitorado em vários benchmarks. Os coeficientes de correlação de Pearson apresentaram resultados mistos: alguns benchmarks, como CALAME-PT, LAMBADA e HellaSwag, melhoraram com o escalonamento, enquanto outros, como os testes da OAB, não apresentaram correlação com a introdução de tokens. A escala inversa foi observada em pequenos modelos multiparâmetros, sugerindo potenciais limitações. Os benchmarks de desempenho também confirmam isso O Tucano supera os modelos multilíngue e português anterior na avaliação nativa, pois CALAME-PT e testes interpretados por máquina como LAMBADA.
Concluindo, as séries GigaVerbo e Tucano melhoram o desempenho dos modelos de língua portuguesa. O trabalho proposto inclui um pipeline de otimização, incluindo criação de conjunto de dados, filtragem, ajuste de hiperparâmetros e testes, com foco na abertura e reprodutibilidade. Também demonstrou o potencial para desenvolver modelos linguísticos com poucos recursos através da recolha de dados em grande escala e de técnicas de formação avançadas. A contribuição destes investigadores será benéfica no sentido de fornecer os recursos necessários para orientar estudos futuros.
Confira Página facial de papel e abraços. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
🎙️ 🚨 'Avaliação de vulnerabilidade de um modelo de linguagem grande: uma análise comparativa de técnicas de clustering vermelho' Leia o relatório completo (Promovido)
Nazmi Syed é estagiária de consultoria na MarktechPost e está cursando bacharelado em ciências no Instituto Indiano de Tecnologia (IIT) Kharagpur. Ele tem uma profunda paixão pela Ciência de Dados e está explorando ativamente a ampla aplicação da inteligência artificial em vários setores. Fascinada pelos avanços tecnológicos, a Nazmi está comprometida em compreender e aplicar inovações de ponta em situações do mundo real.
🧵🧵 [Download] Avaliação do relatório do modelo de risco linguístico principal (ampliado)

 usando um modelo de linguagem pura sem adaptadores externos")
