
Os agentes de interface gráfica do usuário (GUI) são importantes para interações automatizadas no ambiente digital, semelhante à forma como as pessoas usam software usando teclados, mouses ou telas sensíveis ao toque. Os agentes GUI podem simplificar processos complexos, como testes de software, automação web e assistência digital, navegando e manipulando automaticamente elementos GUI. Esses agentes são projetados para perceber o que os rodeia por meio de informações visuais, permitindo-lhes interpretar a estrutura e o conteúdo das interações digitais. Com o avanço da inteligência artificial, os investigadores pretendem tornar os agentes GUI mais eficientes, reduzindo a sua dependência dos métodos de entrada tradicionais, tornando-os mais semelhantes aos humanos.
Um problema fundamental com os agentes GUI existentes reside na sua dependência de representações baseadas em texto, como HTML ou árvores de acessibilidade, que muitas vezes introduzem ruído e complexidade desnecessária. Embora eficazes, estes métodos são limitados pela sua dependência da integridade e precisão dos dados textuais. Por exemplo, as árvores de acessibilidade podem não ter elementos ou anotações importantes, e o código HTML pode conter informações irrelevantes ou desnecessárias. Como resultado, esses agentes precisam de ajuda com latência e sobrecarga computacional ao navegar em diferentes tipos de GUIs em plataformas como aplicativos móveis, software de desktop e interfaces web.
Foram propostos alguns modelos linguísticos de grande escala (MLLMs) que combinam representações visuais e baseadas em texto para interpretar e interagir com GUIs. Apesar dos avanços recentes, estes modelos ainda requerem informações significativas baseadas em texto, o que dificulta a sua capacidade de generalização e prejudica o desempenho. Vários modelos existentes, como SeeClick e CogAgent, demonstraram sucesso moderado. No entanto, eles precisam ser mais robustos para uso prático em diferentes ambientes devido à dependência da entrada baseada em texto descrita anteriormente.
Pesquisadores da Ohio State University e da Orby AI introduziram um novo modelo chamado UGground, que elimina totalmente a necessidade de entrada baseada em texto. O UGground usa uma abordagem somente de visualização que funciona diretamente na renderização visual da GUI. Usando apenas a percepção visual, este modelo pode replicar com mais precisão as interações humanas com GUIs, permitindo que os agentes executem tarefas em nível de pixel diretamente na GUI, sem depender de quaisquer dados baseados em texto, como HTML. Essas melhorias melhoram muito a eficiência e a robustez dos agentes GUI, tornando-os mais flexíveis e utilizáveis em aplicações do mundo real.
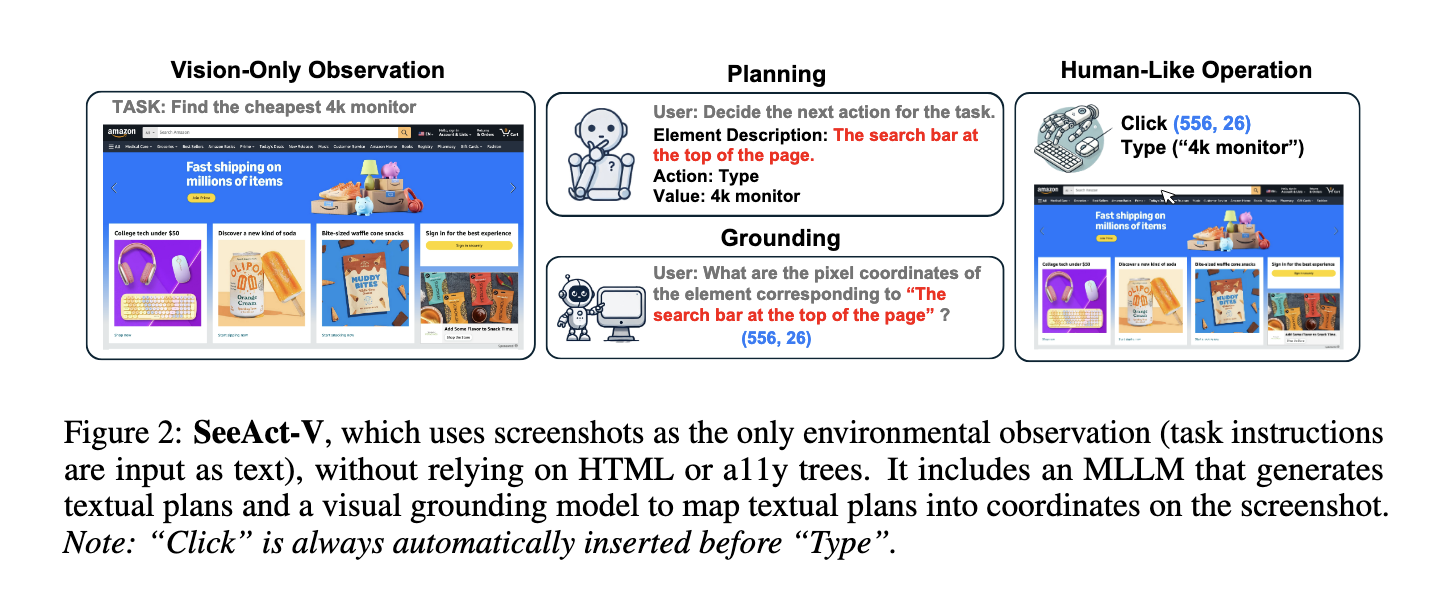
A equipe de pesquisa desenvolveu o UGground usando um método simples, mas eficaz, combinando dados sintéticos baseados na web e modificando ligeiramente a estrutura do LLaVA. Eles construíram a maior GUI já vista para o conjunto de dados básico, que inclui 10 milhões de componentes de GUI, além de 1,3 milhão de capturas de tela, incluindo layouts e tipos de GUI. Os pesquisadores montaram uma estratégia de integração de dados que permite ao modelo aprender com várias dicas visuais, fazendo com que o UGround funcione em diferentes plataformas, incluindo ambientes web, desktop e móveis. Este extenso conjunto de dados ajuda o modelo a mapear com precisão as diversas expressões de ponteiro de objetos GUI para suas coordenadas na tela, facilitando a visualização precisa em aplicativos do mundo real.
Os resultados mostraram que o UGround supera os modelos existentes em vários testes de benchmark. Alcançou uma alta precisão de até 20% em tarefas de suporte visual em todos os seis benchmarks, que incluíram três estágios: posicionamento, teste de agente offline e teste de agente online. Por exemplo, no benchmark ScreenSpot, que testa o suporte visual da GUI em diferentes plataformas, o UGground alcançou 82,8% de precisão em ambientes móveis, 63,6% em ambientes de desktop e 80,4% em ambientes web. Esses resultados mostram que a capacidade apenas visual do UGround permite que ele tenha um desempenho tão bom ou melhor que os modelos que usam entradas visuais e baseadas em texto.


Além disso, os agentes GUI equipados com UGground apresentaram desempenho significativamente superior em comparação com agentes de última geração que dependem de entrada multimodal. Por exemplo, na configuração do agente ScreenSpot, o UGround obteve um aumento médio de desempenho de 29% em relação aos modelos anteriores. O modelo também apresentou resultados impressionantes nos benchmarks AndroidControl e OmniACT, que testam a capacidade do agente de gerenciar um ambiente móvel e desktop, respectivamente. No AndroidControl, o UGground alcançou uma precisão de passo de 52,8% em tarefas de alto nível, superando os modelos anteriores por uma margem significativa. Da mesma forma, no benchmark OmniACT, o UGground recebeu uma pontuação de ação de 32,8, destacando sua eficiência e robustez em diversas tarefas de GUI.
Concluindo, o UGground aborda as principais limitações dos agentes GUI existentes, adotando uma perspectiva humana e uma abordagem de aterramento. Sua capacidade de generalizar em múltiplas plataformas e realizar operações em nível de pixel sem exigir entrada baseada em texto marca um grande avanço na computação humana. Este modelo melhora a eficiência e a precisão dos agentes GUI e estabelece as bases para desenvolvimentos futuros em navegação e comunicação automatizadas de GUI.
Confira Papel, O códigode novo O modelo do tamanho do rosto. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – Conferência de recuperação de dados GenAI (promovida)
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.


