
Pequenos modelos linguísticos (SLMs) tornaram-se uma área importante no processamento de linguagem natural (PNL) devido ao seu potencial para trazer inteligência de máquina de alta qualidade para dispositivos do dia a dia. Ao contrário dos modelos linguísticos de grande escala (LLMs) que funcionam dentro de centros de dados em nuvem e requerem recursos computacionais significativos, os SLMs visam democratizar a inteligência artificial, tornando-a acessível a dispositivos pequenos e com recursos limitados, como smartphones, tablets e wearables. Esses modelos normalmente variam de 100 milhões a 5 bilhões de parâmetros, o que é uma fração do que os LLMs usam. Apesar de seu pequeno tamanho, eles são projetados para executar tarefas linguísticas complexas de maneira eficaz, atendendo à crescente necessidade de inteligência de dispositivos em tempo real. A pesquisa sobre SLMs é importante, pois representa o futuro da IA acessível e eficiente, que pode operar sem depender de uma extensa infraestrutura em nuvem.
Um dos principais desafios da PNL moderna é o desenvolvimento de modelos de IA em dispositivos com recursos computacionais limitados. Os LLMs, embora poderosos, consomem muitos recursos, muitas vezes exigindo centenas de milhares de GPUs para funcionar com eficiência. Este requisito de computação limita a sua implantação em data centers centralizados, o que limita a sua capacidade de operar em dispositivos portáteis que exigem respostas em tempo real. O desenvolvimento de SLMs resolve esse problema criando modelos funcionais para serem executados diretamente no dispositivo, mantendo ao mesmo tempo alto desempenho em diversas tarefas de linguagem. Os pesquisadores reconheceram a importância da medição de desempenho, com o objetivo de criar modelos que exijam menos recursos, mas que ainda executem tarefas como raciocínio lógico, aprendizagem contextual e resolução de problemas matemáticos.
Os pesquisadores exploraram maneiras de reduzir a complexidade de grandes modelos sem comprometer sua capacidade de executar bem tarefas importantes. Métodos como poda de modelo, imersão de informações e quantização são comumente usados. A poda remove neurônios irrelevantes do modelo para reduzir seu tamanho e carga computacional. A destilação de informações transfere informações de um modelo maior para um modelo menor, permitindo que o modelo menor replique o comportamento de seu equivalente maior. A quantização reduz a precisão dos cálculos, o que ajuda a acelerar o modelo e reduzir o uso de memória. Além disso, inovações como compartilhamento de parâmetros e escalonamento em camadas otimizaram modelos para melhor desempenho em dispositivos como smartphones e tablets. Embora estes métodos tenham ajudado a melhorar a eficiência dos SLMs, muitas vezes são insuficientes para atingir o mesmo nível de desempenho que os LLMs sem melhorias adicionais.
Pesquisas da Universidade de Correios e Telecomunicações de Pequim (BUPT), do Laboratório Peng Cheng, da Helixon Research e da Universidade de Cambridge apresentam novos projetos arquitetônicos destinados a melhorar os SLMs. Seu trabalho se concentra em modelos baseados em transformadores somente decodificadores, que permitem processamento eficiente no dispositivo. Para reduzir as demandas computacionais, eles introduziram inovações como processos de atenção multi-perguntas e redes neurais feed-forward (FFNs). Por exemplo, a atenção multi-perguntas reduz a sobrecarga de memória frequentemente associada à abordagem de atenção em modelos de transformadores. Ao mesmo tempo, a estrutura FFN fechada permite que o modelo mova informações pela rede, melhorando drasticamente a eficiência. Essas melhorias permitem que pequenos modelos executem tarefas com mais eficiência, desde a compreensão da linguagem até o raciocínio e a resolução de problemas, usando menos recursos computacionais.
A arquitetura proposta pelos pesquisadores gira em torno do aumento do uso de memória e da velocidade de processamento. A introdução da atenção às perguntas em grupo permite que o modelo reduza o número de grupos de perguntas, preservando a diversidade de atenção. Este mecanismo provou ser muito eficaz na redução do uso de memória. Eles usam SiLU (Sigmoid Linear Unit) como função de ativação, o que mostra uma melhoria acentuada no tratamento de tarefas de linguagem em comparação com tarefas tradicionais como ReLU. Além disso, os pesquisadores introduziram a compensação não linear para lidar com problemas comuns em modelos pequenos, como o problema do colapso de recursos, que interfere na capacidade do modelo de processar dados complexos. Esta compensação é conseguida através da incorporação de recortes matemáticos avançados no projeto do transformador, garantindo que o modelo permaneça robusto mesmo quando é reduzido. Além disso, são utilizadas técnicas de compartilhamento de parâmetros, que permitem ao modelo reutilizar pesos em diferentes camadas, reduzindo ainda mais o uso de memória e melhorando os tempos de toque, tornando-o adequado para dispositivos com poder computacional limitado.
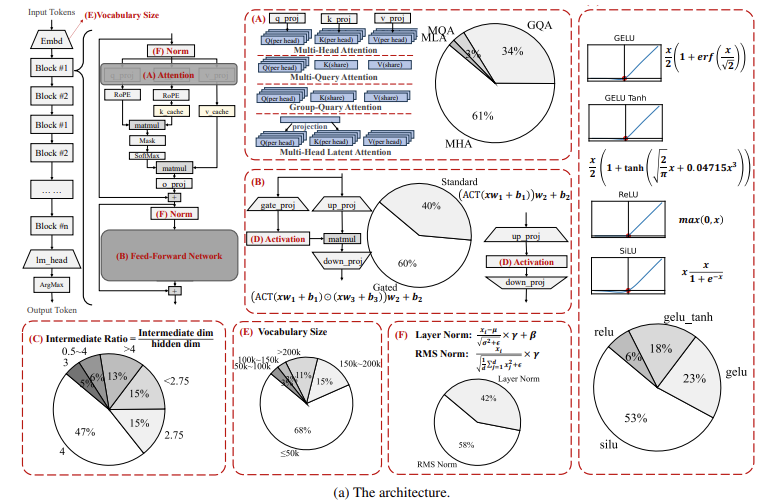
Os resultados deste estudo mostram melhorias significativas no desempenho e na eficiência. Um dos modelos mais proeminentes, Phi-3 mini, alcançou precisão 14,5% maior em tarefas de raciocínio matemático do que o LLaMA 3.1 de última geração, um grande modelo de linguagem com 7 bilhões de parâmetros. Além disso, em tarefas de raciocínio de senso comum, a família de modelos Phi superou vários modelos líderes, incluindo LLaMA, com uma pontuação de precisão de 67,6%. Da mesma forma, o modelo Phi-3 apresentou uma precisão de 72,4% em tarefas de resolução de problemas, colocando-o entre os SLMs de melhor desempenho. Esses resultados destacam o sucesso da nova arquitetura em manter o alto desempenho e, ao mesmo tempo, reduzir as demandas computacionais normalmente associadas a modelos maiores. A investigação também demonstrou que estes modelos são eficientes e escaláveis, proporcionando um desempenho consistente numa vasta gama de tarefas, desde raciocínio simples a problemas matemáticos complexos.
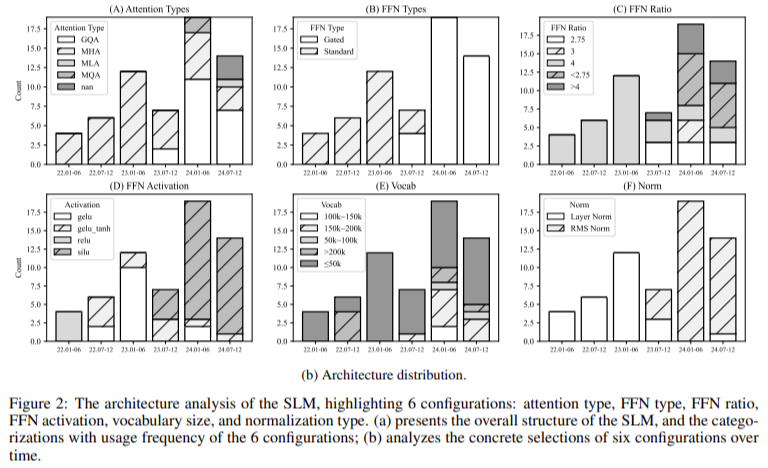
Em termos de implantação, os modelos foram testados em vários dispositivos de ponta, incluindo o Jetson Orin NX e smartphones de última geração. Os modelos mostraram uma redução significativa na latência de inferência e no uso de memória. Por exemplo, o modelo Qwen-2 1.5B reduziu a latência de inferência em mais de 50%, tornando-o um dos modelos mais eficientes testados. O uso de memória foi significativamente melhorado em modelos como o OpenELM-3B, que utilizou até 30% menos memória do que outros modelos com a mesma contagem de parâmetros. Esses resultados são promissores para o futuro dos SLMs, pois mostram que é possível alcançar alto desempenho em dispositivos com recursos limitados, abrindo a porta para aplicações de IA em tempo real em tecnologias móveis e vestíveis.
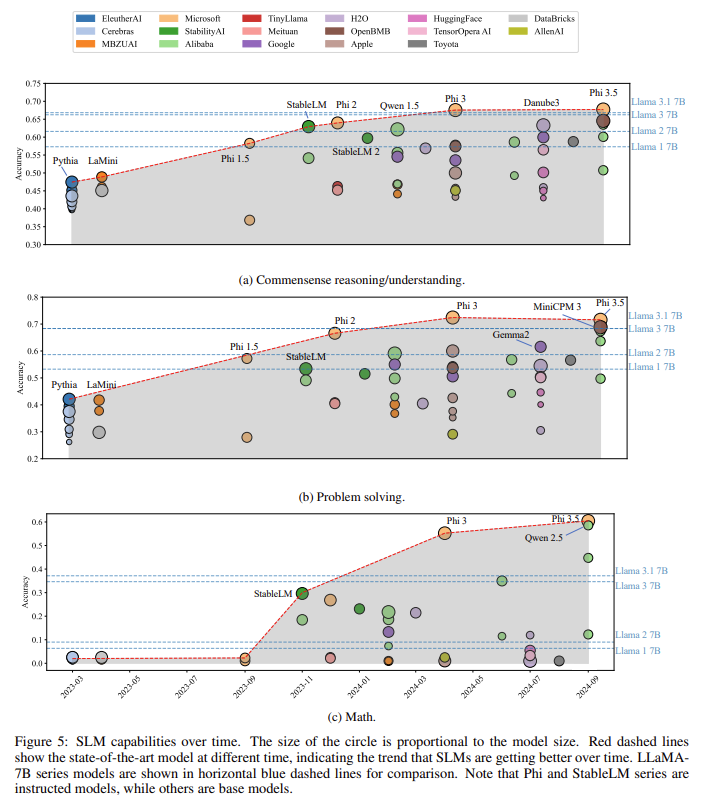
As principais conclusões do estudo podem ser resumidas da seguinte forma:
- Atenção à consulta de grupo e redes feed-forward ágatas (FFNs): Essas inovações reduzem significativamente o uso de memória e o tempo de processamento sem sacrificar o desempenho. A atenção às questões do grupo reduz o número de questões sem perder a atenção à diversidade, tornando o modelo mais eficiente.
- Conjuntos de dados de pré-treinamento de alta qualidade: A pesquisa enfatiza a importância de conjuntos de dados de código aberto de alta qualidade, como FineWeb-Edu e DCLM. A qualidade dos dados geralmente supera a quantidade, permitindo melhor otimização e poder de raciocínio.
- Compartilhamento de parâmetros e compensação de não linearidade: Essas técnicas desempenham um papel importante na melhoria do desempenho dos modelos em tempo de execução. O compartilhamento de parâmetros reduz a multiplicidade de camadas do modelo, enquanto a compensação não linear aborda o problema do colapso de recursos, garantindo que o modelo permaneça robusto em aplicações em tempo real.
- Modelo de estimativa: Apesar de seu pequeno tamanho, a família de modelos Phi tem superado consistentemente modelos maiores, como o LLaMA, em tarefas que exigem raciocínio matemático e compreensão geral, provando que os SLMs podem competir com os LLMs se forem projetados adequadamente.
- Remoção eficaz de bordas: Reduções significativas na latência e no uso de memória mostram que esses modelos são adequados para uso em dispositivos que consomem muitos recursos, como smartphones e tablets. Modelos como o Qwen-2 1.5B alcançaram uma redução de latência superior a 50%, garantindo seu uso prático em situações de tempo real.
- Criação de edifícios com impacto no mundo real: A introdução de técnicas como atenção de consulta de grupo, FFNs refinados e compartilhamento de parâmetros prova que inovações no nível da arquitetura podem trazer melhorias significativas de desempenho sem aumentar os custos de computação, tornando esses modelos úteis para ampla adoção na tecnologia cotidiana.
Concluindo, a pesquisa sobre modelos microlinguísticos fornece um caminho a seguir para criar IA de alto desempenho que pode ser executada em uma variedade de dispositivos sem depender de infraestrutura baseada em nuvem. O problema de medir a eficiência da computação foi resolvido com novos projetos arquitetônicos, como atenção a consultas em grupo e FFNs fechados, que fazem com que os SLMs forneçam resultados semelhantes aos dos LLMs, apesar de terem algumas limitações. A pesquisa mostra que, com o conjunto de dados, a arquitetura e as estratégias de implantação corretas, os SLMs podem ser dimensionados para lidar com uma variedade de tarefas, desde a inferência até a resolução de problemas, ao mesmo tempo em que funcionam bem em dispositivos com recursos limitados. Isto representa um avanço significativo no sentido de tornar a IA mais acessível e aplicável a aplicações do mundo real, garantindo que os benefícios da inteligência da máquina possam chegar aos utilizadores em diferentes plataformas.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso SubReddit de 52k + ML
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.


