
Os principais modelos linguísticos (LLMs) tiveram um sucesso notável no processamento de linguagem natural (PNL). Grandes modelos de aprendizagem profunda, especialmente arquiteturas baseadas em transformadores, cresceram exponencialmente em tamanho e complexidade, atingindo bilhões a bilhões de parâmetros. No entanto, eles apresentam desafios significativos nos recursos de computação e no uso de memória. Mesmo as GPUs avançadas lutam para lidar com modelos com bilhões de parâmetros, limitando o alcance de muitos pesquisadores porque o treinamento e o manuseio de modelos tão grandes exigem processamento significativo e recursos de computação de ponta. Portanto, o desenvolvimento de frameworks, bibliotecas e estratégias para superar esses desafios tornou-se essencial.
Estudos recentes revisaram modelos de linguagem, técnicas de otimização e métodos de aceleração para modelos de aprendizagem profunda e LLMs. Os estudos destacaram comparações de modelos, desafios de otimização, pré-treinamento, adaptação, implementação e avaliação de capacidade. Muitos métodos foram desenvolvidos para alcançar precisão comparável com custos de treinamento reduzidos, como algoritmos aprimorados, arquiteturas distribuídas e aceleração de hardware. Essas revisões fornecem informações valiosas para pesquisadores que buscam modelos de linguagem ideais e orientam desenvolvimentos futuros em LLMs mais sustentáveis e eficientes. Além disso, outros métodos de utilização de modelos de linguagem pré-treinados em tarefas de PNL foram explorados, contribuindo para o desenvolvimento contínuo na área.
Pesquisadores da Universidade Obuda, Budapeste, Hungria; Universidade J. Selye, Komarno, Eslováquia; e o Instituto de Ciência da Computação e Controle (SZTAKI), Rede Húngara de Pesquisa (HUN-REN), Budapeste, Hungria, apresentaram uma revisão sistemática da literatura (SLR) analisando 65 publicações de 2017 a dezembro de 2023. A SLR concentra-se na expansão e aceleração . LLMs sem sacrificar a precisão. Este artigo segue a abordagem PRISMA para fornecer uma visão geral do desenvolvimento de modelagem de linguagem e examina estruturas e bibliotecas amplamente utilizadas. Apresenta uma taxonomia para o desenvolvimento de LLMs baseada em três classes: treinamento, previsão e renderização de sistema. Os pesquisadores investigaram as mais recentes técnicas de desenvolvimento e aceleração, incluindo otimização de treinamento, otimização de hardware e medição. Eles também apresentam dois estudos de caso para demonstrar formas eficazes de abordar as limitações de recursos do LLM, mantendo ao mesmo tempo o desempenho.
SLR implementa uma estratégia de pesquisa abrangente usando várias bibliotecas digitais, bancos de dados e ferramentas baseadas em IA. A busca, realizada até 25 de maio de 2024, tem como foco cursos relacionados à modelagem de linguagem, principalmente preparação e aceleração de LLM. Além disso, as ferramentas ResearchRabbit e Rayyan AI simplificaram a coleta de dados e a seleção de estudos. O processo de seleção consiste em rigorosos critérios de inclusão, com foco nas principais técnicas de modelagem de linguagem, incluindo modelos baseados em transformadores. Foi utilizado um processo de triagem em duas etapas, (a) avaliação inicial baseada na elegibilidade e (b) critérios de inclusão. O trabalho de campo de Rayyan sobre “estimativa computadorizada” ajudou na seleção final, com os autores verificando novamente os assuntos excluídos para garantir a precisão.
Os organismos de formação LLM e as bibliotecas enfrentam grandes desafios devido à complexidade e tamanho dos modelos. Estruturas de treinamento distribuídas, como Megatron-LM e CoLLiE, abordam esses problemas dividindo modelos em várias GPUs para processamento paralelo. Melhorias de eficiência e velocidade são alcançadas por meio de otimizações no nível do sistema em estruturas como LightSeq2 e ByteTransformer, que otimizam a utilização da GPU e reduzem o consumo de memória. Além disso, o gerenciamento de memória é um aspecto importante que pode ser tratado com CoLLiE, que usa paralelismo 3D e distribui memória de forma eficiente entre máquinas de treinamento e GPUs.
Estas cinco estruturas e bibliotecas principais ajudam a superar as limitações do treinamento LLM:
- O GPipe treinou com sucesso grandes modelos de transformadores multilíngues, superando modelos individuais menores.
- ByteTransformer demonstra o alto desempenho de transformadores do tipo BERT em vários benchmarks.
- Megatron-LM possibilita o treinamento de LLMs de bilhões de parâmetros, alcançando resultados de última geração em operações de PNL com alto desempenho.
- LightSeq2 acelera drasticamente o treinamento do modelo de transformador, melhorando o desempenho em até 308%.
- CoLLiE introduz treinamento LLM conjunto, melhorando a eficiência e eficácia em modelos grandes como o LLaMA-65B, sem comprometer o desempenho geral.
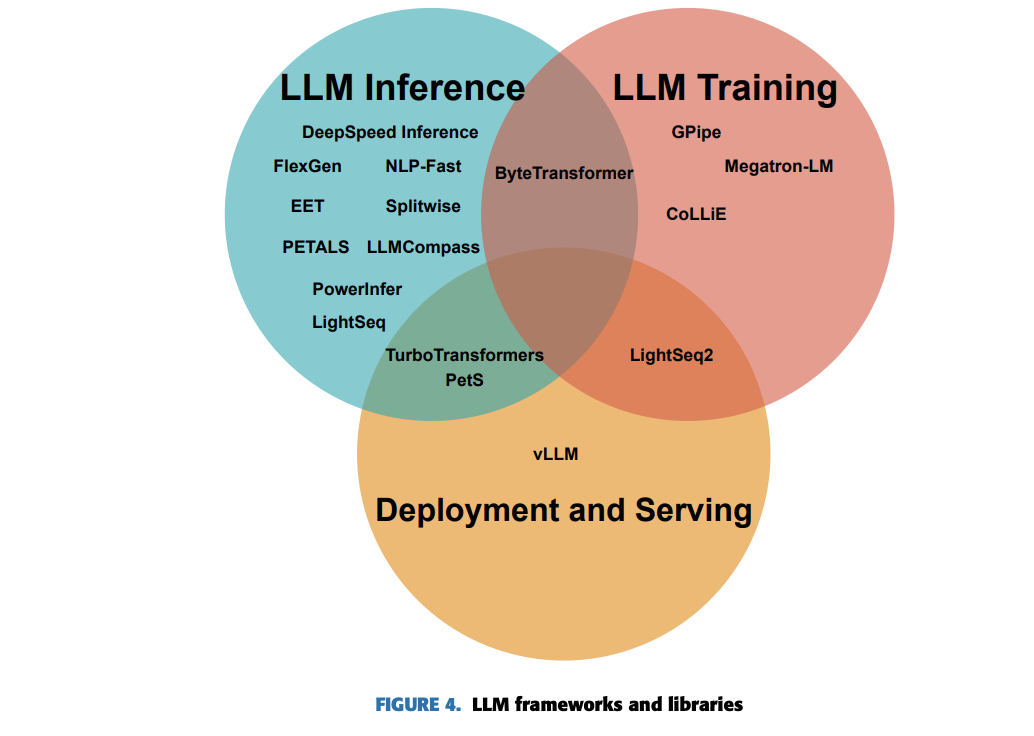
Agora, se falarmos sobre bibliotecas e estruturas de inferência LLM, os principais desafios enfrentados são o custo computacional, restrições de recursos, requisitos de velocidade de equilíbrio, precisão e utilização de recursos. Experiência em hardware, otimização de recursos, desenvolvimento algorítmico e computação distribuída são resultados essenciais para enfrentar esses desafios. Estruturas como Splitwise separam as fases de computação mais poderosas e com uso intensivo de memória em hardware especializado, e o FlexGen otimiza a utilização de recursos em CPU, GPU e disco. Além disso, bibliotecas como EET e LightSeq ajudam a acelerar a renderização da GPU usando algoritmos personalizados e gerenciamento de memória. Essas melhorias mostram desempenho significativo, com estruturas como DeepSpeedInference e FlexGen para alcançar maior desempenho e latência reduzida.
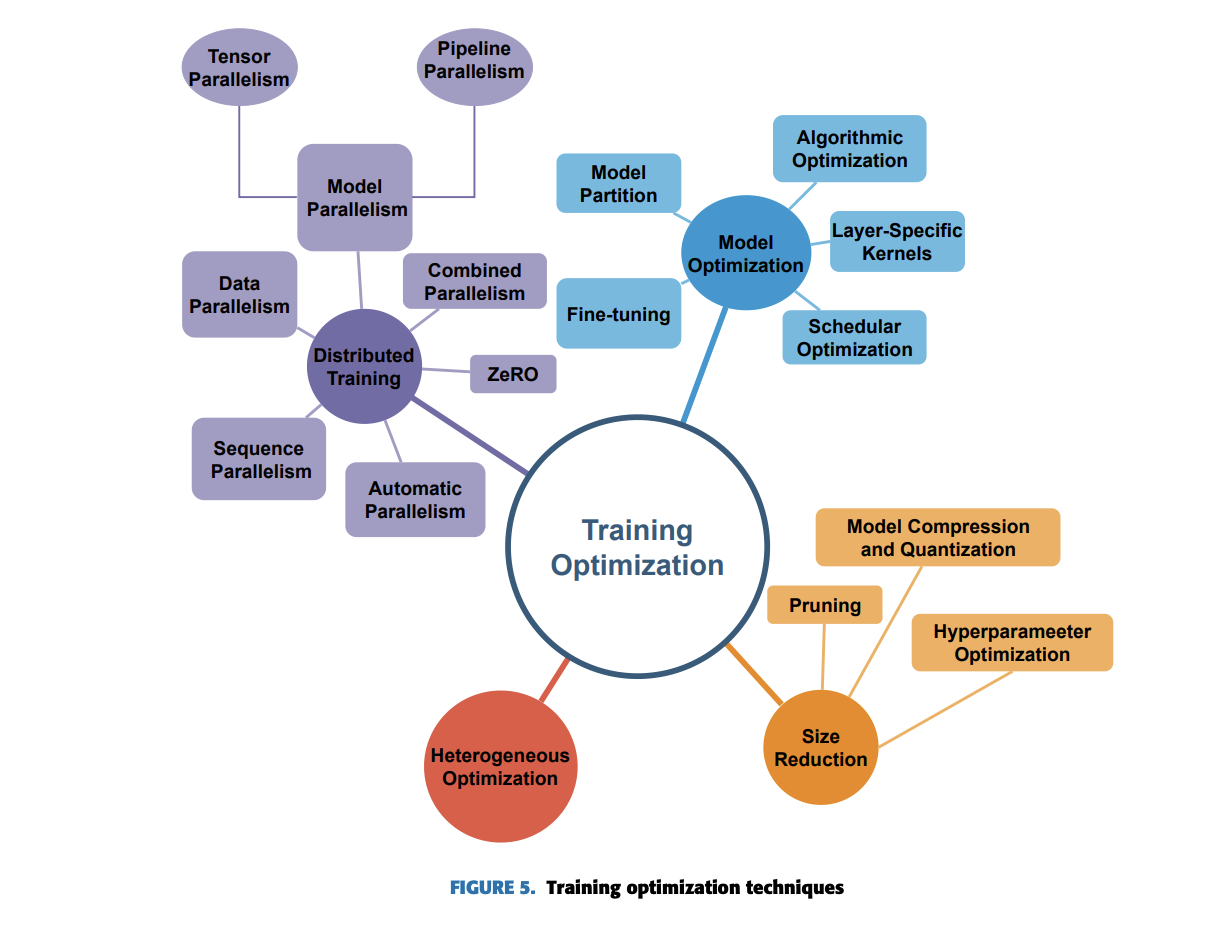
Os principais modelos linguísticos (LLMs) enfrentam grandes desafios durante o desenvolvimento da formação. Eles incluem (a) restrições de recursos que limitam seu treinamento e uso em dispositivos únicos devido a altos requisitos de memória e computacionais, (b) equilíbrio entre eficiência e precisão entre eficiência de recursos e manutenção do desempenho do modelo, (c) restrições de memória ao distribuir LMs entre dispositivos. , (d) sobrecarga de comunicação durante a troca de dados que pode retardar o treinamento, (e) heterogeneidade de hardware que complica o uso eficiente de diferentes dispositivos e (f) restrições de memória e comunicação.
Para superar esses desafios, várias estratégias de LLM foram desenvolvidas:
- Algorítmico: Técnicas como FlexGen melhoram a eficiência por meio de computação otimizada e chaves de hardware especializadas.
- Fragmentação do modelo: Técnicas como GPipe permitem o processamento em vários dispositivos, mesmo com memória limitada.
- Otimizando o desempenho: Técnicas como AlphaTuning e LoRA permitem ajustar modelos grandes em memória limitada, reduzindo o número de parâmetros ajustáveis.
- Otimizando o processador: Técnicas como TurboTransformers melhoram a resposta e o desempenho das GPUs.
Outras configurações incluem configurações de redução de tamanho, técnicas de paralelismo, configurações de memória, múltiplas configurações e compatibilidade automática:
Embora a SLR nas técnicas de desenvolvimento de modelos de linguagem seja perfeita, ela tem algumas limitações. A estratégia de busca pode ter perdido estudos relevantes usando termos diferentes. Além disso, a inclusão limitada de dados levou à negligência de pesquisas importantes. Estes factores podem afectar a integralidade da revisão, especialmente no contexto da história e dos desenvolvimentos recentes.
Neste artigo, os pesquisadores apresentaram uma revisão sistemática da literatura (RSL) que analisou 65 publicações de 2017 a dezembro de 2023, seguindo o método PRISMA, e avaliaram estratégias para melhorar e acelerar LLMs. Identificou desafios no treinamento, conceituação e operação de um programa LLM multibilionário ou trilhão de parâmetros. A taxonomia proposta fornece um guia claro para os pesquisadores navegarem pelas diversas estratégias de otimização. Uma revisão de bibliotecas e estruturas apoia a formação e disseminação eficazes de LLM, e dois estudos de caso demonstram formas práticas de melhorar a formação de modelos e melhorar a eficiência do pensamento. Embora os desenvolvimentos recentes sejam promissores, o estudo enfatiza a necessidade de pesquisas futuras para concretizar plenamente o potencial das estratégias de desenvolvimento do LLM.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)

Sajjad Ansari se formou no último ano do IIT Kharagpur. Como entusiasta da tecnologia, ele examina as aplicações da IA com foco na compreensão do impacto das tecnologias de IA e suas implicações no mundo real. Seu objetivo é explicar conceitos complexos de IA de uma forma clara e acessível.
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)

 com decodificação inferencial")
