
Reconhecimento de movimento humano o uso de séries temporais de dispositivos móveis e vestíveis é frequentemente usado como principal informação de contexto para diversas aplicações, desde monitoramento do estado de saúde até análise de desempenho esportivo e estudos de comportamento do usuário. No entanto, a recolha de dados de séries temporais de movimentos em grande escala continua a ser um desafio porque segurança ou privacidade ansiedade. No domínio das séries temporais dinâmicas, a falta de conjuntos de dados e de trabalho de pré-treinamento eficiente torna difícil o desenvolvimento de modelos uniformes que possam funcionar com dados limitados. Geralmente, os modelos existentes realizam treinamento e testes no mesmo conjunto de dados e lutam para generalizar em diferentes conjuntos de dados, dados três desafios distintos dentro do domínio do problema de série temporal de movimento: Em primeiro lugarcolocar instrumentos em diferentes partes do corpo – como no pulso e na perna – leva a dados muito diferentes, dificultando a aplicação de um modelo treinado para uma parte em outra parte. Segunda vezcomo os dispositivos podem ser segurados de diferentes maneiras, isso é problemático porque os modelos treinados com um dispositivo em uma posição muitas vezes têm dificuldades quando o dispositivo é segurado de uma maneira diferente. Finalmentediferentes conjuntos de dados concentram-se frequentemente em diferentes tipos de atividades, tornando difícil comparar ou combinar dados de forma eficaz.
A classificação de séries temporais de movimento geral depende de diferentes classificadores para cada conjunto de dados, utilizando métodos como extração estatística de características, CNN, RNNse modelos de atenção. Modelos de uso geral são semelhantes TimesNet de novo COMPARTILHE buscam flexibilidade no trabalho, mas exigem treinamento ou testes no mesmo conjunto de dados; portanto, eles reduzem a flexibilidade. A aprendizagem autodirigida ajuda na representação da aprendizagem, embora a generalização para diversos conjuntos de dados continue a ser um desafio. Modelos profissionais são semelhantes ImagemBind de novo IMU2CLIP consideram dados de movimento e texto, mas são limitados pelo treinamento específico do dispositivo. Os métodos que utilizam modelos linguísticos de grande escala (LLMs) dependem do conhecimento, mas têm dificuldade em reconhecer tarefas complexas, uma vez que não são treinados em séries temporais móveis e têm dificuldade em reconhecer tarefas complexas com precisão.
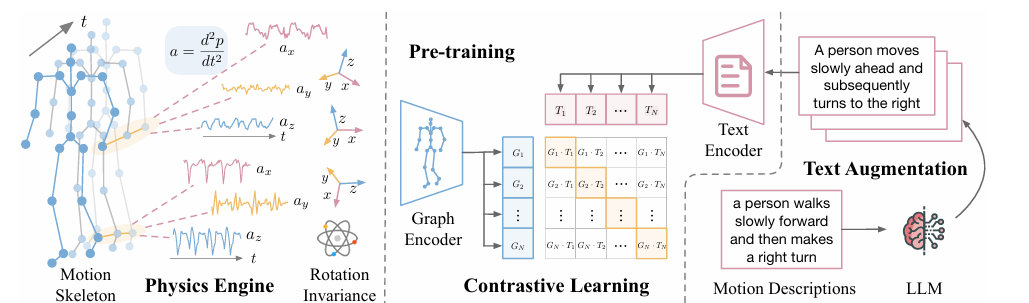
Um grupo de pesquisadores de Universidade da Califórnia em San Diego, Amazonas, de novo Qualcomm proposto UniMTS como o primeiro processo integrado de pré-treinamento para uma série temporal móvel que inclui vários recursos e funções sutis do dispositivo. O UniMTS usa uma estrutura de aprendizagem diferente para vincular dados dinâmicos de séries temporais com descrições de texto aprimoradas de modelos linguísticos de grande escala (LLMs). Isso ajuda o modelo a compreender o significado por trás de vários movimentos e permite combinar várias funções. Com extenso treinamento prévio, o UniMTS gera dados de séries temporais de movimento com base em dados esqueléticos detalhados existentes, cobrindo várias partes do corpo. Os dados gerados são então processados usando redes gráficas para capturar relações espaciais e temporais em diferentes locais de dispositivos, ajudando o modelo a integrar dados de diferentes locais de dispositivos.
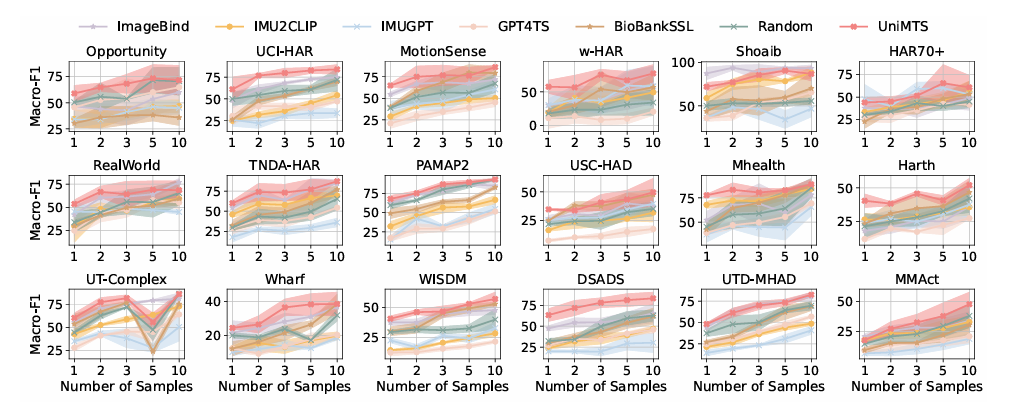
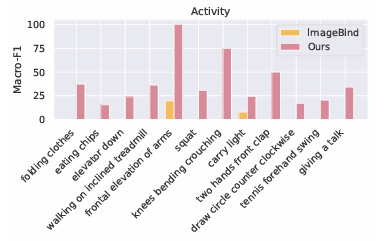
O processo começa criando dados de movimento do esqueleto e ajustando-os de acordo com diferentes condições. Ele também usa um codificador gráfico para entender como os links estão conectados, para que funcione bem em diferentes dispositivos. As definições de texto são desenvolvidas usando exemplos dos principais idiomas. Para criar dados de movimento, ele calcula a velocidade e a aceleração de cada junta enquanto processa suas posições e posições, adicionando ruído para simular erros de sensores do mundo real. Para lidar com inconsistências no formato do dispositivo, o UniMTS usa aumento de dados para criar um formato aleatório durante o pré-treinamento. Este método leva em consideração variações na orientação do dispositivo e na configuração do eixo. Ao combinar dados de movimento com descrições textuais, o modelo pode se adaptar a diferentes situações e tipos de trabalho. Para treinamento, o UniMTS usa aumento invariante de rotação dos dados para lidar com diferenças de orientação do dispositivo. Testado em HumanML3D O conjunto de dados e 18 alguns conjuntos de dados de referência de tempo de movimento do mundo real, especialmente com melhorias de desempenho de 340% no caso de tiro zero, 16,3% em algumas sessões de fotos também 9,2% na configuração de tiro completo, em comparação com as bases mais eficientes. O desempenho do modelo foi comparado com linhas de base como ImagemBind de novo IMU2CLIP. Os resultados mostraram que o UniMTS teve um desempenho melhor do que outros modelos, especialmente em configurações de disparo zero, com base em um teste estatístico que confirmou uma melhoria significativa.
Em conclusão, o modelo pré-treinado proposto UniMTS é baseado apenas em dados simulados pela física, mas mostra uma generalização notável em conjuntos de dados de séries temporais de vários movimentos, cobrindo localizações, formas e funções de dispositivos exclusivos. Embora use sua funcionalidade de maneira tradicional, o UniMTS também tem algumas limitações. Num sentido mais amplo, este modelo de classificação de séries temporais pré-treinado pode servir como uma base potencial para pesquisas futuras no campo do reconhecimento de movimento humano!
Confira Papel, GitHubde novo Modelo Em um rosto abraçado. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[Sponsorship Opportunity with us] Promova sua pesquisa/produto/webinar para mais de 1 milhão de leitores mensais e mais de 500 mil membros da comunidade
Divyesh é estagiário de consultoria na Marktechpost. Ele está cursando BTech em Engenharia Agrícola e Alimentar pelo Instituto Indiano de Tecnologia, Kharagpur. Ele é um entusiasta de Ciência de Dados e Aprendizado de Máquina que deseja integrar essas tecnologias avançadas no domínio agrícola e resolver desafios.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️
: uma abordagem integrada para reforçar a aprendizagem humana e o feedback de IA, resolvendo desafios de padronização e coleta de feedback")

