
O campo da aquisição de informação desenvolveu-se rapidamente devido ao crescimento exponencial dos dados digitais. Com o crescente volume de dados não estruturados, métodos eficazes de pesquisa e recuperação de informações relevantes são mais importantes do que nunca. As técnicas de pesquisa baseadas em palavras-chave geralmente precisam capturar o significado sutil do texto, levando a resultados de pesquisa imprecisos ou irrelevantes. Esta questão é particularmente importante com conjuntos de dados complexos que incluem diferentes tipos de mídia, como texto, imagens e vídeos. A adoção generalizada de dispositivos inteligentes e redes sociais também contribuiu para este crescimento de dados, com estimativas sugerindo que os dados não estruturados poderão representar 80% do volume total de dados até 2025. Assim, existe uma necessidade crítica de mecanismos robustos que possam mudar. esses dados são informações significativas.
Um dos maiores desafios na recuperação de informação é lidar com a alta dimensionalidade e a natureza dinâmica dos conjuntos de dados modernos. As técnicas existentes muitas vezes precisam de ajuda para fornecer soluções escaláveis e eficientes para lidar com consultas multivetoriais ou integrar atualizações em tempo real. Isto é especialmente problemático para aplicações que requerem recuperação rápida de resultados contextualmente relevantes, tais como sistemas de recomendação e grandes motores de busca. Embora algum progresso tenha sido feito no desenvolvimento de métodos de recuperação usando análise semântica latente (LSA) e métodos de aprendizagem profunda, esses métodos ainda precisam abordar as lacunas semânticas entre consultas e documentos.
Os atuais sistemas de recuperação de informação, como o Milvus, têm tentado fornecer suporte para o gerenciamento de dados vetoriais em grande escala. No entanto, esses sistemas são prejudicados pela dependência de conjuntos de dados estáticos e pela falta de flexibilidade no tratamento de consultas multivetoriais complexas. Os algoritmos e bibliotecas tradicionais muitas vezes dependem fortemente do armazenamento da memória principal e não podem distribuir dados entre várias máquinas, o que limita a sua escalabilidade. Isto impede a sua adaptabilidade a situações do mundo real, onde os dados estão em constante mudança. Como resultado, as soluções existentes lutam para fornecer a precisão e a eficiência exigidas em ambientes dinâmicos.
Uma equipe de pesquisadores da Universidade de Washington apresentou Pesquisa vetorialuma nova estrutura de recuperação de documentos projetada para resolver essas limitações. VectorSearch incorpora modelos de linguagem avançados, técnicas de indexação híbrida e métodos para lidar com consultas multivetoriais para melhorar a precisão e escalabilidade da recuperação. Ao usar métodos de incorporação de vetores e indexação regular, o VectorSearch pode lidar com eficiência com conjuntos de dados em grande escala, tornando-o uma ferramenta poderosa para tarefas de pesquisa complexas. A estrutura inclui mecanismos de cache e algoritmos de pesquisa avançados, que melhoram os tempos de resposta e o desempenho geral. Esses recursos o diferenciam dos sistemas convencionais, fornecendo uma solução abrangente de recuperação de documentos.
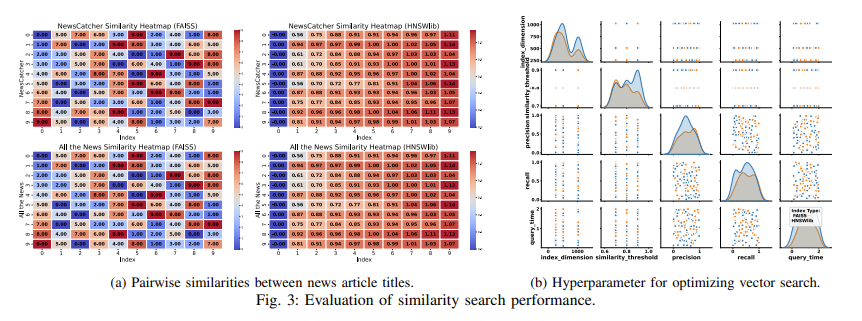
VectorSearch funciona como um sistema híbrido que combina os pontos fortes de múltiplas técnicas de indexação, como FAISS para indexação distribuída e HNSWlib para otimização de pesquisa hierárquica. Essa abordagem permite o gerenciamento contínuo de conjuntos de dados em grande escala em várias máquinas. Além disso, introduz novos algoritmos para pesquisa multivetorial, codificando documentos em incorporações de grande comprimento que capturam relações semânticas entre diferentes partes de dados. A integração dessas incorporações em um banco de dados vetorial permite que o sistema encontre documentos relevantes com base nas consultas dos usuários de maneira eficiente. Testes em conjuntos de dados do mundo real mostram que o VectorSearch supera os sistemas existentes, com uma taxa de recall de 76,62% e uma taxa de precisão de 98,68% em um índice de 1024.
Os testes de desempenho do VectorSearch revelaram melhorias significativas em várias métricas. O sistema alcançou um tempo médio de consulta de 0,47 segundos ao usar o modelo BERT-base-uncased e o método de índice FAISS, que é muito mais rápido que os sistemas de recuperação convencionais. Esta redução no tempo de consulta é atribuída à nova implementação de indexação hierárquica e tratamento de consultas multivetoriais. Além disso, a estrutura proposta suporta atualizações em tempo real, permitindo lidar com conjuntos de dados dinâmicos sem reindexação. Essas melhorias tornam o VectorSearch uma solução versátil para aplicações que vão desde mecanismos de pesquisa na web até sistemas de recomendação.
As principais conclusões do estudo incluem:
- Alta precisão e recall: VectorSearch alcançou uma taxa de recall de 76,62% e uma taxa de precisão de 98,68% ao usar o índice 1024, modelos básicos que apresentam melhor desempenho em várias tarefas de recuperação.
- Tempo de perguntas reduzido: O sistema reduziu significativamente o tempo de consulta, atingindo uma média de 0,47 segundos para dados longos.
- Escalabilidade: Ao combinar FAISS com HNSWlib, o VectorSearch lida com conjuntos de dados grandes e dinâmicos de forma eficiente, tornando-os adequados para aplicações em tempo real.
- Suporte de dados dinâmicos: A estrutura oferece suporte a atualizações em tempo real, permitindo manter o alto desempenho à medida que os dados mudam.

Concluindo, VectorSearch apresenta uma solução robusta para os desafios enfrentados pelos sistemas de recuperação de informação existentes. Ao introduzir uma abordagem extensível e flexível, a equipe de pesquisa criou uma estrutura que atende às necessidades das aplicações modernas com uso intensivo de dados. A combinação de métodos de indexação híbridos, funcionalidade de pesquisa multivetorial e modelos de linguagem aprimorados levam a melhorias significativas na precisão e eficiência de recuperação. Esta pesquisa abre caminho para desenvolvimentos futuros neste campo, fornecendo informações valiosas sobre o desenvolvimento de sistemas de recuperação de documentos de próxima geração.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit.
Convidamos startups, empresas e institutos de pesquisa que trabalham em modelos de microlinguagem para participar deste próximo projeto Revista/Relatório 'Modelos de Linguagem Pequena' Marketchpost.com. Esta revista/relatório será lançada no final de outubro/início de novembro de 2024. Clique aqui para agendar uma chamada!
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.


