
A síntese de fala tornou-se uma área de pesquisa transformadora, com foco na criação de efeitos sonoros naturais e sincronizados a partir de vários inputs. A combinação de dados de texto, vídeo e áudio fornece uma maneira abrangente de simular interações humanas. Os avanços no aprendizado de máquina, especialmente nas arquiteturas baseadas em transformadores, impulsionaram a inovação, permitindo o aprimoramento de aplicações como fala cruzada e síntese de voz pessoal.
Um desafio constante neste campo é alinhar com precisão a fala com sinais visuais e textuais. Os métodos tradicionais, como a extração de fala baseada em lábios ou modelos de conversão de texto em fala (TTS), têm limitações. Esses métodos geralmente exigem assistência na manutenção da sincronização e do ambiente em diversas situações, como ambientes multilíngues ou condições visuais complexas. Esta limitação limita seu uso em aplicações do mundo real que exigem alta fidelidade e compreensão contextual.
As ferramentas existentes dependem fortemente de entradas monomodo ou de estruturas complexas de integração multimodal. Por exemplo, modelos de detecção labial usam sistemas pré-treinados para cortar vídeos incorporados, enquanto outros sistemas baseados em texto processam apenas recursos linguísticos. Apesar destes esforços, o desempenho destes modelos permanece baixo, pois muitas vezes não conseguem capturar as capacidades visuais e textuais que são essenciais para a síntese natural da fala.
Pesquisadores da Apple e da Universidade de Guelph introduziram um modelo de transformador multimodal chamado Visatronic. Este modelo integrado processa dados de vídeo, texto e fala por meio de um ambiente de incorporação compartilhado, aprimorando os recursos do conversor automático. Ao contrário das arquiteturas multimodais tradicionais, a Visatronic completa o processamento antes de ver os lábios, fornecendo uma solução simples para produzir fala compatível com entrada escrita e visual.
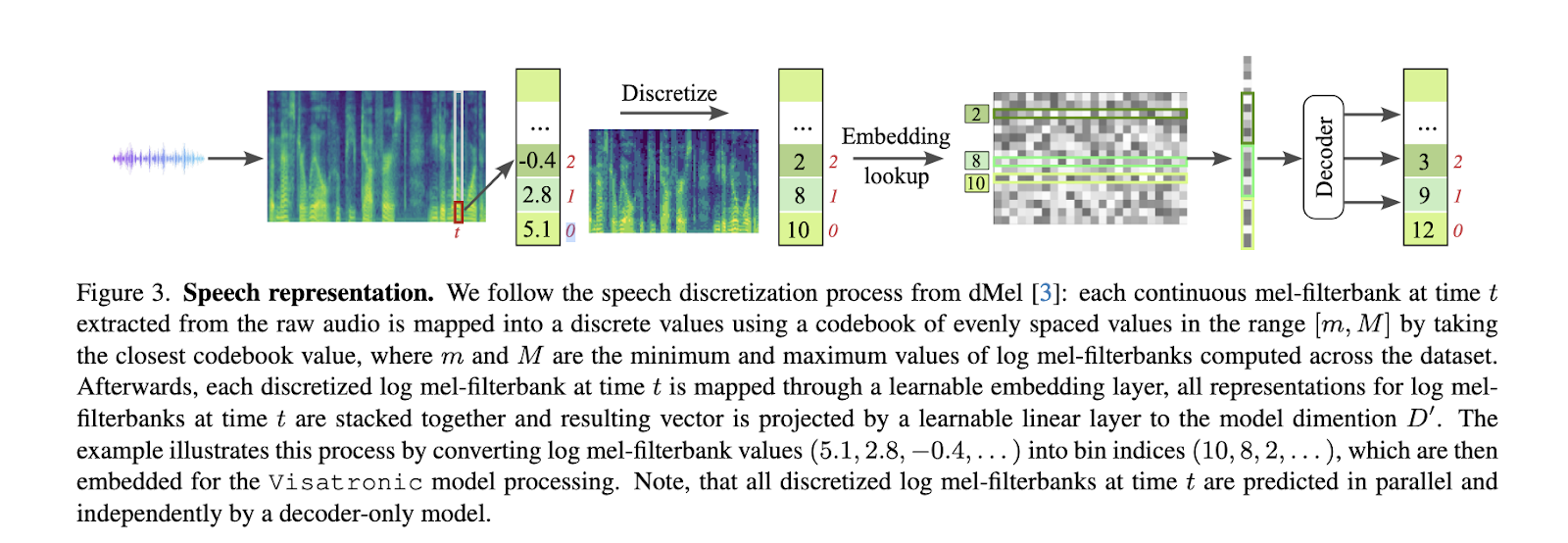
A abordagem Visatronic baseia-se na incorporação e segmentação de insumos multimodais. O autoencoder variacional quantizado por vetor (VQ-VAE) codifica a entrada de vídeo em tokens discretos, enquanto a fala é reduzida a representações de espectrograma mel usando dMel, um método de segmentação simples. A entrada de texto recebe um token em nível de caractere, o que melhora a generalização ao capturar as sutilezas da linguagem. Esses métodos são combinados no projeto de um único transformador que permite a interação de todas as entradas por meio de métodos de autoatenuação. O modelo utiliza técnicas de alinhamento temporal para sincronizar fluxos de dados em diferentes resoluções, como vídeo a 25 quadros por segundo e amostras de fala coletadas em intervalos de 25 ms. Além disso, o sistema inclui incorporação de posição relativa para manter a consistência temporal em todas as entradas. A perda de entropia cruzada é usada exclusivamente para representações de fala durante o treinamento, o que garante desenvolvimento robusto e aprendizagem intermodal.
A Visatronic demonstrou melhorias significativas no desempenho em conjuntos de dados desafiadores. No conjunto de dados VoxCeleb2, que inclui contextos diversos e barulhentos, o modelo alcançou uma taxa de erro de palavras (WER) de 12,2%, superando os métodos anteriores. Também alcançou um WER de 4,5% no conjunto de dados LRS3 sem treinamento adicional, indicando fortes capacidades de generalização. Em contraste, os sistemas TTS tradicionais alcançaram WERs elevados e não tinham a precisão de sincronização necessária para tarefas complexas. Os testes subjetivos confirmaram ainda mais essas descobertas, com a Visatronic alcançando maior inteligibilidade, naturalidade e sincronização do que os benchmarks. O VTTS (vídeo-texto-fala) de ordem diferente alcançou uma pontuação média (MOS) de 3,48 para inteligibilidade e 3,20 para naturalidade, os modelos de melhor desempenho treinados apenas na entrada de texto.
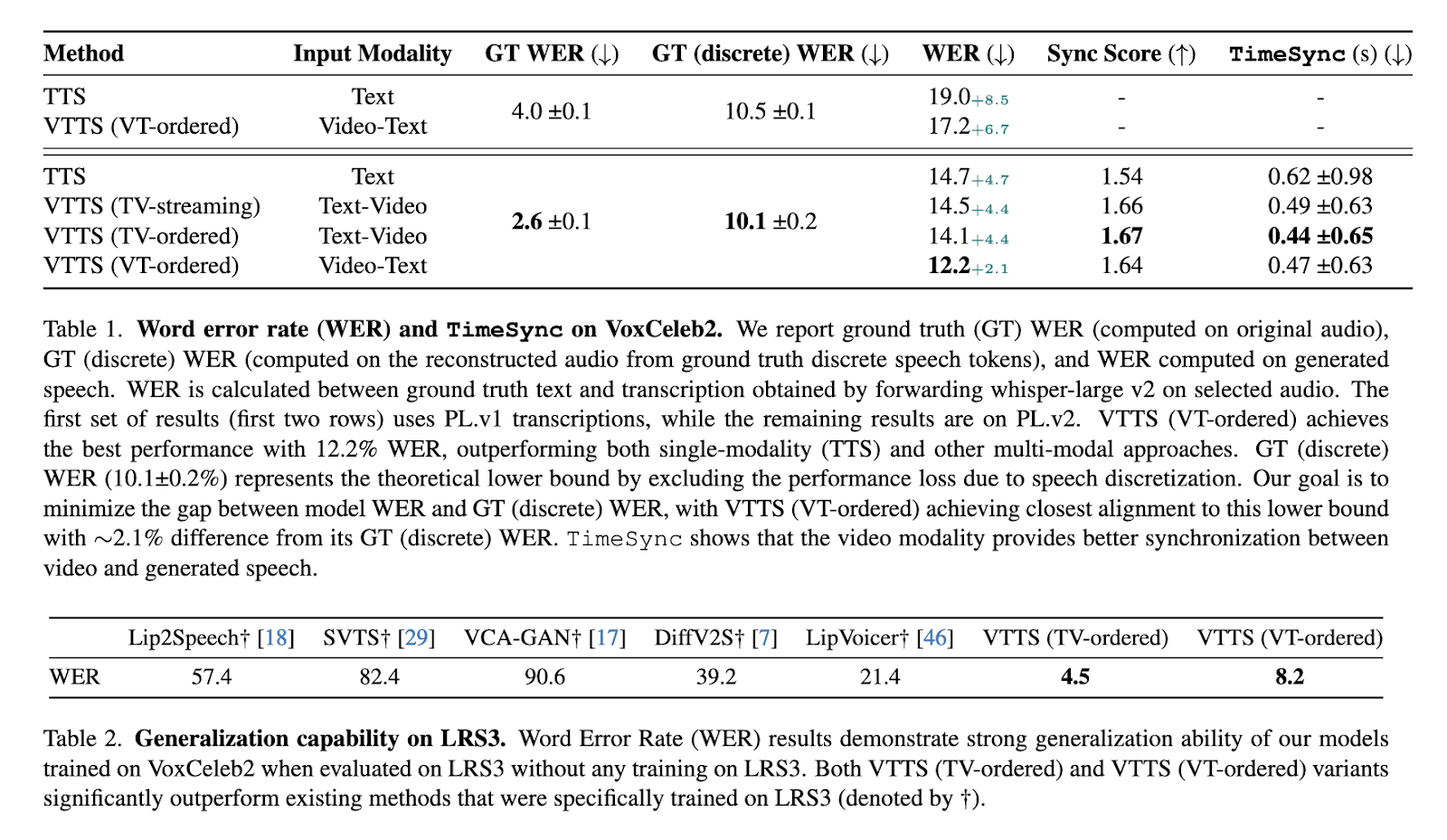
A integração de vídeo não só melhora a produção de conteúdo, mas também reduz o tempo de treinamento. Por exemplo, a variante Visatronic alcançou um desempenho comparável ou melhor após dois milhões de etapas de formação, em comparação com três milhões para modelos apenas de texto. Esta eficiência destaca o valor complementar da combinação de métodos, uma vez que o texto contribui para a precisão contextual, enquanto o vídeo melhora a coerência contextual e temporal.
Concluindo, a Visatronic representa um avanço na integração de voz multimodal ao abordar importantes desafios ambientais e de sincronização. Sua estrutura de transformador integrada combina facilmente dados de vídeo, texto e áudio, proporcionando desempenho superior em todas as situações diferentes. Esta inovação, desenvolvida por investigadores da Apple e da Universidade de Guelph, estabelece um novo padrão para aplicações que vão desde a gravação de vídeo até à tecnologia de comunicação acessível, abrindo caminho para futuros desenvolvimentos nesta área.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
🎙️ 🚨 'Avaliação de vulnerabilidade de um grande modelo de linguagem: uma análise comparativa dos métodos da Cruz Vermelha' Leia o relatório completo (Promovido)
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
🧵🧵 [Download] Avaliação do relatório do modelo de risco linguístico principal (ampliado)


