
Os Modelos de Linguagem em Grande Escala (LLMs) revolucionaram a inteligência artificial, influenciando vários campos da ciência e da engenharia. A arquitetura Transformer, originalmente desenvolvida para tradução automática, tornou-se a base para modelos GPT, avançando enormemente no campo. No entanto, os LLMs atuais enfrentam desafios no seu método de treinamento, que se concentra principalmente na previsão do próximo token com base no contexto anterior, mantendo a causalidade. Este método direto tem sido aplicado em diferentes domínios, incluindo robótica, sequenciamento de proteínas, processamento de áudio e análise de vídeo. À medida que os LLM continuam a crescer em escala, atingindo centenas de milhares de milhões a milhares de milhões de parâmetros, surgem preocupações sobre a acessibilidade da investigação em IA, com alguns temendo que esta possa acabar confinada a investigadores industriais. O principal problema que os investigadores enfrentam é melhorar as capacidades dos modelos para corresponderem aos de estruturas maiores ou para alcançar um desempenho comparável com menos etapas de formação, abordando em última análise os desafios de escala e eficiência no desenvolvimento de LLM.
Os pesquisadores exploraram várias maneiras de melhorar o desempenho do LLM manipulando a incorporação central. Outra abordagem envolve o uso de filtros ajustados manualmente na Transformada Discreta de Cosseno do espaço latente para tarefas como reconhecimento de entidade nomeada e modelagem de tópicos em estruturas não causais, como BERT. No entanto, este método, que modifica todo o comprimento do contexto, não é adequado para tarefas de correspondência de linguagem causal.
Duas técnicas notáveis, FNet e WavSPA, tentaram melhorar as restrições de atenção em estruturas semelhantes ao BERT. A FNet substituiu o método de atenção de bloco 2-D FFT, mas esta operação não foi a causa, considerando tokens futuros. WavSPA calcula a atenção no espaço wavelet, usando transformações multi-resolução para capturar dependências de longo prazo. No entanto, também depende de uma função não causal, verificando a duração de toda a sequência.
Esses métodos existentes, embora inovadores, enfrentam limitações em sua aplicabilidade apenas ao projeto de um decodificador causal como o GPT. Eles tendem a violar suposições de causalidade importantes em tarefas subsequentes de previsão de tokens, tornando-os inadequados para adaptação direta a modelos como o GPT. O desafio continua a ser desenvolver técnicas que possam melhorar o desempenho do modelo, preservando ao mesmo tempo a natureza causal da arquitetura do decodificador.
Pesquisadores de Stanford propõem o primeiro evento indutor de ondas em LLMs, WaveletGPTpara melhorar os LLMs incorporando wavelets em seu design. Este método, considerado o primeiro desse tipo, adiciona filtros multiescala à incorporação média de camadas decodificadoras do Transformer usando wavelets Haar. A inovação permite que a projeção de cada token obtenha representações multidimensionais entre camadas, em vez de depender de uma representação de resolução fixa.
Notavelmente, este método acelera o pré-treinamento de LLMs baseados em transformadores em 40-60% sem adicionar parâmetros adicionais, um avanço significativo dado o uso generalizado de arquiteturas baseadas em Transformer Decoder em uma variedade de métodos. Essa abordagem também mostra uma melhoria significativa no desempenho com o mesmo número de etapas de treinamento, em comparação com a adição de camadas ou menos parâmetros.
A tarefa baseada em wavelet mostra melhoria de desempenho em três modalidades diferentes: linguagem (texto-8), áudio bruto (YoutubeMix) e metáfora musical (MAESTRO), destacando suas interações multimodais em conjuntos de dados estruturados. Além disso, ao tornar os kernels wavelet legíveis, adicionando apenas uma pequena fração dos parâmetros, o modelo obtém um aumento significativo no desempenho, permitindo-lhe aprender filtros multidimensionais na incorporação média a partir do zero.
O método proposto integra wavelets em modelos de linguagem principal baseados em transformadores, preservando a suposição de causalidade. Este método pode ser usado em diversas arquiteturas, incluindo configurações fixas. O processo se concentra em alterar a incorporação média de cada camada do decodificador.
Para um determinado sinal xl(i), que representa a saída da l-ésima camada decodificadora ao longo da i-ésima coordenada, o método usa uma transformada wavelet discreta. Com N+1 camadas e tamanho de incorporação E, este processo gera sinais N*E de comprimento L (comprimento do conteúdo) a partir da incorporação média entre os blocos decodificadores.
A transformada wavelet, especialmente usando wavelets Haar, envolve a passagem do sinal através de filtros com diferentes resoluções. As ondas de Haar são funções quadradas derivadas das ondas-mãe por meio de funções de escala e transformação. Este processo cria formas de onda bebês que capturam informações de sinal em momentos diferentes.
A transformação wavelet direta é realizada passando o sinal por filtros passa-baixa e passa-alta, seguido de redução da resolução. Para ondas de Haar, isso é igual à função média e à variância. O processo produz coeficientes de aproximação (yaapprox) e coeficientes de detalhe (ydetail) usando convolução e redução da resolução. Esta operação é realizada iterativamente nos coeficientes de aproximação para obter representações de múltiplas dimensões, permitindo a aproximação de cada token subsequente para alcançar esta representação de múltiplas soluções da incorporação central.
Esta abordagem combina wavelets e incorporações LLM, concentrando-se em coeficientes de aproximação, que capturam dados estruturados em vários níveis. No texto, essa estrutura varia de letras a modelos de assuntos, enquanto na música figurativa varia de notas a peças inteiras. O método de usar wavelets de Haar simplifica o processo de operação de média móvel. Para manter a causalidade e o comprimento da sequência original, o método calcula a média móvel das amostras anteriores dentro de um determinado comprimento do kernel para cada tamanho de token. Isso cria representações em várias escalas do sinal de entrada, permitindo que o modelo capture informações em diferentes resoluções em escalas de incorporação sem alterar a estrutura média de incorporação do Transformer.

O método apresenta uma forma única de integrar representações multidimensionais sem aumentar a complexidade da arquitetura. Em vez de somar todos os níveis de sinais de medição para cada dimensão de incorporação, dividiu o nível pelo próprio índice da dimensão de incorporação. Este método mantém metade dos sinais de incorporação central inalterados, enquanto processa a outra metade com base em seu índice. Na parte processada, uma função de mapeamento simples f determina o tamanho do kernel de cada link, das medidas de nível I a IX. O sinal modulado xnl(i) é calculado usando um filtro de média móvel com tamanho de kernel determinado por f(i). Esta funcionalidade preserva as suposições de causalidade importantes para os LLMs e evita o vazamento de informações em tokens futuros. A estratégia cria uma estrutura onde diferentes dimensões de incorporação se movem em taxas diferentes, permitindo que o modelo capture informações em diferentes escalas. Essa estrutura multiescala permite que o método de atenção use recursos multiescala em camadas e tokens, o que tem o potencial de melhorar a capacidade do modelo de capturar padrões complexos nos dados.
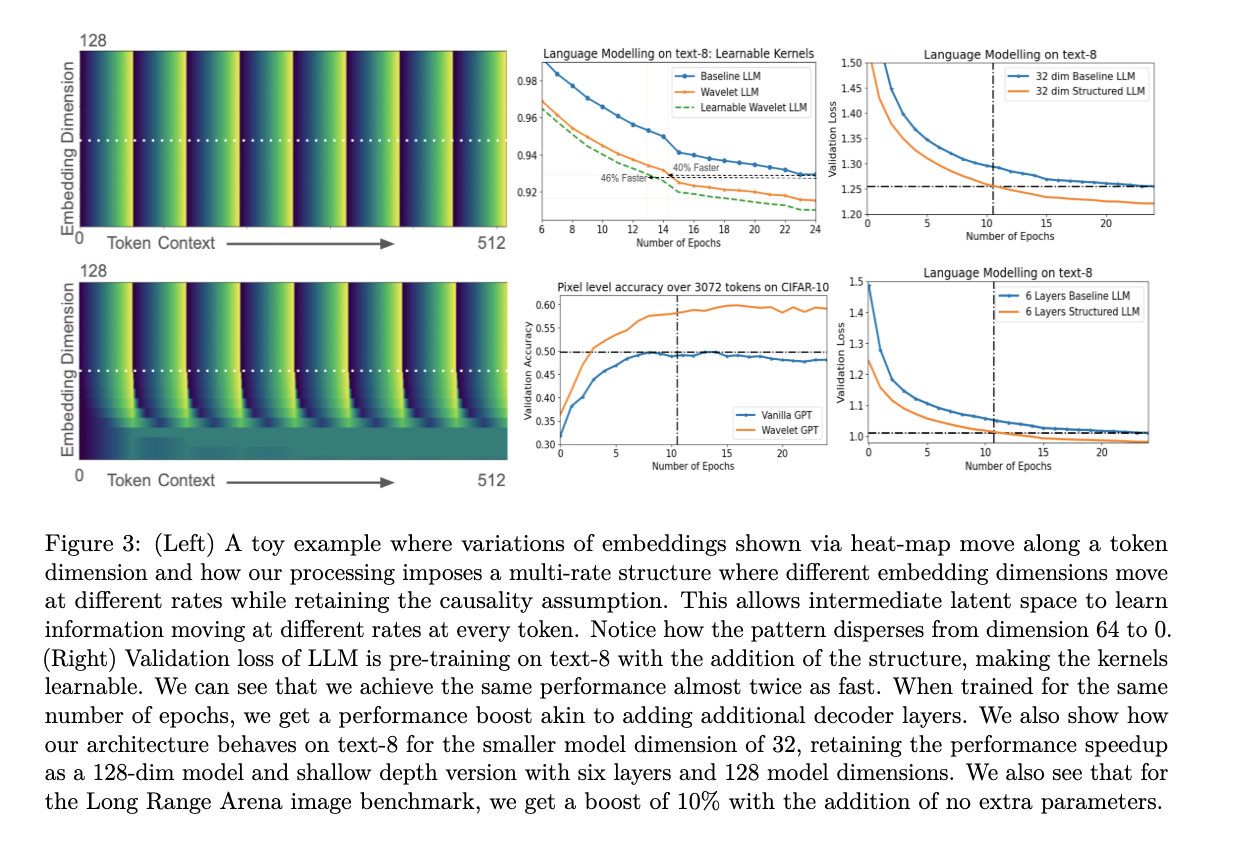
Os resultados em todos os três modos – texto, música simbólica e ondas sonoras – mostram uma melhoria significativa no desempenho com média baseada em frequência. Em linguagem natural, a redução na perda de validação é equivalente à expansão de um modelo de 16 camadas para um modelo de 64 camadas em um conjunto de dados de 8 textos. As estruturas modificadas recuperam a mesma perda quase duas vezes mais rápido que as originais de acordo com as etapas do treinamento. Esta aceleração é ainda mais pronunciada no áudio bruto, o que pode ser devido à natureza estática dos sinais de áudio em escalas de tempo curtas. A integração da configuração da forma de onda LLM bruta é quase duas vezes mais rápida em comparação com a figura 8 e a música analógica.
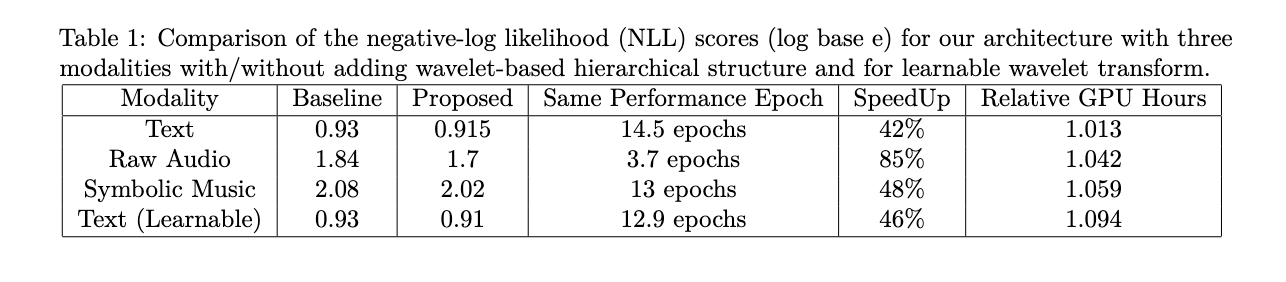
Em comparação com tempos de execução de clock absolutos, a arquitetura modificada mostra melhor desempenho de computação em configurações de leitura e não leitura. O tempo necessário para completar um período relativo à estrutura base é relatado. O método parece ser computacionalmente barato, uma vez que a tarefa principal envolve a simples estimativa de wavelets de Haar ou o aprendizado de um único filtro de kernel dinâmico com comprimento de kernel variável para todas as dimensões de incorporação. Esta eficiência, combinada com a melhoria do desempenho, sublinha a eficiência do método baseado em ondas na melhoria do treinamento LLM em todos os diferentes métodos, sem sobrecarga computacional significativa.
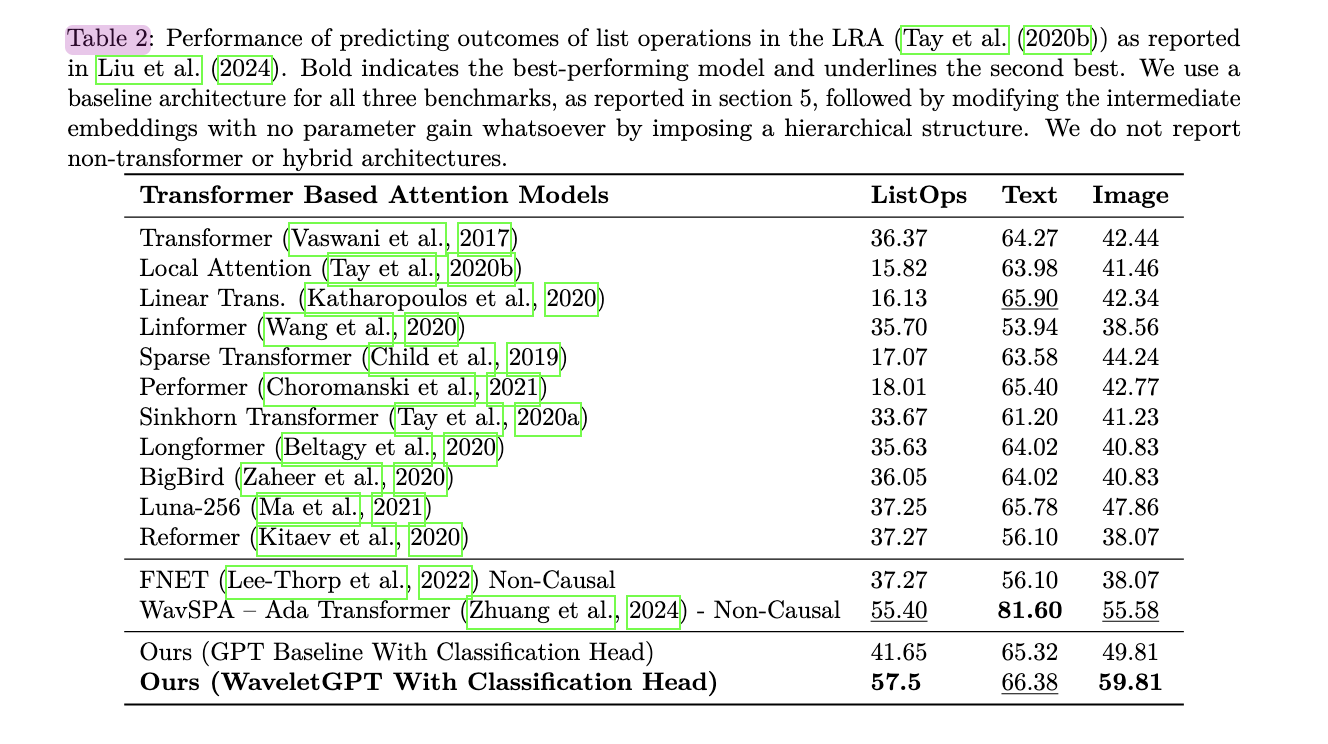
Este estudo apresenta o WaveletGPT, introduzindo a integração wavelet, um método básico de processamento de sinais, no pré-treinamento de um modelo de linguagem grande. Ao introduzir uma estrutura multidimensional na incorporação central, a velocidade de desempenho é melhorada em 40-60% sem adicionar quaisquer parâmetros. Esta técnica funciona em três formatos diferentes: texto bruto, música simbólica e áudio bruto. Quando treinado pelo mesmo período de tempo, mostra uma melhoria significativa no desempenho. Possíveis direções futuras incluem a combinação de conceitos avançados de ondas e processamento de sinais de multi-resolução para desenvolver modelos de linguagem em larga escala.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit.
Convidamos startups, empresas e institutos de pesquisa que trabalham em modelos de microlinguagem para participar deste próximo projeto Revista/Relatório 'Modelos de Linguagem Pequena' Marketchpost.com. Esta revista/relatório será lançada no final de outubro/início de novembro de 2024. Clique aqui para agendar uma chamada!
Asjad é consultor estagiário na Marktechpost. Ele está cursando B.Tech em engenharia mecânica no Instituto Indiano de Tecnologia, Kharagpur. Asjad é um entusiasta do aprendizado de máquina e do aprendizado profundo que pesquisa regularmente a aplicação do aprendizado de máquina na área da saúde.


: um método não supervisionado para modelos de pré-treinamento de percepção-linguagem-ação (VLA) sem rótulos de ação de robô de verdade básica")